1. Introduction
Attension-based NLP 모델과 비효율성
Attention mechanism에 기반한 NLP 모델 (예를 들어 Transformer, BERT, GPT-2)들은 기존의 CNN, RNN에 비해 우수한 성능을 보인다. 그러나 attention은 GPU, CPU와 같은 general-purpose HW 환경에서 느리게 동작한다. 예를 들어, GPT-2 모델을 통해 30-token 길이의 문장을 생성하는 데에 GPU는 약 370ms 가 걸린다. 이것은 이미지 분류를 수행하는 MobileNet-V2의 6ms에 비하면 매우 큰 latency 이다. 연산 자원이 제한적인 모바일 환경의 경우 이런 모델을 이용해 interactive dialog를 수행하는 것이 거의 불가능에 가깝다.
Algorithmic Optimization
본 논문에서는 효율적인 attention inference를 위한 algorithm-architecture co-design을 제안하고, 'SpAtten'이라는 이름을 붙인다. 크게 아래와 같은 3가지의 algorithmic optimization을 제안한다.
1) cascade token pruning
2) cascade head pruning
3) progressive quantization
Cascade Token/Head Pruning
기존 가속화 기법에서 weight을 대상으로 pruning을 했던 것과 달리, 여기서는 token과 head에 pruning을 적용한다. 'Cascade' 하게 pruning을 하는데, 한 번 pruning을 한 token/head는 이어지는 layer에서도 계속 사용되지 않는다는 의미이다. Pruning 대상을 선택하기 위해 token/head를 importance score에 따라 정렬해야 하며, 이를 지원하는 HW 구조로서 high parallelism을 갖는 top-k engines 및 전용 메모리 구조, 파이프라인 구조를 함께 제안한다.
아래의 왼쪽 그림은 multihead attention의 구조이다. Input으로는 Q, K, V의 3개의 matrix가 들어오고, head 별로 scaled dot-produect attention layer를 거쳐 각각 (n, d_v) 크기의 matrix를 output으로 출력한다. 이들을 concatenate 하고, 마지막 linear layer를 통과시켜 (n, d_model) 크기의 attention output을 얻는 구조이다.

본 논문에서는 Figure 1과 같은 cascade token pruning을 제안한다. Human language가 의미없는 여러 token들로 인해 redundant한 특성을 갖는다는 직관에 의해, 중요하지 않은 token들을 제거해도 비슷한 결과를 낼 수 있다. 또한, multi-head를 사용하여 여러 linguistic dependency를 학습하고자 하지만, 이들 역시 일부는 redundant하다. 마찬가지로 중요하지 않은 head를 계속하여 제거하겠다는 것이 cascade head pruning이다.
기존 가속기의 weight/head pruning 매커니즘과 몇 가지 차이가 있다. Attention에는 trainable weight이 없고, Q, K, V 행렬 대상의 연산만으로 구성되어 있다. Q, K, V는 모두 input에 dependent한 것이므로 pruning 할 weight, head를 compile time에 결정할 수 없고, input을 받아 inference를 수행하는 시점(on the fly)에 pruning이 일어나며 input에 따라 다른 pruning이 일어난다. 긴 문장은 redundant 한 특성이 많을 것이기에 pruning ratio는 input의 길이가 길수록 더 크도록 adaptive하게 결정된다.
결과적으로 GPT-2 모델에 대해 DRAM access와 연산을 각각 3.8, 1.1배 줄일 수 있었다.
Progressive Quantization
Quantization error가 attention probability distribution과 관련이 있다. 만약 소수의 token들의 확률이 전체 확률 분포에 있어 dominant한 경우 MSB만이 필요하며, 그렇지 않고 flat distribution에 가까우면 LSB까지 필요하다. 최대 확률 값을 threshold와 비교하여 quantization 정도를 결정한다. 보다 구체적으로는, 먼저 MSB들을 fetch하여 이들을 대상으로 attention probability를 계산한다. 최대 확률 값이 threshold보다 크면 그대로 넘기고, 작으면 LSB들까지 fetch하여 다시 attention probability를 계산한다.
