3. Register File Prefetch (RFP)
RFP의 목표는 load 명령어의 data를 prefetch 함으로써 L1 캐시 latency를 줄이는 것이다. 예측된 주소를 이용해 prefetch를 하고, load 명령어가 실행되면서 예측된 주소가 실제 load 주소와 일치하는지를 검사한다. 예측이 성공한 경우 dependent 명령어에게 바로 값을 공급하며 캐시 접근을 우회할 수 있다. 예측이 실패했다면 일반적인 OoO pipeline과 같이 동작한다.
(1) Timeliness
먼저, 기존 방법에서와 같이 명령어 fetch와 동시에 prefetch를 시작할 수 있다. 그러나, 이 경우 prefetch의 correctness를 보장하기 위해 모든 in-flight store 명령어를 검사해야 한다. 또한 RF는 캐시와 달리 tag가 없기 때문에 prefetch된 데이터를 저장할 physical register를 할당해야 한다.
이러한 문제점이 있기 때문에, 본 논문의 RFP는 rename stage 직후에 prefetch를 시작한다. 그러면 load 명령어에 할당된 RF entry를 재사용할 수 있다.
(추측) 모든 in-flight store 명령어를 추적해야 하는 문제도 해결할 수 있는데, 그 이유는 rename stage 직후에는 이미 dependency check가 완료되었으므로, dependent한 store 명령어가 존재한다면 완료된 이후에 prefetch request를 wakeup 시켜줄 것이다.
(2) Bandwidth
기존의 AP 방식은 두 번의 캐시 접근을 하는데, 예측된 주소의 데이터를 가져올 때와 validation check 이렇게 2번이다. 그런데 RFP는 만약 예측 주소가 일치하는 경우 RF의 데이터가 L1 캐시와 up-to-date 함을 보장할 수 있기 때문에, L1 캐시 BW를 절약할 수 있다.
(3) Accuracy
잘못된 예측을 하면 올바른 데이터를 가져오기 위해 다시 L1 캐시 접근을 해야 하며, 이것은 L1 캐시 BW를 2번이나 사용하는 것이기에 정확도를 높여 잘못된 예측을 최소화하는 것이 요구된다. 그러나 잘못된 예측에 대한 penalty가 AP에 비해서는 적은데, AP의 경우 pipeline full flush가 요구되었기 때문이다.
3.1 RFP Prefetcher
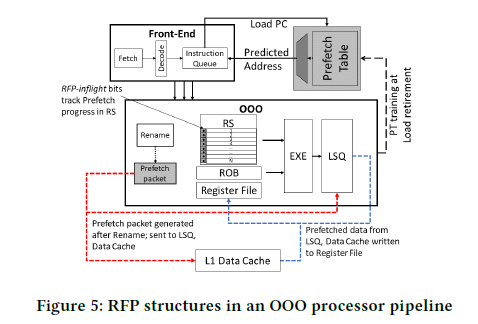
Figure 5는 OoO pipeline 프로세서의 RFP 구현의 구조이다.
우선, Prefetch Table (PT)로부터 load 명령어의 주소 예측 값을 얻는데, PC 값을 index로 하여 PT의 값을 읽는다. PT의 각 entry는 tag, utility, confidence, stride, inflight counter, 64-bit virtual address로 구성된다. Tag는 캐시에서와 같이 인덱싱하는 PC 값과 entry가 일치하는지를 나타낸다. Utility, confidence는 prefetch 될 수 있는 가능성을 의미하며, stride가 반복된다면 증가하고, 계속 변하면 감소하는 식이다. Utility가 낮으면 entry는 evict 될 수 있다. Inflight counter는 아직 commit 되지 않고 inflight 상태에 있는 load 명령어의 instance의 수를 나타낸다. Prefetch할 주소는 base address와 stride, inflight counter를 모두 고려하여 얻게 된다.
본 논문의 prefetcher는 기본적으로 PC 정보를 활용하는데, 다른 선행 연구에서는 context-based prefetcher 아이디어가 제안된 바 있다. 본 연구에서도 context-based도 실험해보았지만, 성능 향상이 제한적이었다.
