1. Introduction
Transformer 모델은 NLP, 컴퓨터 비전 등 DL의 여러 분야에서 높은 성능을 보이고 있는데, 그 핵심 매커니즘은 attention mechanism이다. 이는 모델이 input 간 문맥의 correlation을 학습하도록 하는 의미를 갖는다. CNN과 같은 이전의 딥 러닝 모델에 비해 정확도가 높은 대신 power과 latency의 cost가 높다.
Latency Component & Power Breakdown


Transformer 모델은 Figure 1의 (a)와 같이 N개의 block으로 이루어지며, 각 block 내에는 3가지 component로 구성된다. QKV generation, Attention, FFN이 그것이다. Figure 1의 (b)는 power breakdown을 나타내는데, token 길이에 따라 attention과 그 외의 비율이 차이는 있으나, 기본적으로 QKV generation과 FFN의 비중이 더 크다. 따라서 transformer 모델의 가속을 위해서는 attention layer 뿐만 아니라 QKV generation과 FFN을 가속하는 것이 필수적이다.
Insight & Key Concept
기존의 다수 가속기 논문들이 attention layer에 초점을 맞추었던 것과 달리, 여기서는 attention의 redundancy를 layer의 맨 처음에 예측함으로써 attention 뿐만 아니라 QKV generation, FFN의 연산 또한 가속하고자 한다. Figure 2는 본 논문이 제안하는 가속 구조의 overview를 나타낸다.

먼저 step 1에서 input token, Q, K의 weight을 이용하여 attention matrix를 prediction 한다. 예측된 attention matrix에 대해 row-wise top-k를 취하여 mask를 생성한다.
다음으로 step 2에서는 이 mask에 기반하여 연산량이 감소된 QKV generation과 FFN을 수행한다. QKV generation 때는 모든 행을 다 generation 하는 대신 일부만을 generation 하며, FFN에서는 top-k 결과를 바탕으로 중요한 token이 포함된 행일수록 높은 precision으로 연산을 한다. (즉, mixed precision으로 FFN을 한다) 이렇게 함으로써 정확도의 손실이 거의 없이 연산량을 양 10배 줄일 수 있다.
그러나 이러한 algorithmic optimization을 효율적으로 지원하려면 low power로 prediction 하는 것이 필수적이며, mixed precision FFN을 위해서는 메모리 저장 패턴을 sequential하게 하는 것이 비효율적이다. 이에 dedicated hardware accelerator (FACT라는 이름을 붙임) 구조를 제안한다. 이를 통해 Nvidia V100 GPU에 비해 약 94.98배의 energy saving을 달성할 수 있다.
2. Background and Motivation
2.1 Basic Modules of Transformer Layer
Transformer layer는 다음과 같은 3가지 component로 구성된다.
1) QKV generation
(L, D_e) 크기의 input token tensor가 들어오고, 이들이 QKV weight과 곱해져 (L, D) 크기의 QKV 행렬을 generate 한다.
2) Attention
Q와 K transpose를 곱하여 (L, L) 크기의 attention matrix를 얻는다. Row-wise softmax 연산을 거쳐 확률 값으로 만들어준다. V 행렬과 곱하여 (L, D) 크기의 attention output을 얻는다.
3) FFN
모든 head의 attention output을 concat하여 얻은 (L, D_e) 크기의 input을 fc layer 2개를 통과시켜 (L, 4 * D_e), (L, D_e)의 output을 차례로 얻는다.
2.2 Computational Properties Analysis
위에서 설명한 연산 특성으로부터 각 연산의 complexity를 분석할 수 있다. 각 행렬 곱의 dimension으로부터 아래와 같은 분석을 얻을 수 있다.


이들의 latency breakdown은 token length L에 따라 달라진다. 연산 complexity 분석과 Figure 3을 함께 보면, L이 1k 미만인 일반적인 경우에는 QKV와 FFN 연산이 dominant 함을 알 수 있다.


물론 L이 커짐에 따라 attention 연산이 차지하는 비중이 늘어나는데, 우선 L이 1k 보다 큰 모델이 많지 않으며, attention layer에 대한 가속은 기존 연구에서 많이 다루어졌다. Table 1에서 보면 기존 가속기는 주로 attention을 target으로 하며, SpAtten과 같은 경우는 attention을 target으로 했지만 token pruning을 통해 이후 layer들의 QKV generation, FFN의 연산량도 줄이는 효과를 갖는다.
