1 Brief Summary
1.1 Problem/Motivation
As the number of cache hierarchy levels increases, level-wise sequential cache lookup results in higher load latency. Good cache system should be able to reduce the number of misses significantly from one level to the next, but they showed in experiment that certain level of cache cannot reduce the number of misses effectively for many workloads. (In figure 3, except for (a) all the 5 workload shows inefficiency of certain cache level)

1.2 Key idea
The paper suggests to dynamically skip unnecessary cache-level lookup by using cache level predictor (LP). For example, if we can predict that certain memory load request will hit at L3 cache, we can directly access L3 bypassing L2 so that reducing load latency.
1.3 Design Details
Prediction target is one of 3 memory hierarchy: L2, L3, main memory. For an incoming memory load request, memory access can bypass certain cache levels according to its prediction results.
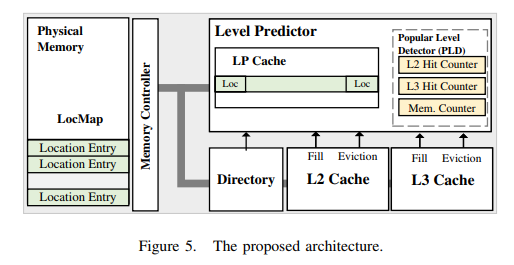
Architecture overview is shown in figure 5. Location information of a cache block is kept in LocMap which resides in system-reserved physical memory. Location information is 2-bit as the number of substitutes of prediction target is 3. Entries of LocMap are cached in LP cache which is newly suggested on-chip buffer connected to L2 cache and in LLC. Size of LP cache is 2KB and was decided from experiment.
Prediction
On every L1 miss, LocMap is accessed with physical address of request. If access hits in LP cache, we use 2-bit location information as prediction results. For miss, we refer to 3 32-bit counters (PLD in figure 5) and get prediction results from comparison of each counter with threshold value.
Update
LocMap is updated with only certain events (demand cache fill, dirty eviction, prefetch fill for LP cache hit) for balancing the tradeoff between accuracy and power efficiency. For example, it doesn't update LocMap for frequent clean eviction in operation of prefetcher.
In LP cache miss, we get prediction result from PLD (Popular Level Detector). There is 3 32-bit counters for each hierarchy (as shown in figure 5). For a hit in specific layer, corresponding counter increases and other decreases by one. In prediction phase, their values are compared with threshold and one or multiple layers are picked as prediction results.
Misprediction recovery
Mispredicting to layer that is closer to core doesn't require any new recovery mechanism, because it can be processed with normal miss handling mechanism. In contrast, the opposite case require new recovery mechanism. This is done with directory which is used for cache coherence. As directory information is collocated with LLC tag, we check directory in every L2 bypass for detecting misprediction. Similarly, misprediction to main memory while requested block was actually cached can be done with checking directory. We should check directory before accessing main memory.
2 Strength
1) This design is scalable with potentially increasing cache level. If there exists additional L4 cache, 2-bit location information can be still used and it only requires one more 32-bit counter.
2) Misprediction recovery efficiently use existing architecture, especially directory which is collocated with LLC tag.
3 Weakness
1) If L2 hit ratio is high enough, this design can rather increase effective latency of L2 access. Prediction occurs on every L1 miss and it fundamentally adds overhead in L2 access.
2) It is basically not a prediction, but an approximate record of location information. It consumes additional memory bandwidth for updating location information.
3) 3 counters update their values with same principle but access ratio of each hierarchy is different. For example, the number of L2 accesses would be much higher than other two. Principle for updating counter should consider this difference and it will be able to achieve more accurate prediction.
'Paper Reading > CPU Microarchitecture' 카테고리의 다른 글
| [ISCA '21] A. Naithani, Vector Runahead (0) | 2023.12.28 |
|---|---|
| [HPCA '03] O. Mutlu, Runahead Execution (0) | 2023.12.25 |
| [HPCA '22] M. Jalili, Reducing Load Latency with Cache Level Prediction (0) | 2023.09.07 |
| [ISCA '22] (2/2) S. Shukla, Register File Prefetching (0) | 2023.07.20 |
| [ISCA '22] (1/2) S. Shukla, Register File Prefetching (0) | 2023.07.17 |



