논문 정보는 아래와 같다.
Tian Guo, Cloud-based or On-device: An Empirical Study of Mobile Deep Inference, IEEE International Conference on Cloud Engineering, 2018
Introduction
2 Design Choices: Cloud-based & On-device
Deep neural network(이하 DNN)를 학습시키는 것은 매우 많은 데이터와 연산 능력을 요구하기 때문에, 주로 cloud GPU를 활용하여 이루어진다. 한 번 학습이 완료된 이후, 새로운 input을 대상으로 한 inference는 학습에 비하면 시간이 적게 걸린다. 이렇게 미리 학습된 모델은 서버에 저장되어 private 또는 public 용도로 사용될 것이다. 예를 들어, 서버에 object recognition을 수행할 수 있는 DNN이 학습되어 있다면, 이를 활용하는 어플리케이션의 개발자는 cloud가 제공하는 API에 맞춰 딥 러닝 task를 서버에 보냄으로써 프로그램을 동작시킬 수 있다. 아래의 Figure 1과 같다.
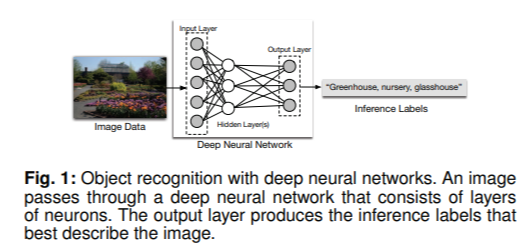
서버가 제공하는 API가 어떤 형태인지는 자세히 나와있지는 않으나, 가장 단순하게는 object recognition의 대상이 되는 이미지 데이터를 그대로 보내는 것을 생각해볼 수 있다. 그러면 서버 입장에서는 받은 데이터를 대상으로 object recognition을 수행하고, classification의 결과만을 다시 모바일 어플리케이션으로 전송하는 것이다.
이러한 방식을 cloud-based inference라고 한다.
그러나, cloud-based 방식의 한계점으로는 외부로 데이터를 보냄으로써 발생하는 data privacy concern, 서버와의 통신으로 인해 발생하는 communication overhead이 있고, 네트워크 전송 환경에 따라 성능이 좌우될 수 있다는 점 등이 있다. 그래서, 이에 대한 대안으로 제시되는 방식이 on-device inference이다. 이는 task 자체를 모바일 기기의 CPU, GPU를 이용하여 수행하는 것으로, 네트워크 접근 없이 실행할 수 있다는 것이 가장 큰 이점이다.
Performance Analysis on 2 Design Choices
On-device DL inference의 성능 분석은 다소 복잡한데, 그 이유로는 아래의 3가지를 들 수 있다. 첫째, DNN의 종류는 네트워크 구조, parameter의 수, 모델의 크기 등의 측면에서 매우 다양하기 때문이다. 둘째, DL task는 input 데이터와 사용하는 모델 종류에 따라 복잡성을 갖기 때문이다. 셋째, 모바일 기기들은 서로 다른 resource capacity를 가지고 있으며, 메모리 garbage collection 등에 따라 runtime에 일어나는 일이 다를 수 있기 때문이다.
이렇듯 복잡성을 갖는 on-device DL inference에 대해, 본 논문은 모바일 어플리케이션 benchmark를 제안한다. Cloud-based, on-device의 두 가지 종류의 inference, 3가지 종류의 convolutional neural network(이하 CNN), 15장 이미지로 구성된 데이터셋을 가지고 실험을 수행한다.
실험의 결과는 cloud-based 방식이 end-to-end 응답 시간과 에너지 효율성 측면에서 모두 약 100배 정도 성능이 높게 나타났다. 추가적으로, cloud-based와 on-device 방식에 대해 performance bottleneck을 분석한다. 그 결과, DL 모델을 load하는 것과 compute하는 것이 가장 실행 시간의 많은 부분을 차지한다.
또한, On-device 방식에서 GPU를 이용하여 연산을 진행할 때 DL 모델이 메모리에 미리 load되어 있다면, inference 시간을 단축시켜 reasonable한 범위 이내에 들어올 수 있었다는 관찰 결과를 제시한다.
