이번 포스팅에서는 transformer 및 attention 가속과 관련된 유명한 논문인 A3를 정리 및 리뷰해본다.
1. Introduction
Brief Background
CNN, RNN을 지원하는 FPGA/ASIC-based accelerator는 많은 선행 연구가 있어 왔지만, attention mechanism을 사용하는 neural network에 대해서는 HW 가속기 지원이 충분하지 않다. (물론 지금은 많지만, A3 논문은 2020년에 발표되었다) Attention mechanism은 content-based similarity search를 통해, 현재 processing 중인 정보와 연관이 많은 것이 무엇인지를 결정한다. 이러한 특성 덕분에 현재 CV, NLP 등 deep learning의 여러 분야에서 높은 성능을 달성하며 널리 쓰이고 있다. 하지만, attention mechanism은 search target의 제곱에 비례하는 복잡도를 갖기에 computational cost가 크다.
Key Concept
이러한 연산 복잡도를 낮추기 위해 본 논문에서는 HW의 효율적인 구현 뿐만 아니라 연산의 수를 줄일 수 있는 algorithmic optimization/approximation을 제안한다. Search target의 중요도가 서로 다르다는 관찰로부터, 중요한 정보만을 processing하는 방법을 제안함으로써 연산의 수를 줄인다. (본문 Ch 4에서 제안하는 'candidate selection mechanism') 다음으로는 parallelism을 이용한 pipeline 구조를 제안하여 이를 효율적인 HW로 구현하고자 하였다. 이러한 algorithm-hardware co-design을 통해 본 논문의 A3 design은 speedup, energy efficiency 측면에서 우수한 성능을 나타낸다.
2. Background and Motivation
2.1 Attention Mechanism

Attention mechanism은 Figure 1의 pseudocode와 같다. BERT나 GPT 계열 (이 논문에서는 GPT를 다루지는 않는다)의 경우 query도 key matrix와 같은 dimension을 가지나, 이 논문의 여러 예시에서는 위 Figure과 같이 (1, d)의 dimension을 갖는 query를 가정한다. Query matrix의 1번째 dimension(=feature vector의 수, token 수)가 1개인 경우의 논의가 n개로 확장될 수 있기 때문에, BERT, GPT의 구조와 관련지어 이해해도 될 것이다.
Attention mechanism을 살펴보면, 우선 query vector과 key matrix의 vector들 간의 similarity(=score)를 계산한다. 그리고 score와 value matrix를 곱함으로써 output을 얻는다.
2.2 Cost of Attention Mechanism
연산 complexity를 보면 dimension parameter n과 d에 linear하게 비례한다. 참고로, BERT, GPT와 같은 모델의 경우 n^2에 비례한다. Figure 3은 attention mechanism이 전체 inference runtime에 있어 상당한 비중을 차지하고 있음을 나타내며, 본 논문에서 제안하는 attention acceleration의 필요성을 보여준다.
참고로, BERT를 제외한 나머지 모델/task의 경우는 query-independent한 preprocessing이 존재해서 전체 inference 시간과 QA의 시간이 다르게 나타난다.
2.3 Opportunity for Approximation
모델의 구현은 대부분 torch, tensorflow와 같은 framework로 구현되며, 이들은 dense matrix-vector multiplication을 통해 연산을 실행하도록 되어 있다. 하지만, attention 연산의 본질은 dense matrix-vector mult.의 정확한 계산보다는 중요한 index에 대한 search이다. Softmax 연산 후에 대부분의 값은 near-zero 이고, 그 정확한 값은 중요하지 않다. 이러한 관찰로부터 본 논문에서는 key matrix를 preprocessing 하여 높은 score를 가질 가능성이 있는 candidate row들을 위주로 빠르게 QK^T를 계산하는 방법을 제안한다. (Ch 4에서 이어지는 내용인데, QK^T 연산의 complexity를 n*d 번의 곱셈에서 constant 횟수로 줄일 수 있다)
3. A^3 Base Design
여기서는 CPU, GPU, 다른 HW 가속기 등에 integrate 될 수 있는 형태의 HW 가속기 base design을 제안한다. 22-23년의 가속기 논문들을 보면 algorithmic optimization을 먼저 제시한 뒤 이에 맞는 HW를 이어서 제시하곤 하는데, 아마 A^3 논문이 나올 당시에는 transformer/attention 가속기 논문이 나오는 초창기라서 base design부터 제시하는 것으로 보인다.
