Abstract
컴퓨터 시스템의 데이터 이동은 load/store interface로 추상화가 되어 있는데, 이렇듯 소프트웨어가 데이터 이동을 직접 확인할 수 없는 것은 데이터 이동에 의한 실행 시간이나 에너지 비효율성 문제의 근원이 된다. 이에 대해 기존 연구들은 custom 하드웨어를 추가하곤 했는데, 본 논문에서는 HW-SW interface를 변화시킴으로써 이를 해결한다. 논문의 솔루션(tako)은 소프트웨어가 데이터 이동을 직접 확인하고 중재하는 것을 가능하게 하는데, cache miss, eviction, writeback가 발생할 때 소프트웨어 callback을 발생시키도록 한다. 이 때 software callback은 캐시와 물리적으로 근처에 있는 reconfigurable dataflow engine에서 실행된다.
1. Introduction
Background and Limitations of Current Works
데이터 이동은 컴퓨터 시스템의 성능과 에너지 측면에서 큰 부분을 차지하는 요소인데, 이상적으로는 HW와 SW가 함께 제어하도록 하는 것이 최적일 것이다. 하지만, 현재의 mainstream ISA에서 소프트웨어는 read, write 명령어를 수행하고, 실제로 데이터를 언제, 어느 물리적 위치로 옮길지는 하드웨어가 전적으로 결정하도록 되어 있다. 소프트웨어가 메모리에 대한 최적화를 수행하는 데에 한계가 있는 상황 속에서, 기존 연구들은 specialized memory hierarchy를 설계함으로써 데이터 이동을 줄이는 방식으로 진행되어 왔다. 하지만, 이러한 방향의 연구의 근본적인 한계는 general-purpose CPU 메모리 계층 구조를 바꾸는 것은 새로 custom logic을 추가하는 것이기에 매우 비싸다는 것이다. 가속기들은 특정 application에 대해서만 성능 향상을 이루기 때문에, 비싼 cost를 justify 하기 어려운 경우가 많다. 주로 cache replacement나 prefetch 같은 부분에 대해서만 제한적으로 최적화가 이루어지고 있다.
Idea
SW/HW에 대한 새로운 투자가 justify 되기 위해서는 보다 general-purpose architecture를 제안하는 것이 중요하다. Architecture가 데이터 이동에 대해 더 많은 정보를 드러내야(expose) SW 입장에서 데이터 이동과 관련된 최적화를 수행할 수 있다. 이것을 polymorphic cache hierarchy라고 부른다. 기존에는 데이터 이동과 관련된 부분을 HW가 전적으로 담당했다면, SW가 이를 제어할 수 있도록 함으로써 이점을 얻는다는 것이 핵심 아이디어이다.

Figure 1은 tako 솔루션에 대한 overview 그림이다. 먼저, SW는 tako에 phantom address range를 등록한다. 이 phantom address range에 있는 데이터는 off-chip memory로 이동하지 않고, 오직 캐시에만 존재한다. 이 영역의 데이터에 대한 miss, eviction, writeback은 메인 메모리가 아닌 SW callback에 의해 처리된다. SW callback은 이 주소 영역에 대한 load, store semantic을 정의해야 하며, 이를 통해 SW 입장에서 캐시의 동작을 원하는 대로 re-purpose할 수 있는 것이다. 최근의 near-data computing architecture에서와 같이, tako 역시 캐시 근처에 programmable engine이 있어서 SW callback은 여기서 처리된다. (이것은 abstract에서 'Reconfigurable Dataflow Engine' 이라고 표현된 것과 같은 개념이다)
2. 'tako' Overivew
tako라는 솔루션은 SW와 HW 모두 포함한다. 먼저, SW에서는 cache-triggered callback을 통해 데이터 이동에 대한 visibility를 주는 interface를 제공한다. 다음으로, HW에서는 callback을 scheduling하고 처리할 수 있어야 한다. 위에서 언급된 것처럼 이러한 HW 연산은 near data에서 이루어진다.
Design rationale
tako는 캐시 miss, eviction이 일어날 때 SW가 이를 확인하여 직접 필요한 operation을 명령함으로써 개입할 수 있도록 한다. Cache logic이 전적으로 HW로 구현되었을 때와 달리 application에 맞게 최적화된 메모리 operation을 명령할 수 있다는 장점을 갖는다.
