1. Introduction
현대의 OoO (Out-of-Order) 프로세서의 성능을 제한하는 주요 요인은 load 명령어의 latency이며, 이를 memory wall이라고도 부른다. 현대의 프로세서는 Figure 1과 같이 multi-level 캐시 계층 구조를 갖고 있다. Latency를 보면 LLC (Last-level cache)에 비해 메인 메모리 DRAM에 접근하는 latency가 훨씬 큰데, 이로 인한 bottleneck을 해결하기 위해 그동안 메인 메모리로부터의 효율적인 prefetching과 캐시 management에 대한 많은 연구들이 이루어져 왔다.
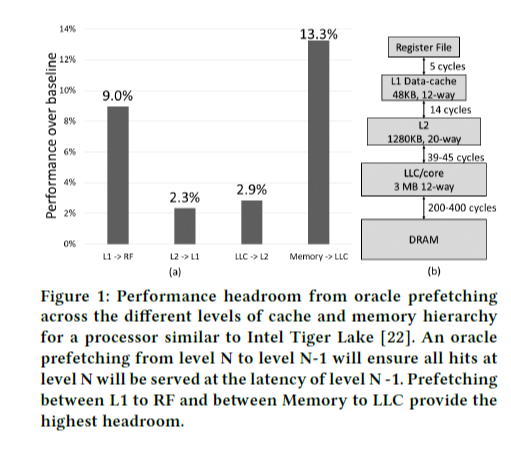

Figure 1은 각 캐시 계층의 performance headroom을 나타내는데, 이것은 각 계층 사이의 prefetching이 가장 optimal하게 일어났을 때 어느 정도의 성능 향상 가능성이 있는지를 의미한다. 역시 LLC와 메인 메모리 사이의 prefetching이 성능 향상에 많이 기여할 수 있는데, 이는 현재 메인 메모리로부터의 prefetching이 활발하게 연구되고 있는 이유이다. 여기서 레지스터 파일 (Register File, RF)과 L1 캐시 사이의 prefetching이 약 9%의 성능 향상을 이룰 가능성이 있다는 사실도 주목할 만하다. L1 캐시의 접근 latency가 LLC <-> 메인 메모리에 비해 훨씬 적음에도 불구하고 이것이 성능 향상 potential에 있어서 이와 비교될 만한 수치를 갖는 이유는, Figure 2에서 보듯이 대부분의 (92.8%) load request에 대해 L1 캐시 hit이 일어나므로 RF <-> L1 캐시 간의 transaction의 비율이 높기 때문에 그러하다. 이렇듯, memory wall을 극복하기 위해서 LLC와 메인 메모리 사이의 prefetching에 더해 다른 캐시 계층 구조와 RF 사이의 prefetching도 중요하며, 본 논문에서는 후자에 초점을 맞춘다.
2. Background
여기서는 기존의 기법들이 L1 캐시 latency를 효과적으로 줄이지 못한 이유를 논의하고, 일반적인 OoO scheduling 파이프라인의 동작을 설명한다.
2.1 Value Prediction (VP)
Value prediction (VP)은 어떤 명령어에 대해 이전 결과를 기억해두었다가 다음에 그 명령어를 실행할 때 해당 명령어의 결과 값을 예측하는 방식이다. 이것이 가능한 이유는 명령어의 locality 때문인데, 예를 들어 load 명령어를 통해 어떤 주소에 저장된 값을 여러 번 참조하는 경우에는 같은 값을 다시 가져올 가능성이 높을 것이다. 그러나 모든 명령어가 locality를 갖지는 않기 때문에, saturating counter를 두어 해당 명령어가 어느 정도 예측 가능한지를 추적하여 예측 가능하다고 판단한 경우에만 value prediction을 한다. 명령어를 commit 하기 전에 예측 결과를 확인해야 하고, 만약 예측이 틀렸다면 다시 실행해야 한다.
Value prediction을 위해 2개의 새로운 table을 도입하며, saturating counter 정보가 들어있는 Classification Table (CT)는 명령어의 예측 가능 정도를 저장하고, Value Prediction Table (VPT)는 예측에 쓰일 값을 저장한다. 이 두 개의 table은 명령어를 예측 결과를 확인한 뒤 update 된다. 전반적으로 Branch prediction과 아이디어나 구현의 측면에서 유사하다. 이 내용을 잘 요약해둔 링크가 있어서 참고하였다.
참고 링크: https://www.cs.cmu.edu/afs/cs/academic/class/15740-f03/www/lectures/ValuePredictionDisc.htm
Value Prediction
Value Prediction Daniel Neill and Adam Wierman Presentation Slides are available in [ps] [ppt] Speculative execution is a powerful new technique that can be applied in many different forms. In a typical processor, control speculation is a cru
www.cs.cmu.edu
Value prediction은 mis-prediction에 대한 flush cost가 커서 coverage를 높이는 데에 한계가 있다. 반면, Register File Prefetching (이하 RFP)은 flush를 요구하지 않기 때문에 보다 넓은 coverage를 갖도록 예측할 수 있다.