3.1 Pipeline Design
Figure 4는 block diagram을, Figure 5는 HW 구조에 맞춰 attention 연산 알고리즘을 재구성한 것이다.
3.1.1 Module 1: Dot-product Computation
Query vector와 key matrix의 1개의 row의 dot-product를 계산한다. d개의 multiplier과 d-way adder tree로 이루어져 있어, 먼저 element-wise로 parallel하게 곱셈을 한 뒤, 이를 adder tree를 이용하여 누적하는 방식으로 계산한다. 연산 결과는 dot product output register에 저장된다. Key matrix의 n개의 행에 대해 iteration을 함으로써 QK^T를 모두 계산한다.
한편, dot product 결과의 최댓값을 maximum value register에 저장하는데, 이는 이후에 softmax normalization에 사용되기 때문이다.
3.1.2 Module 2: Exponent Computation
Exponent computation의 경우, taylor expansion을 이용해 연산 unit을 구성할 수도 있지만, 여기서는 lookup table을 만들어두고 값을 읽는 방식을 사용한다. 그러나, overflow에 대한 처리와 lookup table 크기에 대한 challenge가 존재한다.
첫째, overflow 문제는 softmax 연산이 input vector의 constant addition에 invariant하다는 성질을 이용하여 해결한다. Module 1에서 저장해둔 maximum value를 빼준 뒤 exponent를 취하면, 결과에 영향 없이 값의 범위를 항상 0보다 작거나 같도록 할 수 있다.
둘째, lookup table size로 인한 overhead는 upper/lower half로 나누어 lookup table을 구성하여 해결한다. 만약 16-bit이라면 full lookup table의 크기는 2^16=65,536개의 entry를 가지지만, 이를 만약 8-bit 씩 나누어 table을 구성한 뒤 두 값을 곱한다면 1개의 multiplier가 추가로 필요한 대신 2^8=256개의 entry를 갖는 lookup table 2개로 overhead를 줄일 수 있다.
3.1.3 Module 3: Output Computation
Exponent sum을 나누어줌으로써 softmax 연산을 마무리한다. Module 1과 마찬가지로 matrix-vector addition을 수행하지만, iteration을 하는 dimension이 다르다. 하나의 weight에 대해 value vector와 곱한 뒤, value vector를 accumulation 하는 방식이다. Module 1에서 output vector dimension에 대해 iteration 한 것에 반해, 여기서는 input vector dimension에 대해 iteration 한다. 그 이유는 expsum을 나누어주는 연산을 하기 때문이다.
Throughput and Latency
총 3개의 모듈이 pipeline 구조로 query를 처리하므로, 최대 3개의 query가 동시에 processing 될 수 있다. 하나의 query 당 n+9 cycle이 걸린다고 한다. 이는 module 3을 기준으로 계산된 것이며, division이 7 cycles, mult & accumulate가 2 cycles 걸려서 n+9 cycles로 계산된 것이다.
3.2 Quantization
Register, computation unit의 energy를 낮추기 위해 bit width를 작게 하는 quantization을 적용하며, 추가적으로 floating-point 대신 fixed-point를 사용한다. 각 pipeline stage마다 다른 bitwidth를 갖도록 함으로써, energy cost를 최소화하면서 동시에 accuracy도 유지하고자 한다.
3.3 Design Details
Offloading (=Integration)
A3 unit은 CPU, GPU, 기존 HW 가속기에 integrate 될 수 있다. Key, value matrix는 A^3의 SRAM buffer에 저장되어 있는 것을 가정하며, host device가 query vector를 전송한 뒤에 이를 buffer로 옮겨담으면서 A^3의 동작이 시작된다. 동작이 종료되면 output vector를 host device와 통신할 수 있는 buffer에 저장한다.
Multiple A3 Units
NN task 중에서는 같은 key, value set에 대해서 여러 query를 처리하는 경우, 또는 아예 별도의 key, value set에 대해 처리하는 경우 등 서로 독립적인 attention computation 여러 개를 요구하는 경우가 있다. 이런 경우 여러 개의 A^3 unit을 사용하여 parallelism을 높일 수 있다.
Choice of n and d
여기서는 key, value matrix의 length인 n=320, embedding(=hidden) dimension인 d=64를 최대로 가정하고 HW를 설계하였다. 만약 더 큰 n이 요구되는 경우, 처음 n개를 SRAM으로 우선 가져오고, 이들을 처리함에 따라 DRAM으로부터 prefetch할 수 있다. d의 경우 64로 충분할 것이라고 나와 있다.