따라서 본 논문에서는 QKV generation과 FFN 연산의 가속이 중요함을 주장하며, 이후에 이에 대한 가속 솔루션을 제안하고자 한다.
3. Eager Prediction Mechanism
여기서는 EP (Eager Prediction)이라는 algorithm optimization을 설명한 뒤, 이를 통해 QKV generation과 FFN에서 불필요한 연산량을 어떻게 줄이는지를 설명할 것이다.
3.1 Eager Correlation Prediction
Q, K^T를 행렬 곱하여 attention matrix A를 얻은 뒤, row-wise softmax 연산을 하여 attention score matrix S를 얻는다. 이 때, matrix S에서 소수의 element들이 높은 확률 값을 가진다면 output에 영향을 거의 주지 않고 값이 작은 나머지 element들을 연산에서 생략할 수 있다. 이것이 기존의 가속기 논문들에서 활용하는 sparse attention의 개념이다.
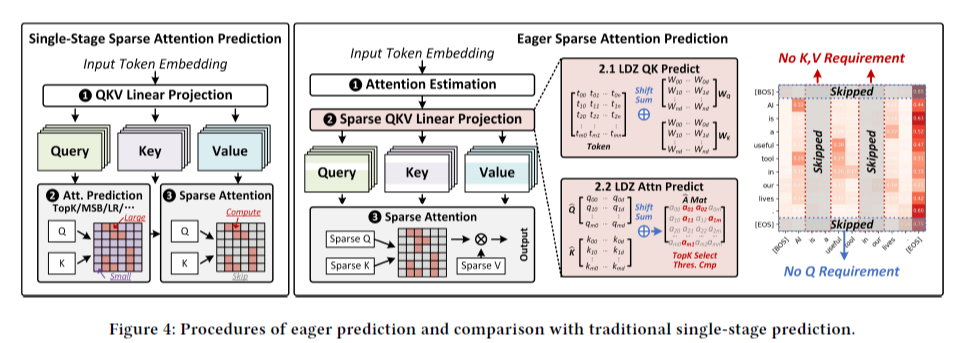
Figure 4의 왼쪽 그림이 sparse attention을 나타낸다. 하지만 이것은 attention 연산을 줄일 뿐, QK generation의 연산을 줄이지는 못한다는 한계점이 있다. 본 논문에서 제안하는 EP 알고리즘은 attention 연산 뿐만 아니라 QKV generation의 연산 또한 줄이고자 한다.
Figure 4의 오른쪽 그림이 본 논문이 제안하는 Eager Prediction (이하 EP)를 나타낸다. 크게 2가지 step으로 구성되는데, 1) prediction branch와 2) computation branch 이다. 먼저 attention matrix의 approximate value를 예측하고, 이 예측 결과를 바탕으로 일부 연산을 skip 하여 Q, K, V, attention matrix를 얻는다.
Prediction branch에서 어떻게 효율적으로 예측을 잘 하느냐가 key concept 중 하나인 것인데, low precision 자료형을 사용하더라도 matrix multiplication을 하는 것은 power consumption 낭비가 존재한다. 따라서, 여기서는 log-based multiplication-free prediction을 제안한다.
LOD-based Approximation
LOD (Leading-one detector)를 이용하여 데이터 값을 log domain으로 옮겨오고, 그 이후에는 곱셈 대신 shift-and-add operation으로 계산할 수 있다. 아래 수식이 그 공식이며, 2가지 예시로 따라해볼 수 있다.

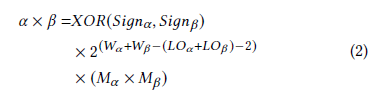
즉, LO (leading-zero count)로 값을 approximate하겠다는 것이다. 그러면 오른쪽 수식과 같이 두 수의 곱을 LO 간의 덧셈으로 approximate 할 수 있다.
이 개념을 transformer layer에 적용해보면, token T와 Q, K의 weight을 대상으로 approximated multiplication을 수행해서 Q, K에 대한 prediction을 얻는다. 이는 Section 4에서 설명할 one-hot accumulator를 이용하여 구현된다. 이렇게 Q, K의 prediction을 얻었으니, 마찬가지 방식으로 attention prediction도 얻는다. 실험 결과에 의하면, 이렇게 attention matrix를 예측했을 때 top-k result의 90%를 맞출 수 있었다고 한다. Parallel top-k filter를 거쳐 각 행에서 어떤 key들이 중요한지를 찾을 수 있다.