Memory-bounded 모델에 대해 연산량과 메모리 접근을 trade 함으로써 성능 이득을 얻을 수 있고, 메모리 접근을 약 5.1배 줄일 수 있었다.
Comparison with Previous Related Works
Attention 가속기에 대한 선행 연구로는 다음 2가지가 있는데,
T. Ham, A^3: Accelerating Attention Mechanisms in Neural Networks with Approximation, HPCA, 2020
H. Jang, MnnFast: a fast and scalable system architecture for memory-augmented neural networksm ISCA, 2019
이들은 3가지 한계점이 있으며, 본 논문의 해결 방안을 통해 이를 극복할 수 있다.
1) 기존 attention 가속기들은 연산 이전에 모두 DRAM에서 꺼내오기 때문에 computation-bounded 모델에 대해서는 성능 향상을 얻지만, memory-bounded 모델에 대해서는 그렇지 못하다. 하지만 본 논문의 경우, 위의 algorithmic optimization을 통해 QKV의 DRAM 접근을 줄인다.
2) Head pruning 역시 DRAM 접근과 연산의 측면에서 성능 향상을 얻을 수 있는 기회이며, 본 논문에서는 이를 처음으로 포함하였다.
3) Computation 측면에서도 추가적인 가속이 가능한데, 기존 pruning이 layer 내에서 local하게 일어난 것에 반해 본 논문에서 제안하는 pruning은 global하게 일어나서 이후 layer에서도 모두 skip 되도록 하였기 때문이다.
Results Summary
BERT, GPT-2 모델을 30개의 벤치마크 데이터 셋에 대하여 inference를 수행하였으며, accuracy loss 없이 DRAM 접근을 줄였으며, 기존 가속기, GPU, CPU 등과 비교하였을 때 speedup, energy saving의 결과를 얻었다.
2. Background and Motivation
2.1 Background
Attention-Based NLP Models
NLP task는 크게 2가지로 분류할 수 있는데, 1) Discriminative task란 input sequence를 summarize하여 prediction을 하는 것으로, 구체적인 task 예시로는 token-level 또는 sentence-level의 classification이 있다. 2) Generative task란 input sequence를 summarize한 후 새로운 token들을 생성 (generate)하는 것으로, 구체적인 task 예시로는 language modeling (chatGPT처럼 문장을 이어서 생성하는 것), machine translation 등이 있다.
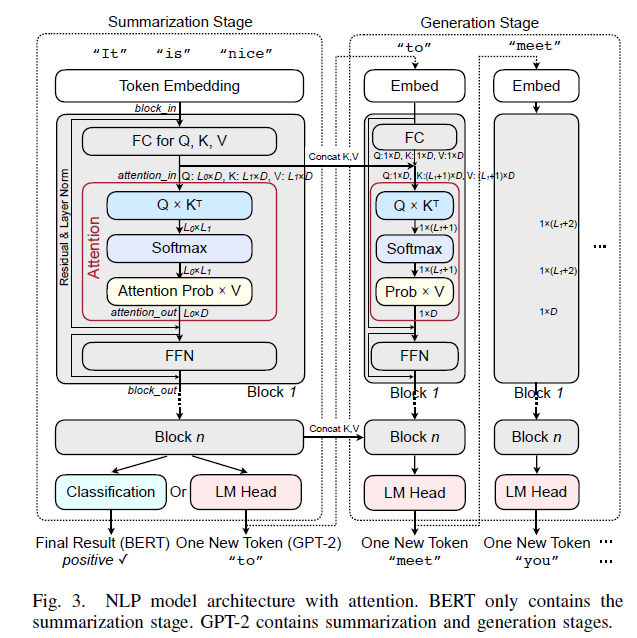
본 논문에서는 discriminative model로서 BERT를, generative model로서는 GPT-2를 선택하여 이후 논의를 전개한다. 이들의 구조는 Figure 3과 같으며, BERT는 summarization stage만으로, GPT-2는 generation stage도 포함한다.