Background
DL Models
본 논문에서는 object recognition(=classification) task를 해결하는 DNN 모델을 대상으로 한다. 위의 Figure 1과 같이 input을 받아서 여러 hidden layer를 거친 후, 최종적으로 각 label에 대한 확률 분포를 출력하는 구조이다.
특히, DNN 중에서도 CNN 구조가 이러한 종류의 task에 있어 높은 성능을 보이는 것으로 알려져 있다. CNN은 convolution layer, pooling layer, fully-connected layer과 같은 여러 종류의 layer로 구성된다. 일부 layer에 대해서는 연산을 진행한 뒤 nonlinear activation function을 적용한다.
DL 네트워크 구조를 표현하고 학습시키는 여러 framework들이 있는데, 대표적으로 Caffe, Torch, Tensorflow가 있다. 이들은 CNN을 서로 다른 방식으로 표현하는데, 본 논문에서는 Caffe라는 framework를 대상으로 한다. Pre-trained Caffe model은 모델의 parameter 정보를 갖는 caffemodel binary 파일과 모델의 네트워크 연결과 label 정보를 갖는 prototxt 파일로 표현된다.
Mobile Apps: Cloud-based & On-device Inference
CNN 모델이 어디에 저장되어 있고, inference task가 어떤 방식으로 수행되는지에 따라 cloud-based, on-device의 2가지 방식으로 구분된다. 모바일 환경에서 딥 러닝 어플리케이션을 실행할 때는 cloud-based가 보다 일반적인 design choice가 되어 왔다. On-device의 경우, CNN 모델이 모바일 기기에 저장되어 있어야 하고, inference task도 모바일 CPU, GPU를 이용하여 실행된다. On-device inference에서 가장 큰 challenge 중 하나는 기존 CNN 모델들이 대부분 매우 많은 수의 layer와 학습된 수백만 개의 parameter들로 구성되어 있기 때문이다.
On-device inference 내에서도 2가지 접근법으로 나뉘는데, 첫 번째는 CNN 모델이 모바일 플랫폼에서 실행될 수 있는 기존 프레임워크를 이용하는 것이다. 하나의 예시는 Caffe Android Lib인데, 이를 활용하기 위해서는 우선 모바일 CPU와 ISA에서 돌아갈 수 있도록 컴파일되어야 한다. 그리고 실행되기 전에 컴파일된 라이브러리 파일들이 메모리에 올라가게 된다. 모바일 환경의 GPU가 desktop GPU와 매우 다르기 때문에, 현행 라이브러리를 이용해서는 모바일 GPU에서 실행시킬 수 없다.
다만, 이 논문은 2018년에 쓰여졌고, Tensorflow Lite가 언급되어 있지 않다. 최근 논문은 TF Lite를 SOTA(State-of-the-Art)로 소개하곤 한다. TF Lite는 모바일 GPU를 지원하므로, 현행 라이브러리 중에서도 모바일 GPU를 활용할 수 있는 것이 존재한다. (필자의 추론)
두 번째 방식은 모바일 GPU를 이용하기 위해 기존에 존재하는 모델을 다른 형태의 라이브러리 파일로 변환하는 것이다. 하나의 예시는 안드로이드 환경에서 CPU, GPU 병렬 처리를 위한 프레임워크인 RenderScript이다. CNN의 layer들을 RenderScript가 지원하는 kernel로 표현하면, runtime에 연산은 병렬 처리하여 실행할 수 있게 된다.
