1. Introduction
(1) Topic of the paper
On-chip 캐시에서 miss가 일어나는 load request는 off-chip의 메인 메모리로 가게 되고, 이것은 고성능 OoO(Out-of-Order) 프로세서의 성능을 제한하는 요소로 작용한다.
(2) Current related works and limitations
이것을 해결하기 위한 기존의 시도는 크게 2가지로 분류할 수 있다. 첫째, HW prefetcher를 구현해 메모리 주소 패턴을 학습하도록 하여 코어에서 load request를 요청하기 이전에 미리 메인 메모리로부터 데이터를 가져오는 것이다. 둘째, on-chip 캐시 계층 구조를 확장시킨다. 그러나, 이러한 접근법에는 한계점이 존재한다. 첫째, HW prefetcher는 다양한 워크로드에 대해 평균적으로 약 절반 정도의 off-chip load request를 예측할 수 있다. 왜냐하면 각 프로그램 내의 불규칙한 메모리 접근 패턴을 학습하는 것은 어려운 일이기 때문이다. 둘째, on-chip 캐시 계층 구조의 확장으로 인해 off-chip load request의 latency 중 on-chip cache 접근이 차지하는 비율이 높다. On-chip 캐시 계층 구조의 확장은 on-chip cache에서 더 많은 load request를 커버함으로써 off-chip load request의 수를 줄일 수 있지만, 한편으로는 캐시 접근 latency가 기본적으로 길어지는 단점이 있다.
(3) Solution and challenge
Load request가 off-chip으로 갈지를 예측하여, 만약 off-chip으로 예측한다면 캐시 접근과 동시에 (concurrently) 메인 메모리로의 fetching을 시작함으로써 캐시 접근에 걸리는 latency를 없애는 효과를 얻을 수 있다는 것이다
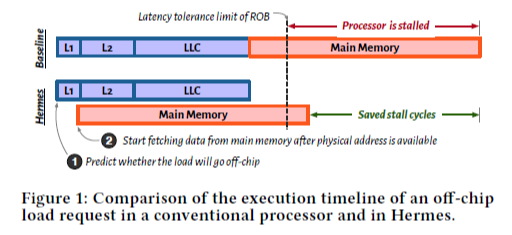
그러나 이것은 예측이 성공했을 때 얻을 수 있는 이점이고, 만약 off-chip으로 예측했으나 실제로 on-chip인 경우는 불필요한 메인 메모리 요청을 하여 메모리 BW를 낭비하고 오히려 추가적인 latency가 발생한다. 따라서 off-chip 예측의 정확도를 높이는 것이 중요하다. Challenge가 두 가지 있는데, 첫째로 prefetcher의 존재로 인해 약 1/20 비율의 load request만이 off-chip으로 가게 되는데, 이러한 적은 비율의 데이터를 가지고 예측에 대한 학습을 해야 한다. 둘째로, off-chip 예측의 정확도는 prefetcher의 존재에 따라 달라지기 때문에, 프로그램의 특성 뿐만 아니라 prefetcher에 대해서도 학습을 해야 한다.
본 논문에서는 perceptron-based off-chip 예측기 (POPET이라는 이름을 붙임)를 제안하며, PC의 sequence, load request의 byte offset 등 여러 프로그램 feature를 이용해 학습을 하게 된다. 런타임에 프로세서에 의해 load request가 들어오면 예측기가 해당 load request가 off-chip으로 갈지 여부를 예측한다. 만약 off-chip으로 예측하면 메인 메모리 controller에게 Hermes request를 보낸다. 이것은 on-chip 캐시 계층을 접근하는 일반적인 load request와 동시에 처리된다.
2. Motivation
메인 메모리의 long latency로 인한 성능 한계를 극복하기 위하여, 1) on-chip 캐시 계층 구조를 더 크게 확장하거나, 2) 메모리 요청을 하기 이전에 HW prefetcher가 미리 on-chip 캐시로 데이터를 이동시키도록 하는 것이 연구되어 왔다. 하지만 이러한 방식들에는 한계점이 존재한다.
첫째, 여전히 load request의 많은 비중은 prefetcher에 의해 처리되지 못한다. Figure 2를 보면 평균적으로 HW prefetcher는 약 50% 정도의 off-chip load request를 커버함으로써 성능 향상에 기여한다. 그러나 non-prefetched load request 중 약 71%는 ROB로부터의 명령어 retirement를 blocking하는 load request로서, 성능 향상을 제한하는 요소로 작용한다.