3.2 Attention-distribution-aware QKV Generation
3.1의 EP 방법에 의해 transformer layer의 시작 시점에 attention에 대한 예측 값들을 얻을 수 있다. 여기서는 이렇게 얻은 attention의 sparsity를 활용해 QKV generation 가속을 하는 방법을 살펴본다.
1) K, V Sparsity
만약, attention prediction matrix의 column 중 top-k에 의해 선택된 것이 하나도 없다면, K^T의 column의 generation을 생략할 수 있다는 것이다. 이후에 attention과 V 간의 행렬 곱을 할 때도 해당 column과 곱해지는 V의 row는 generation 할 수 없다. 즉, top-k에 의해 선택된 것이 하나도 없는 column과 같은 index의 K, V의 row는 generation을 생략할 수 있다.
2) Q Sparsity
Q sparsity는 K, V와는 다르게 고려되어야 하는데, softmax 자체가 row-wise operation이므로 위와 같은 방식으로는 Q의 row generation 생략을 할 수 없기 때문이다. 대신 softmax-distribute-aware pruning을 제안한다.
Softmax를 거치면서 하나의 행 내에서 어느 하나의 element 값이 거의 1에 근접하게 dominant 한 경우가 transformer 모델 내에서는 다소 흔하다. Attention mechanism 자체가 token들 간의 contextual correlation을 나타내기 때문에 특정 pair가 높은 값을 가지는 경우가 많기 때문이다. 또한, <bos>, <eos>와 같은 special token들은 특히 attention에서 그러한 패턴을 가지는 경우가 많다.
따라서 각 행 별로 1번째, 2번째로 큰 값 간의 차이를 threshold와 비교하여 만약 threshold보다 크다면, 해당 행은 largest token에 의해 dominant 하다고 판단하여 softmax result로 one-hot tensor를 사용한다. 즉, 이후의 computation branch에서 attention matrix의 해당 행은 계산할 필요가 없으므로, 이에 필요한 Q의 row의 generation을 생략할 수 있다.
3.3 Token-wise Mixed Precision FFN Computation
FFN layer의 input은 (L, D) 크기의 tensor이다. (L은 token length, D는 embedding size) 이 때, token 별로 importance를 파악해 mixed precision으로 FFN 연산을 하는 방식을 제안한다.
Token importance는 token이 key로서 top-k operation에 몇 번 선택되었는지 횟수이다. Threshold를 정해두고 만약 더 크면 이 token에 대한 FFN은 full bit width로 진행하고, 그렇지 않으면 low precision (여기서는 4MSBs)으로 연산을 진행한다.
4. Architecture and Hardware Innovation
4.1 Overall Architecture
논문에서 제안하는 HW FACT는 QKV generation, attention, FFN을 포함한 transformer layer 연산의 거의 대부분을 수행한다. Host processor가 transformer task를 수행할 때, external memory에 transformer layer의 input, weight을 넣어둠으로써 FACT가 연산을 시작할 수 있다. FACT가 모든 연산을 마친 뒤에는 그 결과를 다시 external memory에 넣어둔다.
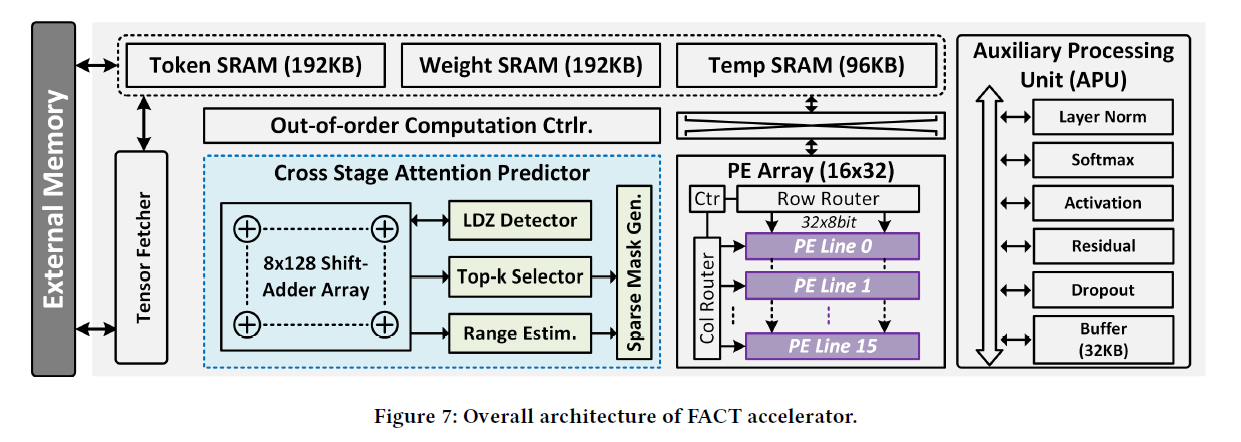
FACT의 overall architecture는 Figure 7과 같다. Dataflow, main modules를 중심으로 간략히 overall architecture를 살펴보면 다음과 같다.