Interface
SW callback은 phantom address 영역에 대해서만 적용되며, normal data 영역의 load/store interface에는 영향을 주지 않는다. 캐시 miss가 일어나면 onMiss 라는 callback이 발생하며, SW가 요청된 cache line을 채우게 된다. 캐시에 데이터가 올라간 뒤에는 CPU에서 다른 데이터와 같이 read, write을 할 수 있는 상태가 된다.
Architecture
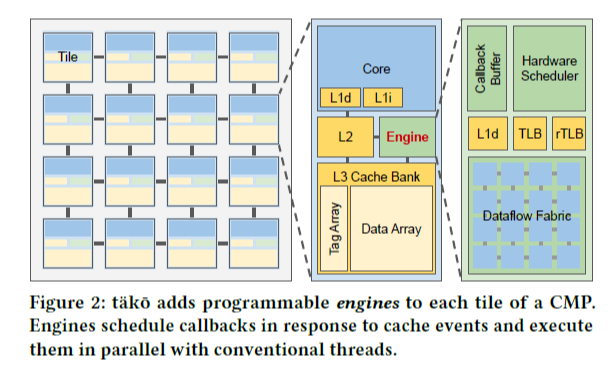
tako 시스템의 전반적인 architecture은 Figure 2와 같다. SW callback 연산의 특징은 짧고, 반복되며, 전체 cache line들에 대해 같은 operation을 수행하는 경향이 있다. 이러한 경향성에 대한 분석으로부터 microarchitecture는 SIMD functional unit들로 구성되어 있다.
3. Motivation
메모리 계층에 대한 최적화는 deadlock 상황에 놓여 있다. 특정 어플리케이션에 대해 최적화된 메모리 구조가 연구되어 왔지만, 소프트웨어의 요구가 강하지 않은 상황 속에서 하드웨어 회사들은 이러한 하드웨어를 실제로 생산하기를 주저한다. 하드웨어 support가 없는 상황 속에서 소프트웨어 회사들은 프로그램을 다시 작성하지 않을 것이다. 따라서 현재는 load-store interface를 유지하는 최적화만이 실제로 이루어지고 있다.
본 논문은 보다 general한 architecture를 제공함으로써 이러한 deadlock 상황을 해결하고자 한다. 먼저, 여기서는 논문의 솔루션을 이용해 SW로 데이터 이동을 최적화하는 예시를 제안한다.
3.1 Example program: Lossy compression
데이터가 캐시로 이동하는 것과 관련한 최적화 연구가 그동안 이루어져 왔는데, 그 방법 중 하나는 data compression이다. 아래의 예시 코드를 살펴보자.


두 개의 array가 있고, bases는 64-bit 단위, deltas는 8-bit 단위로 데이터를 저장하고 있다. Index는 deltas 배열의 8-bit 단위로 증가하는데, 이 때 8개의 이웃한 index끼리는 base 데이터를 서로 공유한다. 예를 들어, index 0~7은 모두 bases의 0번째, index 8~15는 모두 bases의 1번째 데이터를 접근한다. deltas의 8-bit은 상위 4-bit은 exponent를, 하위 4-bit은 mantissa로 encoding되어 있다. 주석으로 표시되어 있는 것과 같이, 먼저 이렇게 encoding되어 있는 데이터로부터 실제 데이터 값을 계산한다. 그 후, total이라는 변수에 누적해 전체 데이터의 합을 구하는 프로그램이다.
이렇게 data compression을 하면 원래 64*N 만큼 필요한 메모리 공간을 16*N으로 줄일 수 있어 보다 효율적으로 데이터를 저장할 수 있다. 표준적인 data compression이 아니라 위와 같은 lossy compression은 하드웨어에서 구현될 수 없고 위 코드와 같이 SW로 작성되어야 한다.
그러나 이와 같은 방법은 2가지 문제점이 있다. 첫째, 데이터를 변환하는 과정이 모두 CPU에서 돌아가므로 time, energy 측면에서 모두 비효율적이다. 둘째, 만약 이 데이터가 다시 이용되어야 한다면 이러한 변환 과정을 다시 거쳐야 한다.
3.2 tako to the rescue!