먼저 summarization stage를 보면, input sequence가 embedding 되어 행렬 형태로 block 1에 들어온다. (Figure 3의 block_in) FC layer를 거쳐 Q, K, V 3개의 행렬을 얻고, 이들이 h개의 head들로 split 되어 들어간다. 각 head 내에서 QKV 행렬들로 attention 연산을 하여 attention_out 을 얻는다. 각 head 별 attention_out의 크기는 (L_0, D)이며, 이들이 하나로 concatenate 되어 최종적으로는 (L_0, D_in)의 크기가 된다. 이후 add&norm을 수행한 뒤, FFN (Feed-Forward Network)를 거쳐 block_out을 얻는다. 이 과정이 하나의 block 안에서 이루어지는 연산이고, BERT-Base 모델의 경우 12개의 block을 쌓는다. BERT의 경우 classification layer를 통과해 input sequence에 대한 classification prediction을 얻으며, Figure 3에서처럼 문장에 대한 positive/negative 분류를 출력한다. 반면 GPT-2의 경우 LM (Language Modeling) head를 거쳐 새로운 token을 출력하고, 이 token이 다시 피드백되어 generation stage로 들어간다.
Generation stage는 2가지 측면에서 summarization과 다르다. 1) 각 iteration에서 가장 최근에 생성된 하나의 token만을 처리한다. 2) K, V는 summarization stage의 K, V를 그대로 가져와 현재 K, V와 concat 하여 사용한다. 이 때 Q는 가져오지 않고 (1, D) 크기의 vector이다. 이들이 attention block의 input으로 들어와 마찬가지의 과정을 거져 block_out을 만들고, 여러 개의 block들을 거쳐 새로운 token을 만들어낸다. 이 과정을 <eos (end of sentence)> token이 출력될 때까지 반복한다.
Generation iteration 한 차례 실행 시간이 summarization의 실행 시간과 거의 비슷한데, summarization의 경우 input sequence를 batch 단위로 처리하기 때문이다.
Attention Mechanism


Attention mechanism은 Algorithm 1과 같다. 여기서 Q, K의 행렬 곱으로 attention score가 계산되고, 이것의 의미는 두 개의 token들이 얼마나 서로 관련되어 있는가이다. 여기에 row-wise softmax 연산을 한 것을 attention probability라고 부른다. Figure 5를 보면 more은 than과 매우 높은 관련성을 갖는다. V와 곱해 head의 feature를 얻게 되며, 이것은 각 token 별로 관련이 높은 token의 정보를 위주로 fetch 한다는 의미를 갖는다.
Multi-head attention은 이러한 head 여러 개(예를 들어 BERT-Large, GPT-2-Medium은 16개의 head)를 갖는 구조이며, 이들이 concat 되어 attention layer의 output을 만들어낸다.
2.2 Motivation

Figure 2 왼쪽 그림에서 GPT-2의 end-to-end latency breakdown을 보면 attention이 약 50% 이상의 latency를 차지한다. FLOPS로 보면 약 10%를 차지하는 것에 비해 latency가 큰 특성을 보인다. Figure 2 오른쪽 그림은 attention layer 내부를 breakdown 한 것인데, 연산보다 data movement operation이 큰 비중을 차지한다. CPU, GPU와 같은 프로세서들이 행렬 곱은 잘 최적화할 수 있지만, 그에 비해 복잡한 메모리 연산은 효율적으로 처리하지 못해 bottleneck이 되는 것이다.
FC layer는 GPU, CPU, tensor accelerator 등을 통해 최적화할 수 있기 때문에, 여기서는 attention layer를 타겟으로 하는 가속기를 설계하고자 한다.