* 참고
하지만, 최근 등장하고 있는 BERT, GPT-2와 같은 LLM (Large Language Model)의 경우 d=768과 같이 훨씬 큰 embedding dimension을 사용하기에, 유효하지 않은 경우가 발생하고 있다.
4. Approximate Attention
4.1 Overview
Approximate attention의 key observation 중 하나는 QK^T의 곱인 weight의 많은 값이 near-zero이며, 이들에 대해서는 softmax 및 value vector와의 weighted sum을 생략할 수 있다는 것이다. 더 나아가, 낮은 score를 가질 것이라고 예상되는 key vector과의 computation도 생략할 수 있다. 이러한 intuition으로부터 본 논문에서는 높은 score에 기여할 것이라고 예상되는 candidate만을 선택하는 approximate attention 알고리즘을 제안한다.
이 방식은 key maxtix에 대해 preprocessing이 가능한 경우에 더 유리하며, BERT의 경우 preprocessing은 불가능하지만 overhead가 작다고 되어 있다. BERT를 포함해 최근의 LLM의 경우, key matrix가 available한 직후에 바로 QK^T 연산이 요구되기 때문에 preprocessing을 미리 할 시간이 없다는 점을 생각해봤을 때, 본 논문의 방식은 근본적으로 preprocessing overhead를 갖는다고 볼 수 있다. (물론 이후 approximate computation을 통해 연산의 수를 줄인다)
4.2 Base Greedy Candidate Search
QK^T 곱을 하나의 element 단위로 보면 query vector와 key matrix의 row vector 간의 elementwise mult.의 누적이다. Main idea는 하나의 elemen mult.의 값이 large positive라면 final result 역시 large positive일 가능성이 높다는 것이다. 반대로 large negative라면 final result가 large positive일 가능성이 낮다.

Figure 6의 예시와 함께 알고리즘을 이해해보자. 가운데 (4, 3) matrix가 elementwise mult. 값들을 적어놓은 것인데, 반복적으로 가장 큰 값과 작은 값을 찾는 것이다. k번째 iteration은 k번째로 큰 값과 작은 값을 찾게 된다. 총 M번의 iteration을 하는 동안 선택된 2*M개의 값들을 누적하여 approximate result를 얻게 된다. 하지만 현재 base 알고리즘은 O(nd log(nd))의 complexity를 가지고, 이것은 오히려 기존의 O(nd) 보다 느리다. 이에 4.3에서 같은 main idea를 갖되, 구현의 측면에서 보다 효율적인 알고리즘을 제안한다.
4.3 Efficient Greedy Candidate Search
여기서는 key matrix의 preprocessing을 가정한다. 이것은 query response time 사전에 할 수 있기 때문에 overhead로 작용하지 않는다. Transformer 기반 LLM의 경우 self attention을 사용하는데, 이것은 multiple query vector에 대해 같은 key matrix를 사용하기 때문에 overhead의 영향이 크지 않다고 되어 있다. (그렇기는 해도, 이 경우 preprocessing도 inference runtime에 포함된다)


4.3.1 Preprocessing
(n, d) 크기의 key matrix의 각 열을 크기 순으로 sorting 한다. Sequence length dimension에 대해 sorting 된 것이다. 각 열 별로 max_ptr를 초기화하는데, 만약 해당 열의 query 값이 positive라면 가장 큰 값으로, negative라면 가장 작은 값을 가리키도록 초기화한다. min_ptr은 그 반대이다.
Priority queue 2개 maxQ, minQ를 초기화한다. 각 열별로 max_ptr이 가리키는 key matrix의 값과 query의 값을 곱한 score를 maxQ에 넣어준다. 여기서 min_ptr, minQ는 max와 동작이 거의 유사하기 때문에, 대부분 max를 기준으로 설명이 되어 있다.
4.3.2 Iterative Candidate Selection
maxQ에서 pop 연산을 한 번 한다. 이것이 현재 가장 큰 elementwise 곱이며, 이것을 행에 알맞게 greedy_score array에 누적시킨다. pop 연산이 일어난 열의 경우 max_ptr을 업데이트 하고, maxQ에 업데이트된 새로운 max_ptr을 넣어준다.
마지막에는 greedy_score array를 탐색하며 score가 0보다 큰 (min의 경우 0보다 작은) row를 candidate에 추가한다.