1) External memory로부터 input을 load하고, APU (Auxiliary Processing Unit)은 layer normalization과 같은 input 전처리를 수행한다. 전처리가 끝난 결과를 연산에 사용할 수 있도록 token buffer에 저장해둔다.
2) Token embedding이 available하면, prediction unit에서 attention matrix에 대한 estimation을 연산한다. 방법은 Ch 3에서 소개한 log-based add-shift operation이다. 그 결과로 top-k mask와 sparse computation map을 얻는다.
3) Scheduler는 QKV generation 연산을 수행하는 PE에 대한 schedule을 담당한다.
4) 하나의 head에 대한 QKV generation이 완료되면 attention 연산을 시작한다. 이 때 PE는 이전에 prediction unit이 생성한 top-k mask에 기반하여 Q, K의 필요한 row와 column을 fetch하여 sparse attention 연산을 수행한다. 이와 동시에 APU는 row-wise softmax 연산을 한다.
5) 2) ~ 4)의 과정을 모든 head에 대해 수행하며 각각의 attention result를 얻고, 이를 external memory에 저장한다.
6) External memory로부터 이를 fetch하여 mixed precision FFN을 수행한다.
4.2 EP Unit with One-hot Adder Tree

EP unit은 크게 4가지 component로 구성된다.
1) 행렬 곱의 두 operand를 저장해두는 2개의 cache (각각 64-bit과 1024-bit)
2) Zero-elininator: 연산이 필요없으므로 삭제한다고 되어 있는데, cache size와 adder array의 크기가 고정된 상태에서 이것이 의미가 있는지는 잘 모르겠다.
3) Cascaded LO detector: 2개의 8-bit LO detector가 cascade 되어 있는 형태이다. 그 이유는 mixed precision을 지원하기 위함이며, 만약 16-bit precision인 경우는 각 LO detector가 MSB 8-bit, LSB 8-bit에 대해 detection한 뒤 AND 연산을 하여 계산한다. Ch 3의 알고리즘과 연관지어 생각한다면, 데이터를 log-based approximated value로 바꿔주는 역할을 한다. Output은 5-bit인데, MSB sign bit과 LO의 position을 나타내는 4-bit 이다. 그런데 그림에는 sign bit은 생략되어 표현된 것으로 보인다.
4) 8x128 adder array: 최대 8개의 행에 대한 행렬 곱의 approximation 결과를 계산한다. 두 개의 LO를 더한 결과를 누적해야 하는데, scale을 생각해보면 이것은 LO 간의 덧셈이 아니라 원래의 2's complement 형태의 덧셈이 되어야 한다. 그런데 이것은 overhead가 크기 때문에, 누적되는 대상이 one-hot 데이터라는 점에 착안하여 각 LO 별 count를 parallel 하게 계산한 뒤 table을 읽으며 계산하는 방식을 사용한다.
* 약간 모호한 점
4)에서 weight stationary adder array의 operand가 두 matrix 내에서 어떻게 partition 되며 iteration 되는지가 나와있지 않은데, 잘 모르겠다.
그림과 설명이 모두 positive number를 가정하고 나와 있는데, sign bit을 어떻게 고려해줘야 할지를 생각해보았다. LO 간의 덧셈은 어차피 positive 기준이니 상관 없고, one-hot adder에서 결과를 누적할 때 sign bit을 확인하여 음수인 경우 position count를 더하는 대신 빼주면 될 것이다.