(추측 및 생각) RFP에서는 prefetched data가 도착할 때까지는 dependent한 명령어가 실행되지 않는다는 것이 차이점이 된다. Prefetch request가 L1 캐시에서 도착하는 시점과 load address가 resolution되는 시점이 대략 비슷해서, prefetch가 도착한 후에 예측에 대한 성공/실패 여부를 검사하여 실패했다면 다시 올바른 L1 캐시 request를 날리고 dependent한 명령어를 계속 stall 시키게 되고, 만약 성공했다면 바로 dependent한 명령어를 실행할 것이다. 값을 예측하지 않고 예측된 주소로 prefetch request를 날림으로써 예측에 대한 resolution을 보다 빠르게 가져가서 flush 위험도를 낮추는 것이 RFP의 장점인 듯하다.
2.2 Load Address Prediction (AP)
AP를 좀 더 이해하기 위해 논문에 reference가 되어 있는 아래 논문의 주요 내용을 읽고 정리해보았다.
Reference paper
R. Sheikh, "Load value prediction via path-based address prediction: Avoiding mispredictions due to conflicting stores", Micro (2017)
(1) PAP (Path-based Address Prediction)
Load-path history register에 최근 load 명령어들의 PC 값의 하위 1-bit (Byte offset을 고려하면 하위 2번째 bit)을 shift 시켜 누적 저장함으로써 이를 global context 정보로서 활용한다. Address Prediction Table (APT)는 Fetch Group Address(FGA)로 인덱싱하며, APT의 각 entry는 tag, address, confidence 등으로 구성된다. 여기서 tag는 global context와 load PC의 XOR 한 값이며, address가 예측하고자 하는 주소이다. 즉, 명령어 단위가 아니라 fetch group 단위로 인덱싱하게 되며, 하나의 fetch group에서 여러 개의 load 명령어가 있는 경우도 있으므로, 최대 2개의 load 명령어에 대해 예측 주소를 얻게 된다.
(2) Value Prediction
Value prediction 하는 producer와 이 값을 operand로 사용하는 consumer 간의 communication 매커니즘을 구현해야 한다. 여기서는 Predicted Values Table (PVT)라는 dedicated HW structure를 따로 두며, 이것은 예측된 값을 담아두는 작은 캐시이다. 캐시의 tag는 load 명령어의 destination register의 번호이다. Value prediction된 명령어가 실행되고 결과 비교 후 validation 검사까지 완료한 뒤 entry는 deallocate 된다.
Rename-map-table (RMT)의 각 entry에 predicted bit이라는 1-bit을 추가하였고, 이는 해당 logical register가 value prediction 되었는지 여부를 나타낸다. 만약 set 되어 있으면 값을 PVT로부터 읽어오고, 그렇지 않은 일반적인 상황에서는 PRF (Physical register file)에서 읽어온다. PVT entry와 마찬가지로 predicted bit도 value predict된 명령어의 validation 검사까지 끝난 뒤 clear 된다. (그 때는 예측이 맞았다면 PRF에 기록될 것이므로)
(3) Dataflow
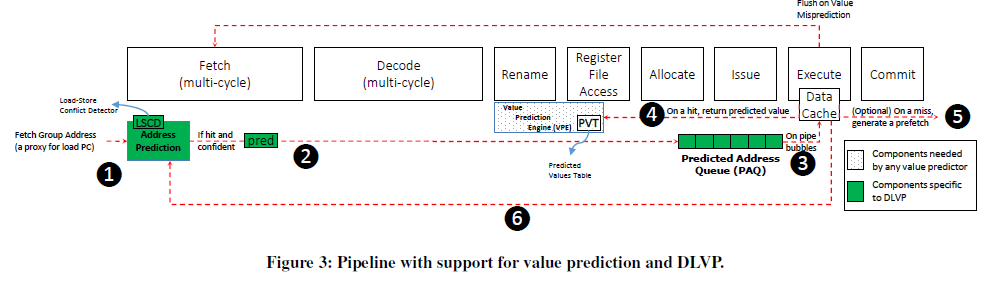
명령어 fetch 단계에서 address predictor에 의해 load address가 예측된다. (1) 이 주소는 PAQ (Predicted Address Queue)에 저장되고 (2), 캐시에 데이터를 요청한다. (3) 캐시 hit이 일어나면 이 데이터를 PVT에 저장하고 (4), miss 시 prefetch 요청을 보낼 수도 있다 (5). 캐시 miss 시의 동작은 크게 중요한 부분은 아니다. Load 명령어가 실행할 때 예측 결과를 확인하고 predictor를 업데이트 한다. (6) 만약 예측이 실패했다면 pipeline flush를 한다.