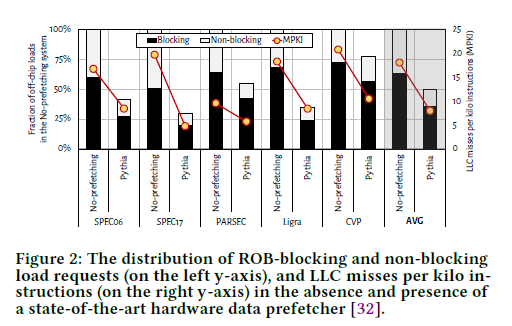
둘째, off-chip load latency 중 상당 비율이 on-chip cache 계층 구조를 접근하는 데에 사용되고 있다. 캐시 계층 구조가 확장되면서 한편으로는 off-chip으로 보내질 load request의 상당 부분을 ob-chip에서 커버함으로써 코어의 성능을 향상시킨다. 하지만 다른 한편으로는 off-chip으로 보내지기 이전에 모든 on-chip 캐시를 접근해야 하므로, off-chip latency에 있어 on-chip 캐시 접근에 걸리는 latency가 늘어나는 단점이 생긴다. 예를 들어 Intel Alder Lake 코어의 경우, LLC (Last-Level Cache)의 load-to-use latency는 약 14ns(=55 cycles at 4GHz core) 이다. 여러 워크로드에 대해 실험을 해본 결과, off-chip load에 의해 코어가 평균적으로 약 147 cycle stall이 일어나는데, 그 중 약 40%는 on-chip 캐시 접근에 의한 latency로서, 본 논문의 아이디어에 의해 제거될 가능성이 있는 latency이다. 앞으로 on-chip 캐시의 크기와 복잡성이 더 증가함에 따라 이러한 문제는 더 커질 것이다.
3. Goal and Key Idea
3.1 Key Idea & Potential Benefits
여기서는 본 논문의 솔루션에 의한 이론적인 최대 성능 향상을 보이고자, 이상적인 Hermes를 가정한다. 즉, 모든 off-chip load request를 예측하여, L1 캐시 접근 후 physical address가 알려진 이후에 나머지 on-chip 캐시 계층 접근과 동시에 메인 메모리 request를 실행하는 방식이다. 이렇게 함으로써 off-chip load request 시 항상 L1 캐시보다 하위에 있는 나머지 캐시를 접근하는 데에 걸리는 latency를 없앨 수 있다. Figure 4는 Hermes와 HW prefetcher가 함께 사용되었을 때 얻을 수 있는 이상적인 speedup을 보여준다.
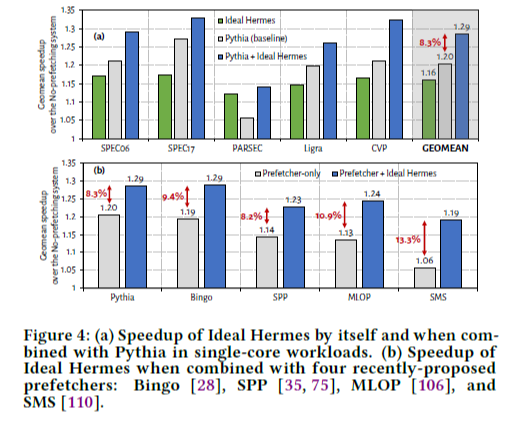
여기서 이 둘이 성능 향상에 기여하는 차이점이 다른데, Pythia와 같은 HW prefetcher는 load request가 일어나기 전에 미리 메인 메모리에서 캐시로 데이터를 prefetch함으로써 off-chip으로 가는 load request의 비율을 낮추고자 하는 것이고, 본 논문에서 제안하는 Hermes (off-chip predictor)는 off-chip을 가긴 가는데 캐시 접근과 동시에 수행함으로써 off-chip load latency를 낮추고자 하는 것이다.
3.2 Key Challenge
(1) Accuracy, Coverage
Hermes의 성능 향상은 예측 정확도에 의존한다. 예측 정확도를 여기서 accuracy, coverage의 두 가지로 구분한다. 먼저, off-chip으로 예측한 request 중 실제로 off-chip으로 간 비율을 accuracy라고 하며, 낮은 accuracy의 경우 불필요한 메인 메모리 request를 함으로써 latency가 오히려 증가할 뿐만 아니라 메모리 BW overhead가 발생한다. 다음으로 off-chip으로 가야 하는 request 중 예측을 한 비율을 coverage라고 하며, 낮은 coverage일수록 이상적인 latency 성능 향상과 차이가 많이 날 것이다. 다만 이 경우 기존의 경우에 비해 손해가 발생하지는 않는다.
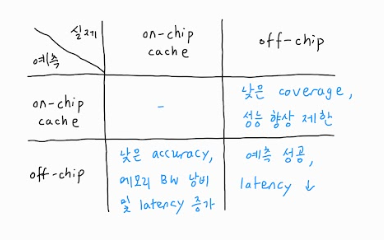
(2) 2 Challenges
이 때 높은 accuracy, coverage를 달성하는 predictor를 설계함에 있어서 두 가지 challenge가 있다. 첫째, 워크로드의 전체 load request 중 실제 off-chip으로 가는 request의 비율이 약 5% 정도로 낮아서 predictor가 워크로드의 load behavior를 충분히 학습하기가 어렵다. (= 학습 데이터의 양을 충분히 확보하기 어렵다) 이것은 HW prefetcher에 존재로 인해 off-chip으로 가야할 request들 중 일부가 on-chip 캐시에서 커버되기 때문에 그렇기도 하다. 둘째, off-chip load의 예측 가능성은 data prefetcher의 존재에 따라 달라진다. Load request의 off-chip 여부는 프로그램의 특성에 따라 달라지기도 하지만 prefetcher의 동작에 따라서도 달라지므로, predictor는 prefetcher의 동작도 학습해야 한다.