Preprocessing 단계에서 미리 key matrix의 열들을 sorting하도록 한 뒤의 time complexity는 M*log(d) 이다. 여기서 M은 4.3.2.의 iteration이 일어나는 횟수로, performance와 accuracy 간 balance를 조정할 수 있는 hyperparameter 이다.
4.4 Post-scoring Approximation
위 과정을 통해 key matrix에서 중요한 row들을 candidate로 찾았고, 해당 row들에 대해 QK^T를 계산하여 full score를 계산한다. 여기서 일부 row들에 대해서는 아예 연산을 하지 않았기 때문에, score vector는 sparse 한 특성을 갖는다. 이제 이들을 대상으로 softmax 연산을 해야 하는데, low-score candidate에 대해서는 softmax와 weighted sum을 생략하고자 한다. 따라서, sparse한 score vector를 크기 순으로 sorting 하여 top scoring row에 대해서만 그 다음 연산(=softmax 이후 weighted sum with value vector)을 진행하도록 한다.
이 때 항상 일정한 수로 top scoring row를 선택할 수도 있지만, sparse score vector의 확률 분포에 따라 다르게 하는 것이 더 적합하기에 여기서는 dynamic하게 그 수를 정하도록 한다. 가장 큰 값을 갖는 row와 threshold t 를 기준으로 차이가 더 작은 element들만을 선택하여 softmax를 계산한다. 논문 결과에서는 t 대신 t를 normalize한 T를 사용하며, T의 의미는 최대값 row의 softmax 연산 결과 기준 최소 T% 이상은 되는 값들에 대해 softmax 연산을 취했다는 것이다. Scale이 바뀌었을 뿐, sparse score vector의 element를 선택하는 threshold로의 의미를 갖는다고 보면 된다.
5. A^3 with Approximation
5.1 Candidate Selection Module

SRAM 구조는 Ch 4에서 설명한 방식대로 key matrix가 sorting 되어 있는 상태를 가정한다. 또한, embedding dimension d 개의 register를 두어 각 dimension에 대한 max, min ptr을 저장한다. 2개의 multiplier (component multiplication을 수행할), component multiplication 결과를 저장해두는 d개의 circular queue, 여기서 최댓값을 찾을 수 있도록 comparator tree, 마지막으로 계산된 값들을 누적하여 저장해두는 greedy score register가 있다.
Pipeline Design
Naive하게 알고리즘을 HW로 옮긴다면 loop 내에서 maxQ 큐에서 component mult. 최대 값을 추출하는 pop 연산이 이전 iteration의 연산에 dependent 하다. 여기서는 loop의 critical path가 4 cycle이기 때문에, 각 dimension마다 미리 c개의 component mult.를 큐에 채워둔다. 그래서 priority queue인 buffer의 크기가 d개의 element만 담는 것이 아니라 4*d개의 element를 담도록 되어 있다.
연산을 하는 HW unit은 priority queue에서 최대값을 하나씩 빼는 연산을 할 것이고, 하나의 additional unit은 c cycle 마다 빈 dimension에서 최대 component mult. 값을 미리 연산하여 큐에 가져다 놓으면 된다.
Initialization
처음에 각 dimension마다 max, min ptr이 가리키는 key element와 query element에 대해 2*d 개의 mult.를 수행한다. 위에서 설명한 pipelining을 위해 이 과정을 4번 반복하여 queue를 미리 채워넣는다.
Candidate Selection
매 cycle 마다 다음 operation을 수행한다.
1) Sorting된 key matrix로부터 max_ptr이 가리키는 element를 buffer에 저장해둔다.
2) 1)에 의해 buffer된 element와 query를 곱한 뒤, 그 결과를 circular queue에 저장한다.
3) Circular queue 중 최대값을 찾은 뒤, 해당 column의 max_ptr을 업데이트 한다. (새롭게 element를 가져와야 하므로)
4) Greedy score register를 업데이트 한다.
이렇게 4단계의 pipeline step으로 구성하였기 때문에, circular queue의 크기가 dimension 마다 4개라고 이해할 수 있다. Pipeline design과 d comparator tree를 이용하여 iteration을 M cycle (초기화 제외) 만에 완료할 수 있다.