4.3 Out-of-order QKV Generation Scheduler
EP를 통해 attention matrix를 estimation 하는데, 그 동안 QKV generation을 하지 못한다면 latency 이득을 충분히 얻을 수 없다. 이에 Figure 9와 같은 out-of-order KV generation을 제안한다. EP에서 row-wise로 attention을 estimation 하여 top-k mask를 얻는데, 이 때 top-k에 의해 선택된 열에 대해서 먼저 K, V generation을 하는 것이다.
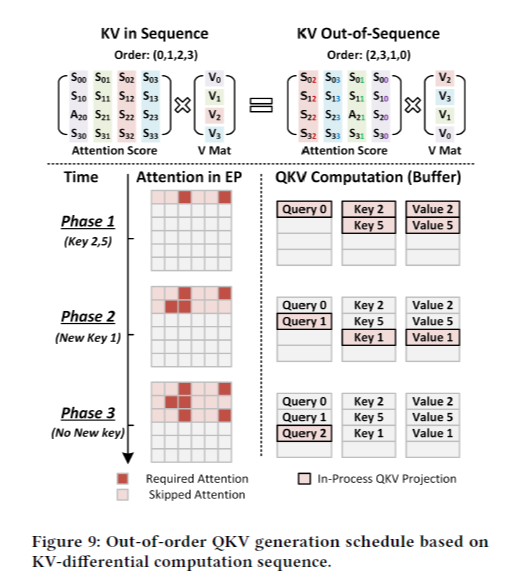
위 그림에서 row 0을 estimation한 후에 key 2, 5에 대한 K, V의 row를 먼저 generation 한다. row 1을 계산했을 때 key 2는 이미 generation 되었으므로 넘어갈 것이다.
본문에 나와 있지는 않지만 Q에 대해서도 비슷한 개념을 적용할 수 있을 것이다. Out-of-order는 아니지만, 하나의 행을 estimation 하면 Q의 해당 행을 generation 할지, one-hot vector로 approximate할지를 결정할 수 있으므로, 이 결정에 따라 필요한 경우 바로 generation 하는 것이다.
4.4 Diagonal Storage Pattern for Mixed Precision FFN
Ch 3의 알고리즘에서 token의 중요도에 따라 FFN에서 token에 따라 high/low bit precision을 다르게 하여 연산을 진행한다. 그러나, 마지막 head의 연산이 끝나기 전까지 token importance는 결정되지 않고, 연산 결과들은 이미 SRAM에 full bit width로 저장되어 있는 상태이다. 따라서 low-precision인 경우에는 가져온 데이터의 절반을 버리는 것이므로, 메모리 접근에 있어 비효율적이다.
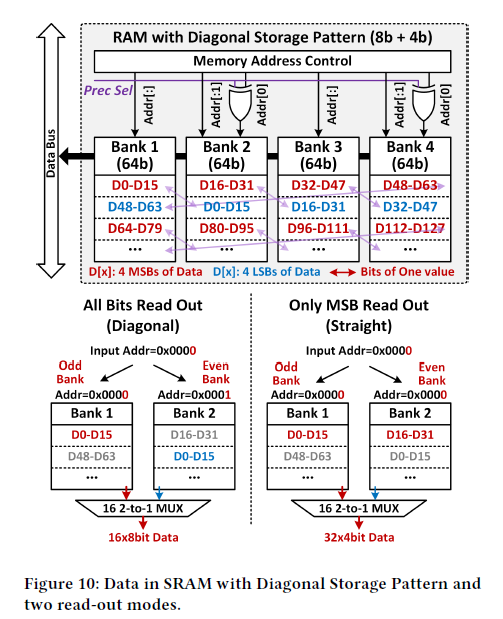
이에 Figure 10과 같이 diagonal storage pattern을 제안한다. SRAM에 저장할 때 MSB 4-bit, LSB 4-bit을 연이어 저장하는 대신 diagonal pattern을 이루도록 저장한다. 만약 full precision이 필요한 경우는, address controller가 even bank에 대해 address의 마지막 bit만 invert 시킨다. 그러면 full precision 데이터를 얻을 수 있고, 그렇지 않은 경우는 모두 같은 address로 접근한다.