3.2 Launching Register File Prefetch
만약 load 명령어의 PC 값으로 PT를 참조했을 때 해당 entry가 RFP-eligible을 나타낸다면, prefetch packet이 LSQ(load store queue)와 L1 캐시에 전송된다. 이 packet에는 참조할 virtual address와 load 명령어의 physical destination register id (이하 prfid) 정보가 담겨 있다. prfid는 register renaming 이후에 결정되기 때문에, prefetch request는 regiseter renaming 직후에 이루어진다. Request가 LSQ에 들어갔을 때는 regular load request에 비해 낮은 우선 순위를 갖게 된다. 만약 L1 캐시 port에 대한 접근을 얻었다면, 데이터를 L1 캐시로부터 가져와 명시된 prfid에 데이터를 기록한다.
3.3 RFP Pipeline
(1) OoO pipeline 프로세서의 핵심 개념
여기서는 OoO pipeline 프로세서에서 fetch, decode 이후에 명령어가 스케줄링 및 실행되는 방식을 살펴본다. OoO pipeline에 대해 알아야 할 내용들이 잘 정리되어 있다.
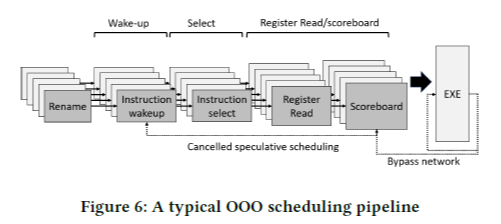
Register renaming 단계에서 logical reg를 physical reg로 mapping 시키고, 명령어 간 register dependency를 검사한다. 이 때, Reservation Station (RS 또는 Instruction Queue, IQ)에 명령어 간 dependency를 기록한다. 각 명령어에 대해 operand가 다른 명령어와 dependency가 있는지를 1-bit on/off로 표시해둔다.
Schedule 단계에서 실행 준비가 완료된 명령어를 골라 register file read를 한다. 명령어가 스케줄링 될 때, 이 명령어에 대해 dependency를 갖는 younger 명령어들의 dependency bit을 clear 한다. 만약 dependency vector의 모든 bit이 0이면, 해당 명령어는 wake up 신호를 받아 스케줄링 되기를 기다린다. 그러면 이 명령어가 다시 해당 명령어에 대해 dependency를 갖는 명령어들의 dependency bit을 clear 하기를 반복하는 식이다. 이런 식으로 명령어들이 back-to-back speculative 한 방식으로 스케줄링 된다.
그러나 항상 speculative 한 스케줄링이 성공하는 것은 아닌데, 스케줄링된 명령어가 execution이 1-cycle 안에 끝나지 않을 수 있기 때문이다. 여기서 Scoreboard가 잘못 스케줄링된 명령어를 re-issue 하는 역할을 한다.
명령어 간 dependency도 명령어의 종류에 따라 다른데, 아래의 Figure 7, 8은 각각 ADD 명령어가 ADD, LOAD 명령어에 대해 dependency가 있는 상황을 보여준다. ADD 명령어는 1 cycle 안에 실행이 완료되므로 back-to-back execution이 가능하지만, LOAD 명령어는 5 cycle이 걸리기 때문에 stall 하게 된다. 이 때 캐시의 hit/miss에 따라 wakeup 시간이 달라지며, speculative하게 5 cycle 뒤에 wakeup 하였더라도 만약 캐시 miss가 났다면 wakeup이 취소되고 다시 스케줄링 되어야 한다.


(2) OoO pipeline of RFP
load 명령어의 RS entry에는 RFP flight 1-bit이 추가되며, 이것은 RFP가 prefetch를 시작했음을 전달하는 신호이다. 디폴트는 RFP flight이 0인 상황이며, 이 때는 위에서 언급한 것과 같이 5 cycle 뒤에 wakeup 된다. 그러나 RFP flight bit이 1인 경우, RFP completion time 만큼 기다린 뒤 wakeup 한다. 따라서 RFP flight bit을 1로 설정하는 타이밍이 중요한데, prefetch request 날리자마자 설정하면 안 되고 LSQ의 arbitration에서 prefetch 요청을 캐시로 전송하기로 결정되기까지 기다렸다가 1로 설정해야 한다.
Figure 9와 같이 load 명령어가 wakeup 되면 일단 RFP inflight bit을 확인한다. 만약 set인 상황이면 dependent한 명령어를 바로 wakeup 시켜 실행을 이어갈 수 있다. 아래 그림에서 보는 것과 같이 load latency를 아예 없애는 효과를 얻을 수 있다.

