1 Introduction
Transformer-based model의 memory, computation overhead를 낮추고자 low-precision arithmetic을 사용하는 quantization이 많이 연구되어 오고 있다. Transformer-based model은 outlier가 존재하며 이들은 구조화된 패턴 (예를 들어, 특정한 embedding dimension에 모여있다든지)을 보임이 알려져 있다. Outlier의 존재는 quantization performance에 심각한 damage를 가져오며, 기존의 접근법 중 하나로는 quantization granularity를 보다 finer하게 가져가는 것이 있는데, 이는 오히려 computation cost를 증가시키는 한계점이 있다.
본 연구에서는 우선 LayerNorm의 scaling parameter gamma가 outlier amplifier 역할을 함을 관찰하고, 이를 추출함으로써 quantization에 보다 robust할 수 있도록 한다. 다음으로는 outlier clippling의 효과가 outlier의 중요도에 따라 다르게 나타남을 밝혀낸다.
이 두 가지의 관찰로부터 outlier suppression의 framework를 제안한다. 첫째는 gamma migration으로, outlier amplifying을 하는 gamma를 subsequent module로 이동시켜 연산함으로써 보다 quantization-friendly model을 만드는 것이다. 둘째는 token-wise clipping으로, 적절한 clipping range를 찾는다.
2 Preliminaries
Quantization은 Quant, DeQuant의 2가지 과정으로 이루어진다. Quant는 scaling factor로 나눈뒤 clipping하여 quantization grid로 mapping 하는 것, DeQuant는 다시 scaling factor를 곱해줘서 원래 값의 범위로 복원하는 것이다.
3 Outlier analysis
여기서는 outlier inducement와 impact of clipping outliers에 대해 분석해본다. Outlier는 structured characteristic을 보이는데, 특정 embed dimension에 집중적으로 분포한다거나, separate/comma와 같은 unique token에 대해서만 나타나는 outlier는 특히 aggressive value를 보인다.
3.1 Inducement of outliers
LayerNorm은 embedding dimension-wise (column-wise) mean, std를 구해 normalize 시키고 scale, shift를 한다.

이 때, gamma와 output X_tilda에서 outlier가 같은 embedding dimension에서 나타남을 관찰할 수 있었다. 즉, gamma가 outlier를 증폭하고 있다는 것이므로, 아래와 같이 gamma를 추출해서 non-scaling 하도록 바꾸는 것을 생각해볼 수 있다.

그러면 Figure 1에서 보듯이 보다 milder distribution을 갖도록 할 수 있다. (여전히 308th dim에서 outlier가 나타나지만, 값의 크기로 보면 보다 mild한 분포를 보인다)