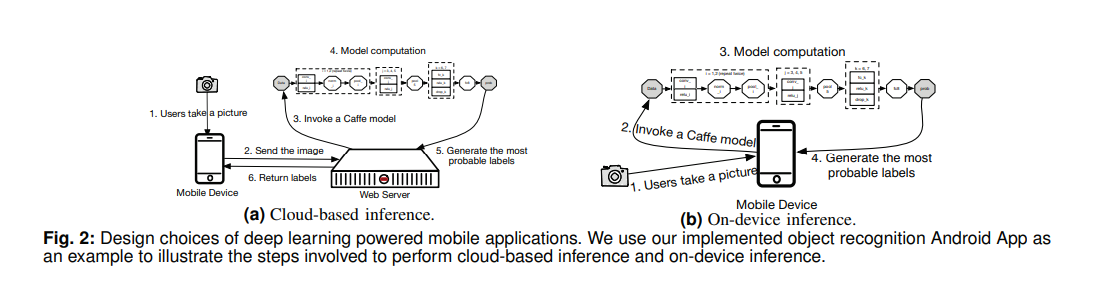
Lifecycle Management and Its Performance Implication
CNN 모델은 약 수백만 MB의 메모리 크기를 갖는데, 모바일 기기의 메모리는 한정적이다. 따라서 어플리케이션이 foreground에서 background로 전환되었을 때, 모바일 OS의 garbage collection 알고리즘에 의해 CNN 어플리케이션에서 할당받았던 heap이 kill될 수 있다. 이후에 user가 killed application을 다시 실행시키려고 한다면, 다시 재시작하는 데에 startup latency가 소요된다.
이것은 on-device inference에서 performance bottleneck으로서 작용할 가능성이 있다. (필자의 생각)
Mobile DL Inference Evaluation
Experimental Setup
3개의 CNN 모델은 각각 AlexNet, NIN, SqueezeNet인데, 이 3개의 모델을 선택한 이유는 이들이 ImageNet 데이터셋에 대하여 정확도는 비슷하나 모델 크기 측면에서 서로 다른 특성을 갖기 때문이다. 데이터셋의 경우 총 15장의 사진을 사용하는데, 디폴트 크기는 2160*3840이다. 이를 2, 4배로 downsampling한 것을 2, 3번째 데이터셋 그룹으로 하여 사용하였다. 데이터셋 정보는 Table 2과 같다.

실행 시간 측정을 위해 Logcat이라는 command line tool을 사용하였다. 이는 모바일 기기에서 돌아가는 각각의 실험에 대한 log file을 출력해주며, memory garbage collection과 같은 시스템 event 역시 출력하게 된다.
Power와 computing resource 이용 현황을 추적하기 위해서 Trepn을 사용하였는데, 이를 통해 battery consumption, CPU usage, GPU load에 대한 정보를 csv 포맷으로 얻을 수 있다.
End-to-end Comparison
결과는 end-to-end response time과 resource utilization의 2가지로 구분된다. 결과는 논문의 Table 3에 정리되어 있다.
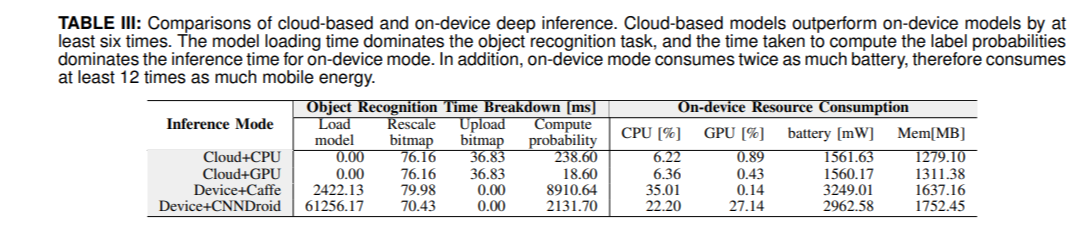
실행 시간의 경우, 4가지의 step으로 나누어 분석할 수 있다. CNN 모델이 메모리에 올라가는 단계, 원본 이미지를 CNN 구조에 맞게 donwsampling하는 단계, 이 이미지가 서버에 올라가는 단계, inference matrix를 계산하는 단계이다. 그러나, cloud-based에서는 첫 번째 단계로 인한 시간을 거의 무시할 수 있는데, 왜냐하면 이미 메모리에 존재하고 있기 때문이다. 또한, on-device에서는 이미지가 서버에 올라가는 단계를 무시할 수 있다.