물론 prefetch request가 바로 L1 캐시에 대한 접근 권한을 얻지 못해 load 명령어가 wakeup 된 이후에 RFP flight bit이 설정될 수 있다. 이 때는 load latency의 일부를 아끼는 효과를 얻을 수 있다.
load 명령어의 주소가 실제로 계산되었을 때 prefetch 주소와의 비교를 통해 예측의 성공 여부를 판단한다. 위의 시나리오는 예측이 성공했을 때이고, 만약 실패했다면 speculative하게 스케줄된 dependent 명령어를 취소하고 캐시에서 데이터가 도착할 때까지 기다렸다가 re-issue 해야 한다. 여기서 명령어 취소 및 re-issue는 기존 pipeline에 존재하는 datapath이므로 새롭게 추가되는 것이 아니다.
4. Evaluation Methodology
Intel의 TigerLake 프로세서를 시뮬레이션 한다. 명령어의 dynamic scheduling이 이루어지는 x86 코어이다. 이것을 본 연구의 baseline으로 한다.
성능 측정에 사용되는 프로그램은 65개의 single threaded 어플리케이션이며, 이것은 잘 알려져있는 벤치마크이다. 성능은 IPC (Instruction Per Cycle)로 측정하며, 평균 IPC는 geometric mean으로 계산한다.
5. Simulation Results
RFP에서 load 주소에 대한 예측 값을 저장해두는 PT는 1,000개의 entry를 갖는 것으로 가정하며, 64-bit의 virtual address가 저장되어 있다.
5.1 Performance and Coverage of RFP
아래의 Figure 10은 baseline에 비해 RFP의 speedup과 coverage를 워크로드의 카테고리별로, 그리고 마지막에는 mean 값을 나타낸 것이다. 먼저, speedup을 보면 이론적으로 달성 가능한 RFP의 최대 speedup이 9%인데, 실제 실험 결과 3.1%의 speedup을 얻었다. 다음으로 전체 load 명령어의 43.4%에 대해 prefetch를 성공할 수 있었다.
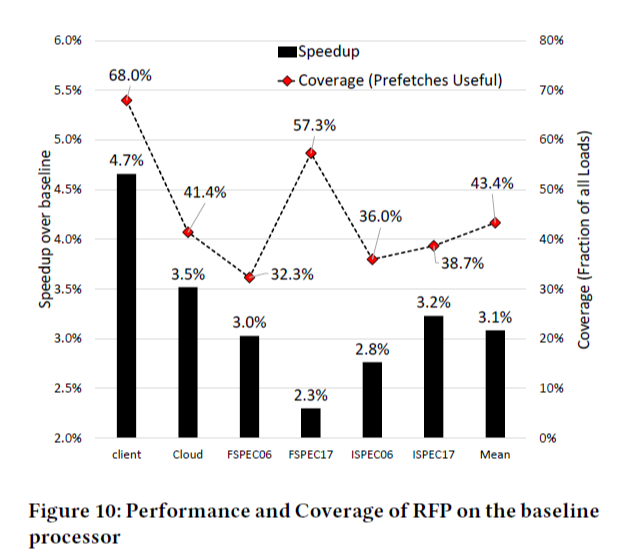

Figure 11은 워크로드 단위로 IPC와 coverage를 line graph로 나타낸 것이다. RFP의 coverage가 높을수록 IPC가 높아지나, coverage가 높음에도 IPC gain이 거의 없는 것은 성능의 bottleneck이 다른 부분이기 때문이다.
5.2 Timeliness and Effectiveness of RFP

Prefetches Injected는 prefetch packet이 만들어진 load 명령어의 비율, Prefetch Executed는 실제로 prefetch되어 데이터가 RF에 저장된 비율이다. 이 두 비율이 다른 이유는 prefetch packet이 만들어지더라도 L1 캐시 BW가 available 할 때만 prefetch가 이루어지기 때문이다. 정상적인 load 명령어가 prefetch에 비해 우선 순위를 갖기 때문에, 정상적인 load 명령어가 먼저 실행되면 prefetch는 당연히 실행되지 않는다.
Prefetches Useful이란 prefetch가 실제로 실행되었고, 예측 주소가 맞아서 prefetch를 통해 load 명령어의 latency를 줄인 비율이다. 평균적으로 약 5%의 load 명령어가 prefetch는 되었으나 예측이 틀려서 re-issue가 요구되는데, 이 때 L1 캐시 접근은 추가적으로 1회 하게 되나 load latency가 baseline에 비해 나빠지지는 않는다. 왜냐하면 pipeline flush가 일어나지는 않기 때문이다.



