1 Motivation & Key Idea
1.1 Instruction window in OoO processor
Out-of-Order (OoO) execution can tolerate long-latency cache misses better than in-order execution by scheduling subsequent instructions that are independent of the miss. A long-latency operation blocks the instruction window, even if subsequent instructions have completed execution. It is because the insturction window should ensure in-order retirement. If the latency of blocking operation is long enough and size of the instruction window is small, then the instruction window can't progress to the next fetch, making it the main bottleneck of OoO processor.
1.2 Key idea and insight behind runahead execution
Runahead execution removes the blocking instruction from the instruction window, enabling the fetching of new instructions and the execution of those that are independent of it. While runahead execution yields bogus results, its performance benefit comes from fetching subsequent instructions to fetch engine's cache and executing the independent load/store operations that miss caches. These executions serve as accurate prefetching because cache misses in runahead mode can be servied in parallel with miss to main memory.
2 Implement Details
2.1 Two RAT (Register Alias Table) in OoO processor
The Frontend RAT maintains speculative mapping from the architectural register name in incoming instructions to the physical(=micro-architectural) register name, a process known as register renaming. The Retirement RAT contains pointers to physical registers that store commited architectural values. When an instruction commits, the mapping in the Retirement RAT changes, not actually moving results from one physical location to another.

2.2 Entering runahead mode
The processor enters runahead mode when a memory operation misses in the second-level cache and when this instruction becomes the head of the instruction window, which blocks the instruction window. As commited results are bogus in runahead mode, the processor should checkpoint the architectural registers which are pointed to by Retirement RAT to correctly recover the architectural state when runahead mode terminates. (New HW component 'Checkpointed Architectural RF' in Figure 2) All instructions in the instruction windows and in-flight are marked as 'runahead operations' and are treated differently by the microarchitecture. No additional cycles are spent due to Checkpointed Architectural RF because the processor can update individual architectural register values when each instruction retires.
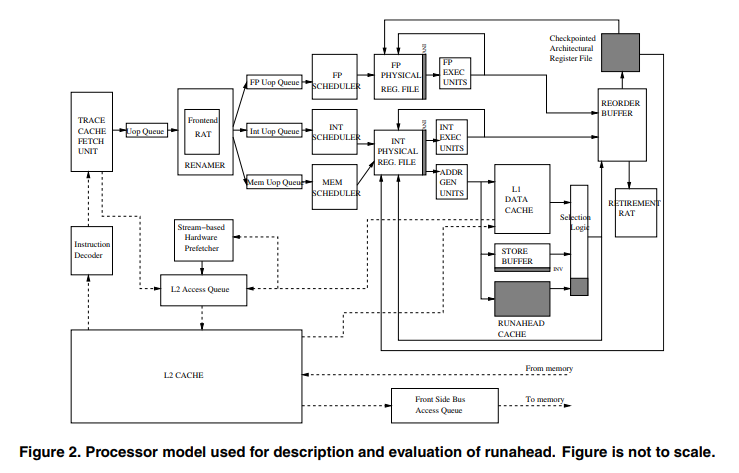
2.3 Execution in runahead mode
(1) Invalid bits
Each physical register has an invalid (INV) bit, which is set if it has a bogus value. Initially, the INV value is produced by the instruction that triggers runahead mode. For a load opreration, the destination register is marked as INV, and for a store operation, a new line is allocated in the runahead cache. After that, any instruction that sources a physical register with the INV bit set is treated as invalid.
INV bits are used to prevent bogus prefetches and branch resolution with bogus value, because they can pollute the trained table.
(2) Runahead store operations and runahead cache
When both a store and its dependent load instructions are in the instruction window, forwarding is done using the existing store buffer. However, when a load instruction depends on a store instruction that has already pseudo-retired and thus is no longer in the store buffer, another forwarding mechanism is required. The paper proposes a runahead cache which holds the results and INV status of pseudo-retired store instructions.
When a store instruction completes its execution, the data and INV bit are written to the entry in the store buffer. When it pseudo-retires and exits the instruction window, the entry is written to the runahead cache if its address is valid. If the address of the store instruction is invalid, it is simply treated as a NOP.
(3) Runahead load operations
When a valid load instruction executes, 3 structures are accessed in parallel: the data cache, the runahead cache, and the store buffer. A load hits in the runahead cache or the store buffer only if the corresponding entry is valid. If it hits in the data cache, the value is considered valid, even if there is a slight possiblity that the value is actually invalid. If the load misses in the L2 cache, it just marks its destination register as INV and pseudo-retires. The request is sent to memory like a normal load request.
(4) Instruction pseudo-retirement
If the instruction at the head of the instruction window is invalid, it is moved out of the window immediately. (It is because its result will be also invalid, thus no need to wait for its execution) If it is valid, the processor waits for its execution, just as in normal mode. The result is then written to the physical register file.
2.4 Exiting runahead mode
The processor exits runahead mode when the blocking load request, which caused runahead mode, returns from memory. The values of the Checkpointed Architectural RF are copied to the corresponding physical register, and the mapping from architectural to physical register is also copied to the Retirement RAT.
3 Results
As shown in Figure 3, runahead is a more effective prefetching scheme than a stream-based HW prefetcher.

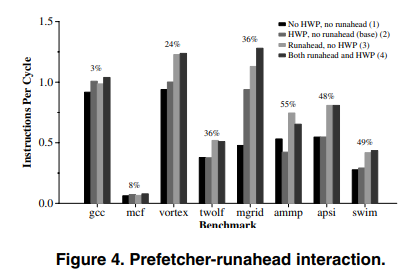
3.1 Runahead and HW data prefetcher
If runahead execution is implemented with a hardware data prefetcher, it additionaly trains the prefetcher table and initiates new prefetch streams. With a high accuracy HW prefetcher, prefetches generated by runahead instructions are inherently accurate, as these instructions are likely to be on the program path.
However, as shown in Figure 4, for workloads (twolf, ammp) where the prefetcher provides less accuracy, runahead execution can degrade performance.
3.2 Runahead and instruction windows
Runahead execution shows comparable performances to that of a larger instruction window. As shown in Figure 5, runahead outperforms a double-sized instruction window without runahead execution for many workloads.
However, runahead execution shows poor performance for workloads (S95) that have many long-latency FP operations, as runahead execution does not reduce the latency of FP operation itself.

'Paper Reading > CPU Microarchitecture' 카테고리의 다른 글
| [ISCA '21] A. Naithani, Vector Runahead (0) | 2023.12.28 |
|---|---|
| [Review] M. Jalili, Reducing Load Latency with Cache Level Prediction, HPCA 2022 (0) | 2023.09.11 |
| [HPCA '22] M. Jalili, Reducing Load Latency with Cache Level Prediction (0) | 2023.09.07 |
| [ISCA '22] (2/2) S. Shukla, Register File Prefetching (0) | 2023.07.20 |
| [ISCA '22] (1/2) S. Shukla, Register File Prefetching (0) | 2023.07.17 |