이 때 예측 결과를 검사하는 것은 항상 다시 캐시 접근을 하여 데이터를 return 받음으로써 이루어진다. 그 이유는 in-flight store 명령어가 있는 경우 주소를 올바르게 예측하였더라도 값은 잘못 예측할 수 있기 때문이다. 여기서는 Load-Store Conflict Detector (LSCD)라는 unit을 두어 이러한 패턴이 관찰되는 load PC 값에 대해 예측을 하지 않고 APT에서 evict 되도록 보완하였다.
(다시 논문의 내용으로)
Address prediction (AP)은 값을 예측하는 것보다는 load 주소의 패턴을 예측하는 것이 더 쉬울 것이라는 관찰로부터 출발하였다. 명령어 fetch 단계에서 load 주소를 예측하고, 바로 L1 캐시에 접근 요청을 보낸다. 명령어가 allocate될 때 L1 캐시로부터 데이터를 받을 수 있고, 이 데이터가 명령어의 값으로 사용된다. 만약 예측된 주소가 틀렸다면 pipeline flush가 요구된다.
AP의 한계점이 2가지 존재하는데, 첫째로 데이터의 correctness의 검증을 위해 다시 한 번 L1 캐시 접근을 하는데, 이로 인해 L1 캐시 BW의 낭비가 된다는 단점이 있다. 둘째로, fetch 단계에서 load request를 실행하면 in-flight에 있는 store 명령어와의 conflict가 있는 경우 예측 성공을 할 수 없고 이 때는 flush가 일어나야 한다.
(추측 및 생각) AP와 RFP의 차이 중 하나가 예측 성공 여부를 판단하기 위해 AP는 L1 캐시 요청을 항상 다시 해서 (즉, 항상 L1 캐시 접근이 2회) 실제 확인한 데이터 (값)를 비교하고, RFP는 load 주소가 계산되었을 때 주소 간 일치 여부를 판단해 일치하는 경우 L1 캐시 요청을 날리지 않는다는 것이다. 그럴 수 있는 이유는, RFP에서는 예측 주소가 같을 때 값이 같다는 것을 확실히 보장하기 때문이며, in-flight store 명령어와의 dependency 문제를 해결함으로써 그럴 수 있었다. u-architecture의 관점에서 보면, prefetch timing이 중요하고 RFP에서는 register renaming 직후에 실행함으로써 dependency 문제를 해결할 수 있었다.
2.3 Memory Prefetching
DRAM 메인 메모리와 캐시 간의 prefetching에 대해서는 이미 많은 연구가 진행되어 왔다. 주로 helper thread가 prefetch를 실행함으로써 memory latency를 숨길 수 있다.
RF <-> L1 캐시 간의 prefetching이 LLC cache <-> 메인 메모리의 경우와 다른 점은 RF에는 tag가 없기 때문에 prefetched 데이터에 대한 identifier가 추가적으로 필요하다는 것이다.
2.5 OoO Pipeline
(1) Load 명령어의 실행 과정
일반적인 OoO pipeline 구조는 Figure 4와 같다.
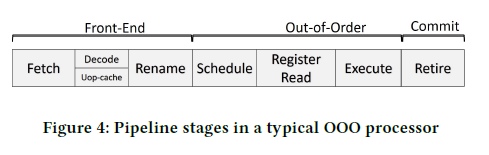
Load 명령어가 fetch된 이후부터 실행을 하여 commit될 때까지 거치는 단계는 아래와 같다.
1) 명령어 fetch 이후에 명령어들은 IQ (Instruction Queue)에 저장된다.
2) Register renaming 단계에서 명령어 간의 dependency를 검사한다.
3) 명령어의 source operand를 변경하는 명령어가 완료되면, 이에 dependent한 명령어가 wake up 되어 schedule 된다.
4) Register file 로부터 source operand의 값을 읽는다. (RF Read)
5) Address generation unit에 의해 주소가 계산되고, address translation을 거쳐, L1 캐시로 데이터 요청을 한다.
6) L1 캐시로부터 데이터를 받아 다시 RF에 저장함으로써 commit 된다.
(2) Speculative scheduling
여기서 실행 시간의 단축을 위해 source load 명령어의 캐시 hit/miss를 예측하여 speculative 하게 dependent 명령어를 스케줄링 할 수 있다. 이를 위해 hit-miss predictor를 두고, 만약 hit을 예측한다면 아직 source load 명령어가 완료되지 않았더라도 speculative 하게 schedule을 한다. 만약 miss가 일어난다면 dependent 한 명령어는 다시 실행되기를 기다린다. 아직 실행 중인 상태가 아니었으므로 pipeline flush가 요구되지는 않는다.