3.2 Impact of outlier clipping
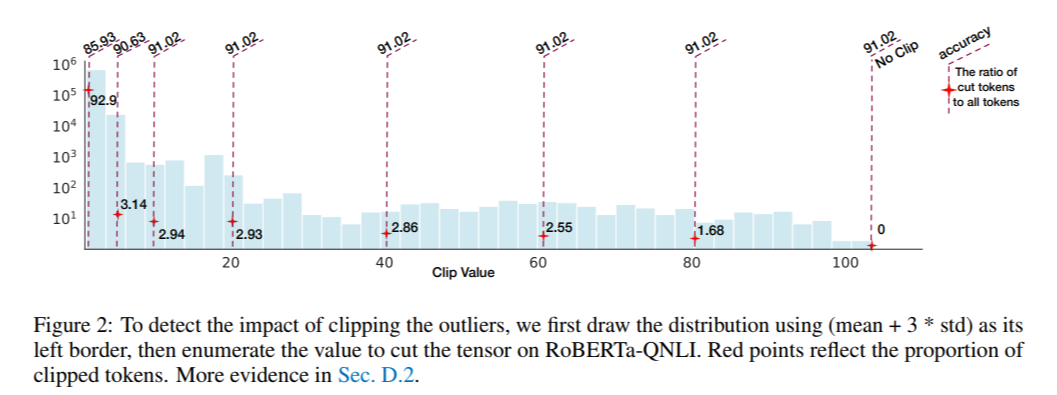
여기서는 적절한 clipping range를 찾기 위해 outlier clipping을 했을 때 model 정확도에 대해 살펴본다.
Figure 2를 보면, 10~100 범위에 속하는 값들을 모두 10으로 clipping을 하더라도 accuracy가 유지되는 것을 볼 수 있다. 하지만, outlier cut된 비율이 너무 높아지면 (가장 좌측의 92.9%) 정확도가 급격히 떨어지는 것을 볼 수 있다. 한편 10~100의 범위를 cut 하더라도 여기에 해당되는 token의 비율은 3% 내외이다. 이들은 sharply
4 Method
4.1 Gamma Migration
LayerNorm의 scaling factor gamma가 outlier를 증폭하는 효과를 발생시키므로, non-scaling LayerNorm의 output을 quantize 한다. 아래 Figure 3과 같이 gamma scaling을 quantize 이후로 이동시켜 equivalent한 model operation을 유지할 수 있다.
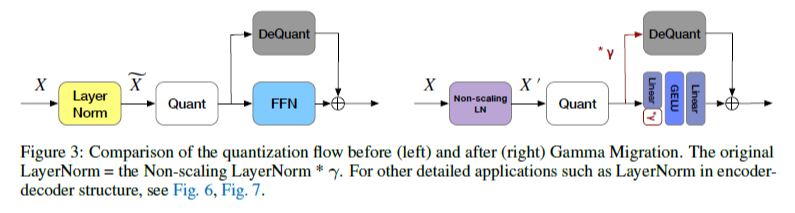
여기서 2가지 정도의 의문이 들 수 있다.
1) Scaling factor를 뒤로 미룬다고 해도 X의 element 간 relative scale은 유지될텐데, 그러면 quantization error 관점에서는 차이가 없는 게 아닌가? 이 질문에 대한 답은 X와 gamma의 outlier dimension이 거의 일치함으로써 사실상 2중 scaling을 하게 된다는 데에 있다. 예를 들어 [1, 1, 4, 1, 2]라는 X row가 있을 때, gamma도 [1, 1, 5, 1, 2]와 같이 X row의 outlier와 비슷한 형태를 띈다면, 이 둘을 곱하면 2중 scaling을 한 효과가 나타나고 quantization error가 커지게 되는 것이다. 따라서 gamma migration을 통해 X 내 relative scale이 증폭되는 것을 방지하고, quantization error를 줄일 수 있다.
2) Dequant 앞에 붙는 거야 상관 없지만, FC layer에 어차피 gamma가 다시 붙으면 거기서 quantization error가 생길 수 있지 않는가? 이 의문에 대해서는 논문에서 짧게 언급이 있는데, weight matrix는 outlier phenomenon이 뚜렷하게 나타나지 않으므로, weight matrix에 gamma를 scaling하더라도, amplifying 효과가 X에 비해 적게 나타난다.
4.2 Token-Wise Clipping
여기서는 모델의 final loss를 고려하여 적절한 clipping range를 찾는 방법론을 제시하는데, 이는 online에 이루어지는 것이 아니라 약간의 training set을 가지고 모델의 hyperparameter를 fine-tuning을 하는 것으로 볼 수 있다. Fine-tuning 과정은 다소 detail에 가까운데, 크게 course-grained와 fine-grained의 두 단계로 나누어 진행한다. Course-grained에서는 alpha라는 비율만큼 clipping threshold를 줄여가며 final loss가 작은 지점을 찾게 되고, fine-grained에서는 gradient descent를 써서 최적의 지점을 찾게 된다.
5 Experiments
5.1 Setup
256개의 sample을 사용해 model을 calibrate한다. 이 과정이 4.2에 해당하는 것으로 보이고, fine-grained에서 사용할 learning rate도 찾고 각 tensor 별 clipping range를 정해두었을 것이다.
5.3 Main Results
여기서는 8-, 6-bit quantization을 실험하였고, BERT 모델의 GLUE benchmark에 대해서 테스트하였다. 비슷한 계열의 모델인 RoBERTa, BART에 대해서도 실험하였다.
(실험 수치나 이에 대한 분석은 논문 참고하면 되니 여기서는 생략)