마지막에 데이터를 올바른 순서로 다시 얻기 위해 16개의 2-to-1 MUX를 사용한다고 했는데, 이것은 다소 의문이다. Input, output의 bit width가 같고, control signal도 없으므로 MUX를 사용할 이유는 없어보이고, 대신 bit selection을 통해 순서를 바꿔주는 것이 요구될 것 같다.
5. Evaluation
5.1 Experiment Setup
Performance 측정을 위해 몇 가지 transformer 모델과 task를 선정하였다. NLP task에 대해서는 BERT-base, BERT-large 모델을 사용하였고, text classification task에 대해 fine tuning 시켰다. CV task에 대해서는 ViT-B/32, ViT-B/16 모델을 사용하였고, ImageNet classification에 대해 fine tuning 시켰다. 모델의 구현에는 Huggingface, Pytorch를 이용하였다.
FACT accelator에 대해 RTL design을 하였고, 이를 synthesize 하여 chip의 power consumption과 latency를 시뮬레이션 하였다.
5.2 Accuracy Evaluation
EP 알고리즘에서는 2가지 hyperparameter가 존재한다.
1) top-k ratio k: attention matrix에서 각 row 별로 상위 k %의 token만 남겨두고 pruning 하겠다. Trade-off 관계는 k가 작아질수록 computation 이득은 커지지만, potential accuracy loss도 커진다.
2) row-wise mix-precision ratio r: token의 top-k key 횟수의 threshold로, r보다 큰 것은 high precision을 사용한다. Trade-off 관계는 r이 커질수록 computation 이득은 커지지만 (더 많은 token에 대해 low-precision을 사용할 것이므로), potential accuracy loss도 커진다.


Figure 11과 같이 k, r 값을 바꿔가며 모델 별로 연산 이득과 accuracy loss를 측정하여, accuracy loss가 0, 1, 2%인 k, r 값을 찾았다.
Figure 12에서는 BERT-Base, BERT-Large에 대해 k, r 값을 독립적으로 변화시켜가면서 accuracy를 측정하였다. 결론적으로는 r 값이 0.7 이하일 때는 accuracy loss가 거의 없이 최대 85%의 연산을 safely 생략할 수 있으며, 0.9가 넘어갈 때는 정확도를 고려하여 k 값을 신중하게 선택해야 한다.
5.3 Performance Evaluation
FACT의 데이터는 PyTorch를 이용해 만들었고, PT를 이용해 FACT의 time consumption, on-chip data preparation을 시뮬레이션 하였다. 메모리에 대해서는 FACT의 external memory request 신호에 기반하여 Ramulator를 이용하여 시뮬레이션 및 throughput을 측정하였다.
Baseline은 모델에 대한 vanilla와 EP의 두 버전을 Nvidia V100 GPU에서 돌리는 것이다. GPU와 비교를 하기 위해 250개이 FACT accelerator를 가정하였다. (이 부분의 이유는 아직 잘 정리되지 않았다...)
비교 결과는 Figure 13과 같다.
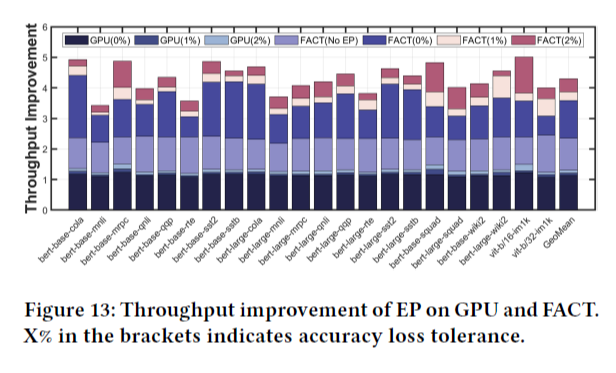
GPU에서 EP 결과를 효율적으로 활용하지 못하는 이유는 높은 sparsity 연산에 효율적이지 않기 때문이다. 또한 log-based approximation도 효율적으로 처리하지 못하기 때문이다. 그에 반해 FACT는 transformer-oriented dataflow에서 약 85.5%의 PE utilization을 보이며, 효율적으로 HW를 사용할 수 있다.
결과적으로 FACT는 baseline GPU에 비해 accuray degradation이 0, 1, 2%일 때 각각 3.59, 3.87, 4.3 배의 speedup을 달성하였다.