실행 시간에 대한 결과를 보면, cloud-based가 on-device에 비해 약 수십 배 이상 우수한 성능을 보인다.
본 논문에서는 이에 대한 결론을 다음과 같이 제시한다. Cloud-based가 on-device에 비해 inference 응답 시간, 모바일 기기의 에너지 효율성 측면에서 모두 two orders of magnitude 만큼의 우수한 성능을 보인다. 이에 대한 이유는 cloud 환경의 powerful processing power과 shorter duration of inference이다.
On-device Performance Analysis
첫 번째 분석은 딥 러닝 모델과 프레임워크의 선택에 관한 것이다. 아래 논문 Figure 4의 (a)를 보면, Caffe Lib이 CNNDroid에 비해 loading 시간이 적게 걸리는데, 그 이유는 모바일 GPU를 활용하기 위해 모델을 변환하는 데에 드는 추가적인 overhead일 것이다.
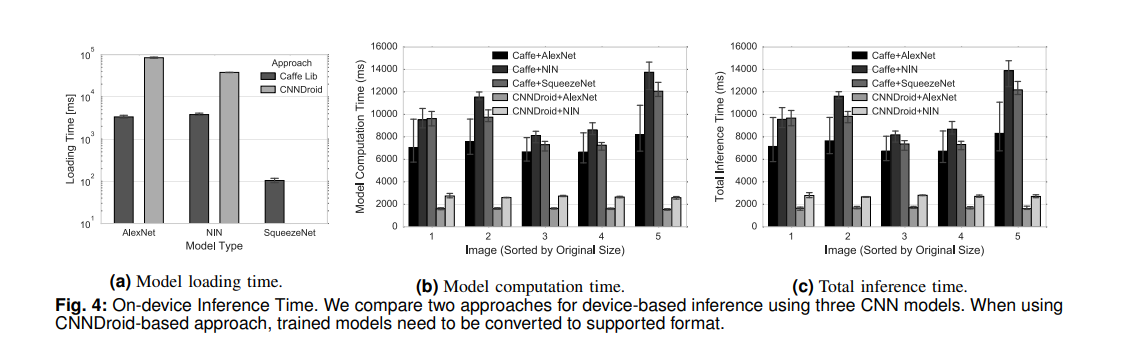
이러한 model loading은 어플리케이션을 처음 실행시킬 때, 또는 어플리케이션이 background로 전환되었다가 다시 foreground로 복구될 때 일어난다. 위 측정 결과에 의하면, 모바일 GPU를 활용하기 위해 처음 어플리케이션을 실행시킬 때 모델을 불러오는 데에 약 88초를 기다려야 한다.
이어서 (b)와 (c)는 computing latency 측정 결과이다. (c)에서 end-to-end는 모델 load는 제외한 것으로 보이며, (b)와 (c)의 그래프는 거의 유사한 모양으로 나타난다. CNNDroid에서 모바일 GPU를 활용하므로 연산 시간은 더 빠르게 나타나지만, 이것도 cloud-based CPU에 비하면 약 3배 정도 느린 수치이다.
두 번째는 모바일 환경의 메모리에 대한 것이다. 모바일 환경의 메모리 용량이 한정적이므로, Android Runtime에 의해 일어나는 garbage collection으로 인해 추가적인 latency가 발생한다.
정리해보면, on-device 방식에서 주요한 performance bottleneck은 처음 모델을 메모리에 load하는 것과 computing probability이다.
On-device Resource and Energy Analysis
모바일 GPU를 활용하는 CNNDroid 방식의 경우, Caffe Lib 방식보다 안정적이고 낮은 에너지 그래프를 보이는데, 이것은 RenderScript를 이용해 보다 에너지 효율적인 형태로 연산을 진행하기 때문이다.
다만 에너지 총량을 비교하면 CNNDroid 방식이 더 높게 나타나는데, 그 이유는 초기 메모리에 load하는 과정 때문이다. 만약 모델이 pre-load 되어 있다는 가정 하에, CNNDroid 방식은 end-to-end response time을 효과적으로 단축할 수 있을 것이다.