여기서는 perceptron 기반의 예측기를 설계하였고, PC 값의 sequence, load request의 byte offset, load address의 page number 등의 특성을 이용하여 예측기를 학습시켰다.
5. Hermes: Design Overview
코어, 메모리 계층 구조, off-chip 예측기 POPET이 포함된 메모리 시스템의 overview는 Figure 6과 같다.
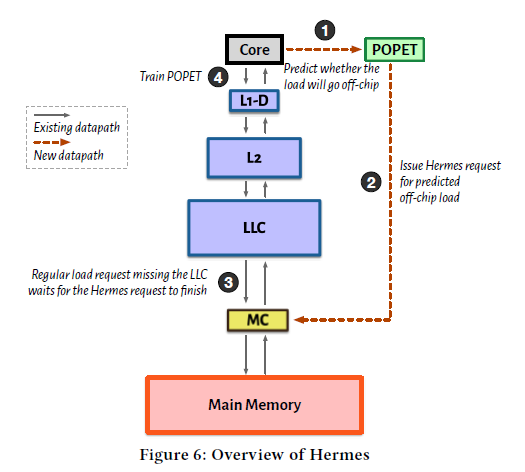
1) 프로세서의 모든 load request에 대해 POPET은 off-chip으로 갈지 여부를 예측한다. POPET 모듈은 PC 값, load 주소 offset 등 예측에 필요한 feature들을 input으로 받아 off-chip 여부를 output으로 내보낼 것이다.
2) 만약 off-chip을 예측했다면, physical address를 얻은 직후에 메인 메모리로 Hermes request를 보낸다. 이 Hermes request는 일반적인 regular load request와 동시에 처리된다. (구현의 관점에서 보면 메인 메모리 BW에 대한 요청을 보내는 component가 새로 하나 생긴 것)
3) 예측이 맞은 경우 (실제로도 off-chip request) regular load request는 LLC에서 캐시 miss가 나고 메인 메모리 controller에게 요청을 보낼 것이다. 그런데 이 때 이미 Hermes request에 대한 동작이 진행 중이므로 Hermes request에 대한 응답이 올 때까지 대기한다. (메인 메모리 controller는 동일한 주소에 대한 regular/Hermes request를 구분하여 이 상황을 판단할 수 있어야 함. 이미 Hermes request가 있다면 regular request는 보내면 안 됨.)
예측이 틀린 경우 Hermes request는 메인 메모리로부터 응답이 도착하지만 이 주소에 대한 regular load request는 없다. 이 때는 캐시 coherency를 유지하기 위해 데이터를 캐시에 저장하지 않는다. (메인 메모리가 on-chip 캐시에 데이터를 전달할 때는 regular load request 여부를 확인해야 함. 또한 regular load request이더라도 Hermes request가 있었다면 응답 올 때까지는 core가 기다려야 함)
4) Regular load request가 코어에 도착하면 실제 off-chip 여부를 바탕으로 POPET을 train한다.
6. Hermes: Detailed Design
6.2 Hermes Datapath Design
6.2.1 Issuing a Hermes Request
Load request를 off-chip으로 예측하면, physical address가 만들어진 후에 메인 메모리로 request를 전송한다. 메인 메모리 controller는 Hermes request를 read queue에 넣고, 메인 메모리의 scheduling policy에 따라 요청된 주소의 데이터를 메인 메모리로부터 가져온다. 만약 예측이 맞아서 실제로 off-chip으로 가는 요청이었다면 LLC에서 miss가 발생할 것이다. 이 때 regular request는 바로 메인 메모리에 데이터 요청을 하는 것이 아니라, read queue를 탐색해 해당 주소에 대한 Hermes request가 존재하는지를 먼저 확인해서 만약 존재한다면 기다린 후 데이터를 코어로 보낸다.
이 때, Hermes request의 latency가 성능에 있어 중요하다. On-chip 캐시를 계층을 따라 접근하는 regular load request에 비해서는 latency가 적겠지만, on-chip network route를 타고 request가 이동하기 때문에 latency가 발생한다. 여기서는 Hermes request latency를 일정 범위 안의 값으로 가정하고 이에 대해 실험을 하였다.
6.2.2 Returning Data to the Core
Hermes request에 대한 데이터가 메인 메모리로부터 return하면, 메인 메모리 controller는 read queue에 같은 load 주소를 갖는 regular load request가 있는지를 확인해서 존재하는 경우에만 LLC로 데이터를 보낸다. 만약 존재하지 않는다면 on-chip으로 간 load request를 잘못 예측한 것이고, 따라서 LLC로 보내지 않음으로써 cache coherency를 유지한다.



