지난 포스팅에 이어서 이번 포스팅에서는 SpAtten의 알고리즘 및 HW 구현에 관한 detail을 다룬다.
3. Algorithmic Optimizations
3.1 Cascade Token Pruning
Human language에는 필수적이지 않은 token들이 여러 개 존재하기 때문에, 이러한 token들을 찾아 제거한다면 보다 효율성을 높일 수 있을 것이다. 각 token들의 중요도의 판단 기준인 importance score는 attention layer를 통과할 때마다 attention probability를 누적해서 더한 것으로 계산된다.
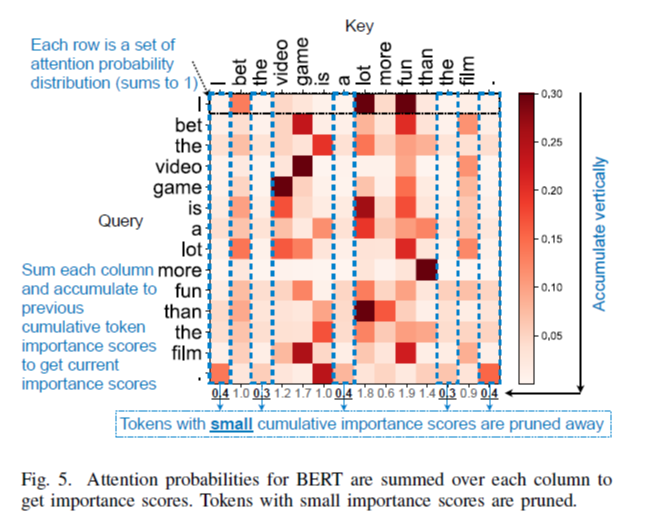
Figure 5에서 'fun'에 해당하는 key vector를 보면, probability 값이 높은데, 이것은 다른 token들과의 연관성이 높다는 것을 의미한다.
하나의 head 내에서 key token에 대한 score는 모든 query와의 attention probability를 더함으로써 얻는다. BERT에서는 이전의 token pruning을 다음 head와 layer에서도 사용한다. GPT-2에서는 모든 generation iteration에 대해 importance score를 누적시킨다.
사전에 정의된 pruning ratio에 따라 top-k token을 선택한다. 한 번 pruning된 token들에 대해서는 Q, K, V 행렬의 값들이 이후 head, layer에서 더 이상 사용되지 않는다.
3.2 Cascade Head Pruning
여러 개의 head가 존재하는 것은 token 간 dependency 관계를 여러 개 학습하기 위함이다. 그러나, head들 역시 redundant한 것들이 있기 때문에, pruning을 할 수 있다. head의 importance score는 각 head 별 attention output의 element 값을 모두 더한 것의 절댓값이다. 여기서 head 별 attention output이란 attention probability와 V의 행렬 곱 결과를 말한다.
Multihead attention layer의 output을 내는 마지막 과정을 생각해보면, 각 head들의 output을 모두 concat 시켜 fc layer를 통과시킨다. 여기서 token pruning에 의해 각 head들의 output dimension이 감소하고, head pruning에 의해 head의 수가 감소하는 것이기 때문에, both dimension이 모두 감소하는 것이다.
3.4 Progressive Quantization
Softmax 연산은 quantization error를 줄이는 효과가 있다. 행렬 Q, K에 대해 quantization을 하면, 이들의 행렬 곱인 attention score에 오차가 생기는데, attention probability를 얻기 위해 softmax 연산을 거치면 오차가 줄어들게 된다. 논문에서는 수식적 유도가 나와 있는데, 이는 생략하기로 한다.

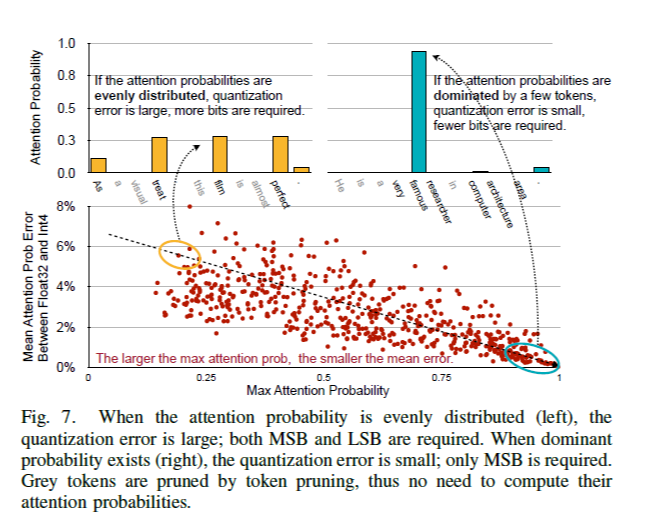
위와 같은 사실에 근거해 Figure 6과 같이 progressive quantization을 한다. 먼저 MSB 부분만을 이용해 attention probability를 계산하고, token들의 확률 분포가 flat 한지, 소수의 token이 dominant 한지를 판단한다. 만약 소수의 token이 확률 분포에 있어 dominant한 경우는 quantization error가 작기 때문에 바로 연산을 끝낼 수 있다. 그러나 확률 분포가 flat한 경우는 다시 LSB 부분까지 fetch하여 attention probability를 계산한다.
본 논문의 실험에서는 MSB+LSB 조합을 5개 제시하는데, 예를 들어 4+4 이런 식이다. 그러나 하나의 task에서는 MSB+LSB 조합을 같도록 한다. 각 확률은 DRAM에서 MSB는 MSB끼리 연속적으로, LSB는 LSB끼리 연속적으로 저장되어 있다. 즉, 더 많은 연산과 더 적은 DRAM fetch를 trade 한 것이다. 이러한 progressive quantization은 memory-bounded한 GPT-2 모델에 적합하며, computation-bounded한 BERT의 경우 이러한 추가적인 연산이 낭비가 될 수 있으므로 static quantization만을 적용한다.