5. Evaluation
5.1 Evaluation Methodology
Tools
1) SpinalHDL 언어를 이용해 구현하였고, 이를 RTL로 컴파일하였다. SpinalHDL이란 디지털 하드웨어를 묘사하는 언어인데, Verilog, VHDL, SystemVerilog에 비해 문법, 특징 면에서 더 편리한 프로그래밍을 제공한다. Area/performance 분석을 할 수는 없는데, 대신 코드 작성 후 VHDL, Verilog 파일을 만들어낼 수 있다. 아래에 github 링크가 있다.
링크: https://github.com/SpinalHDL/SpinalHDL
GitHub - SpinalHDL/SpinalHDL: Scala based HDL
Scala based HDL. Contribute to SpinalHDL/SpinalHDL development by creating an account on GitHub.
github.com
2) 시뮬레이션은 Verilator를 사용하였고, Verilog, SystemVerilog 모두 지원한다. HBM 모델링은 Ramulator라는 DRAM 시뮬레이터를 이용하였다. SpinalHDL을 이용해 연산 logic에 대한 코드 작성을 하고, RTL로 컴파일하여 Verilog 파일을 얻고, 그 뒤에 이를 Verilator로 돌려보면서 cycle number를 얻는다.
3) 구현한 computational logic의 area/power consumption estimation 하기 위해 synthesize 하였고, 이 때 TSMC 40nm 라이브러리를 이용하였다. SRAM, HBM의 power consumption은 각각의 시뮬레이터로부터 얻는다.
Evaluation Baselines
성능 측정의 baseline으로 삼을 HW 플랫폼으로는 서버 GPU, 모바일 GPU, 서버 CPU, 모바일 CPU, SOTA 가속기 (A3, MNNFast의 2개)가 있다.
GPU, CPU에서 돌릴 때는 PyTorch로 attention을 구현하고, 각각에 대한 라이브러리(GPU는 cuDNN, CPU는 MKL)를 이용하여 실행시킨다. Latency 측정과 power monitoring은 적절한 라이브러리 함수를 이용한다. 모바일 HW의 경우 power meter를 이용한다.
Model and Workload
모델은 discriminative model로서 BERT-Base, BERT-Large를, generative model로서 GPT-2-Small, GPT-2-Medium을 검증하며, 이들을 대상으로 여러 dataset과 task를 실행시킨다.
5.2 Experimental Results
Throughput, Power, and Area
본 논문의 가속기는 token, head pruning을 통해서 연산량과 DRAM 접근 횟수를 감소시킨다.
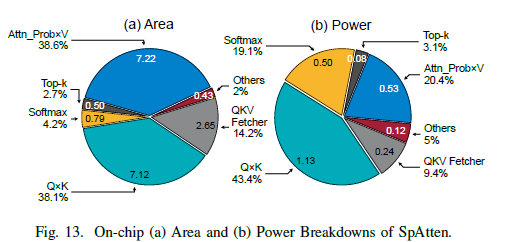
Area, power breakdown을 보면, (Q, K) 곱셈 모듈, (Attention_Prob, V) 곱셈 모듈이 가장 많은 비율을 차지하는데, 이들이 가장 computational intensive한 모듈이기 때문이다. Top-k 모듈은 매우 효율적으로 동작하며, area, power 중 매우 작은 비율만을 차지한다.
Comparisons with CPUs and GPUs
Figure 14는 speedup, 에너지 효율성 측면에서 CPU, GPU와의 비교 결과를 벤치마크 별로 제시한다.