5.2 Post-Scoring Selection Module
Ch 5.1에서 설명한 candidate selection에 의해 선정된 row에 대해서만 attention 결과를 계산한 뒤, softmax로 넘기기 전에 top entry만을 선택하는 unit이다. 주요 기능은 최대 값과 나머지 entry 간에 차이를 계산하는 것이다. 이것이 만약 threshold t보다 크다면 다음 모듈로 넘겨준다. Module은 16개의 subtractor, comparator로 구성된다.
6. Evaluation
6.1 Workloads
Faceboook의 End-to-End Memory Network (MemN2N)에 대해 QA task를 실행시킨다. 주어진 질문에 대해 가장 relevent한 답변을 찾는 것이다. Key-Value Memory Network (KV-MemN2N)에 대해 Wiki movie QA task를 실행시킨다. Google BERT는 SQuAD라는 QA dataset task를 실행시킨다.
Embedding dimension은 64이며, sequence length n은 workload마다 다르다.
6.2 Accuracy Evaluation
모델의 official SW implementation과 accuracy를 비교한다. 본 논문의 approximation technique는 inference 시에만 사용하며, test set input을 사용하였다.
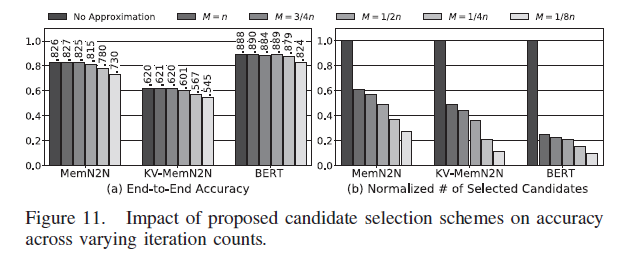
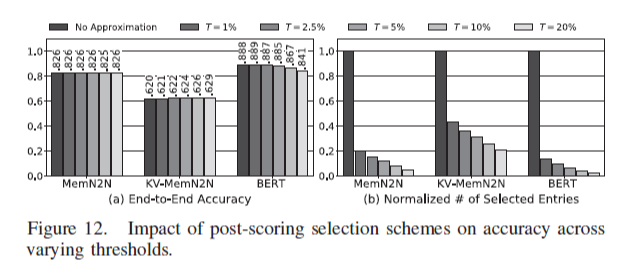
Figure 11에서는 candidate 선택하는 iteration 횟수 M을 다르게 하여 정확도를 측정하였다. 기본적으로 M이 작아질수록 더 approximate가 심해지는 것이므로 정확도가 떨어진다. Figure 12에서는 attention 결과를 pruning 하는 threshold T를 변화시켰고, T의 의미는 softmax 최대값 대비 T% 이상인 것들만 선택하겠다는 것이다. T가 클수록 거의 최대값 위주로만 선택한다는 것이므로 approximate가 심해지고 정확도가 떨어진다.
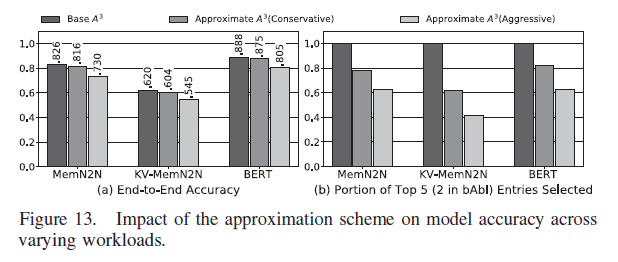
Figure 13에서는 conservative (M=1/2n, T=5%), aggresive (M=1/8n, T=10%) approximation을 적용한 결과이다. Accuracy와 함께 true top 5 entry가 approximation을 거쳐 선택된 비율을 나타내었다. M과 T는 user configurable한 hyper parameter이다.
6.3 Performance Results
1GHz에서 cycle-level simulator를 실행시켜 speedup performance를 측정하였다.

Attention 연산의 throughput의 경우 BERT는 batch matrix-matrix mult.이므로 GPU에 비해서는 낮게 나타난다. 그러나 A^3 unit을 여러 개 사용함으로써 throughput을 높일 수 있다.
Latency의 경우 approximation을 통해 연산 수를 줄이므로 latency도 줄어든다.
BERT의 경우 preprocessing overhead가 붙게 되는데, 이것은 약 11% latency의 증가를 만들어낸다. 그러나, 이를 감수하더라도 A^3는 approximation 이점을 통해 speedup을 달성하였다.
그런데, 여기서 speedup 결과를 CPU, GPU에 대해서도 표시해야 할 것 같은데, 여기서는 base A^3 HW와만 비교하였다.