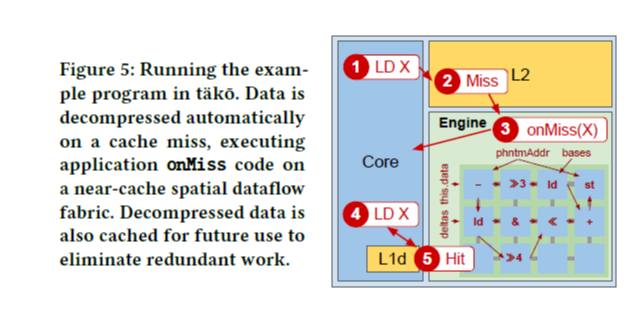
tako는 decompressed data가 저장될 phantom address 영역을 새롭게 할당한다. (위 코드에서는 data라는 이름의 int64 array) 프로그램에서 decompressed data를 접근하려고 할 때 이 데이터가 캐시에 없어서 cache miss가 난다면, onMiss callback이 실행된다. Figure 4 코드에서 보는 것과 같이, onMiss callback은 SW에 의해 정의되며, 여기서는 예시에 맞게 phantom address 영역의 cache line을 decompress하도록 작성되었다. Figure 4의 onMiss() 함수를 보면 miss가 난 addr를 받아서 index를 계산하고 decompress하는 코드인데, 이것은 모든 캐시 라인에 대해 parallel하게 실행될 수 있다. 따라서, application code의 for 문으로 데이터에 반복적으로 접근할 때, 처음에 onMiss() callback이 한 번 실행된 이후로는 계속 cache hit이 발생함으로써 보다 효율적으로 메모리 operation을 할 수 있게 된다.
3.3 Results and comparison to prior work
이 프로그램에 대한 tako의 성능을 제시하기 위해, tako를 포함한 총 3가지 방법의 성능을 비교한다. Figure 6은 speed up과 energy 소모량에 대한 비교를 그림으로 제시한다.
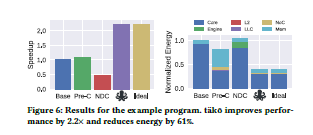
첫째, pre-compute version이다. 이 방법의 경우, figure 3의 코드를 그대로 실행하는 것인데, vector instruction을 이용하면 cache line 전체(64B=8개의 개별 데이터)를 묶어서 parallel하게 처리할 수 있다. 여기까지가 논문의 설명인데, 각 단계별로 나누어 조금 더 생각해보기로 한다. 먼저, 처음 데이터를 접근할 때는 L2 캐시에 있는 raw data를 L1 캐시로 가져와서 decompression 연산을 수행하여 data를 얻는다. 그러나 decompressed data는 하나의 변수에 덮어쓰고 있으므로, 연산(위 예제에서는 덧셈)을 수행한 뒤에는 없어지게 된다. 이후에 다시 data에 접근하고자 한다면, raw data의 경우 locality에 의해 caching 되어 있을 수 있지만, decompression 연산은 다시 수행해야 한다.
둘째, near-data computing(이하 NDC) implementation이다. 이 경우에도 figure 3의 코드를 실행하는데, 코어가 직접 실행하지 않고 L2 engine에서 실행되도록 offloading한다. (L2 engine은 본 논문의 RDE과 비슷한 개념이라고 이해하고 넘어간다) 즉, pre-compute에 비해 raw data의 L2<->L1 캐시 간 데이터 이동으로 인한 overhead를 줄일 수 있다는 이점이 있다. 하지만 결과를 보면 오히려 pre-C에 비해 speedup이 안 좋은데, 그 이유는 L1 cache의 locality를 활용하지 못했기 때문이고, 항상 L2 engine에서 돌리는 것이 최적화는 아니다.
셋째, tako이다. tako는 자주 접근되는 데이터의 decompress된 결과를 저장해둠으로써 decompression 연산의 수를 줄일 수 있다. 따라서 NDC에서 얻을 수 있는 near data computing의 장점을 살림과 동시에 locality도 활용할 수 있게 되는 것이다. 기본적으로 cache-triggered이므로, cache miss 시에만 효율적으로 수행될 수 있다.
3.4 Discussion
Decompression과 같이 캐시 계층 구조에서의 데이터 이동과 관련된 최적화 기법은 tako의 onMiss, onEviction, onWriteback callback을 작성함으로써 구현할 수 있다. 이러한 callback은 SW로 작성되고, tako의 general purpose HW에서 실행된다. tako 솔루션은 microarchitectural한 것이 아니며, design에 관한 것이다. Callback은 application 코드의 일부로 생각할 수 있으며, 이것은 SW thread와 병렬적으로 수행될 수 있는 HW thread를 실행시키는 코드이다.