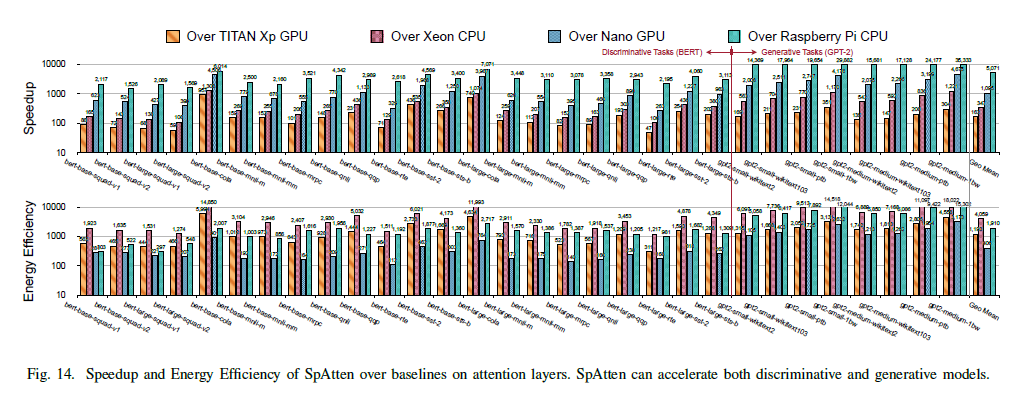
높은 speedup을 달성할 수 있는 이유는 parallelization과 pipelined datapath 이다.
에너지 효율성을 높게 달성할 수 있는 주요 요인은 DRAM 접근 횟수를 줄인 것이다. Specialized datapath는 SRAM fetch도 줄인다.
Comparisons with A^3 and MNNFast
A^3에서는 key vertor들을 sorting 하고 크기를 기준으로 일부만을 이용하여 query와의 행렬 곱을 수행하고, partial attention score을 얻는다. 이 중 score가 threshold보다 작은 것들은 pruning 된다. MNNFast는 attention probability가 threshold보다 작은 V vector들을 pruning 한다.
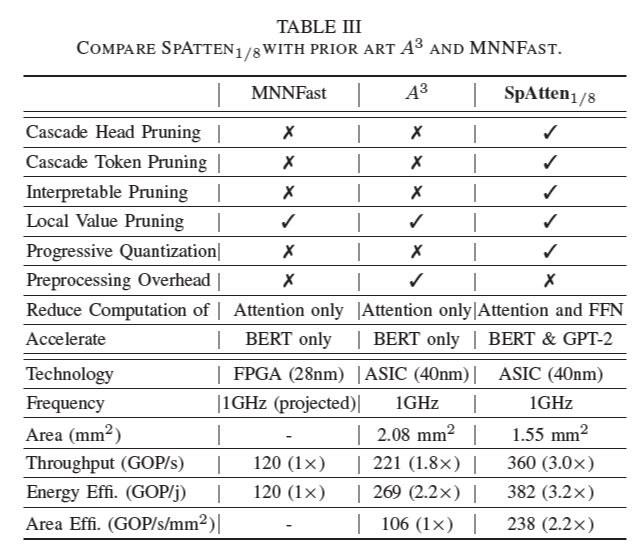
Table 3는 SpAtten과 기존 가속기 A^3, MNNFast와의 비교 결과를 나타낸다. 구체적인 비교 사항은 다음과 같다.
1) 기존 가속기 2개는 pruning 판단 이전에 우선 DRAM fetch는 모두 해 오기 때문에, DRAM 접근 횟수를 줄일 수 없다. 따라서 BERT와 같은 computation-bound 모델은 가속이 가능하나, GPT-2와 같은 memory-bounded 모델은 가속할 수 없다.
2) A^3의 경우 key vector를 sorting 해야 하는데, 이것은 pre processing overhead이다.
3) A^3의 pruning은 local하지만, SpAtten의 pruning은 global하기 때문에 FFN의 연산량도 줄일 수 있다.
4) Cascade token pruning은 이해 및 시각화가 직관적이다. (Figure 22)

5) SpAtten에서 head pruning과 progressive quantization을 처음으로 제시하였다.



