논문 정보는 아래와 같다.
Joo Seong Jeong, Band: coordinated multi-DNN inference on heterogeneous mobile processors, ACM MobiSys, 2022
Introduction
Mobile DL inference with heterogeneous processors
최근 DL 기술의 발달과 함께 DNN은 실시간 사람 얼굴 인식 등과 같은 여러 복잡한 task에도 널리 쓰이고 있다. AR의 경우, 하나의 프레임에 대해서 사람의 pose estimation, object tracking 등 여러 DNN을 실행시킨다.
하지만, TensorFlow Lite, Mace 등과 같은 현재 모바일 DL 프레임워크들은 이러한 모바일 어플리케이션을 실행시키기에 부족한 면이 있는데, 주로 single DNN에 대한 최적화를 목표로 연구가 진행되었기 때문이다. 최근 모바일 기기는 CPU 외에도 TPU, DSP, GPU 등의 여러 종류의 프로세서로 이루어져 있는데, 그럼에도 위에서 언급한 DL 프레임워크들은 여러 개의 서로 다른 프로세서 중 가장 빠른 하나의 프로세서를 지정해 여기서 DL inference를 돌리는 식으로 동작한다. Multi-DNN의 경우, 하나의 모바일 프로세서에서 실행시키는 것이 가능하지만 latency 측면에서 성능이 기준에 미치지 못한다. 이에, 본 논문은 multi-DNN 워크로드를 여러 종류의 프로세서에서 효율적으로 실행시킬 수 있는 방법을 고안하게 되었다.
Motivation
Utilizing heterogeneous processors
TensorFlow Lite, Mace 등과 같은 현재 모바일 DL 프레임워크들은 single DNN을 최대한 빠르게 동작하는 것을 주로 목표로 하며, GPU나 NPU와 같이 가장 빠른 프로세서 하나를 지정하여 여기에서 연산을 실행시킨다. 하지만, 서버 환경에서 GPU가 FLOPS와 같은 측면에서 연산 성능이 매우 좋은 것과 달리, 모바일 환경에서는 GPU가 다른 프로세서에 비해 압도적인 성능을 갖지는 않는 경우가 일반적이다. 따라서, 모바일 환경에서는 하나의 프로세서를 지정하는 기존 방식보다 여러 개의 프로세서를 모두 활용한다면 효율성의 개선을 이끌어낼 수 있을 것이다.
이에 대한 또 다른 접근법 중 하나는 서버에 offloading하는 것인데, 간단히 설명하자면 모바일 기기에 비해 연산 성능이 훨씬 좋은 서버로 연산하고자 하는 데이터들을 보내서 서버에서 연산을 하고, 연산 결과를 다시 받는 방식이다. 최근 통신 기술의 발달로 주목받게 된 기술인데, 기본적으로 데이터 통신으로 인한 추가 latency가 필연적이기 때문에, 본 논문에서는 모바일 기기에서 DL inference를 개선하는 것에 초점을 맞춘다.
아래 그림은 본 논문이 제안한 솔루션의 성능에 대한 overview이다.
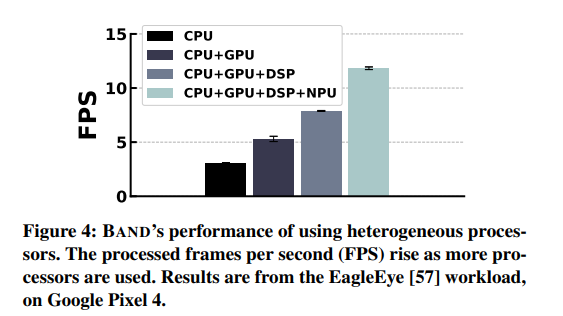
CPU만을 사용하였을 때에 비해 다른 프로세서들을 함께 사용함에 따라 연산 성능의 지표인 FPS(Frames per Second)가 더 높아졌다. 이 때 연산의 대상은 EagleEye라는 person identification 어플리케이션이다.
3 Challenges
다음으로는 본 논문에서 솔루션을 제안하는 과정에서 마주한 주요 challenge들을 살펴본다.
(1) Processor contention
모바일 프로세서의 경우, 코어 수와 메모리 BW의 한계로 인해 여러 개의 DNN을 동시에(concurrently) 실행시키면 latency가 늘어난다. 아래 표를 보면, 하나의 프로세서에 대해 동시 실행되는 모델의 수가 늘어남에 따라 latency도 함께 늘어난다.
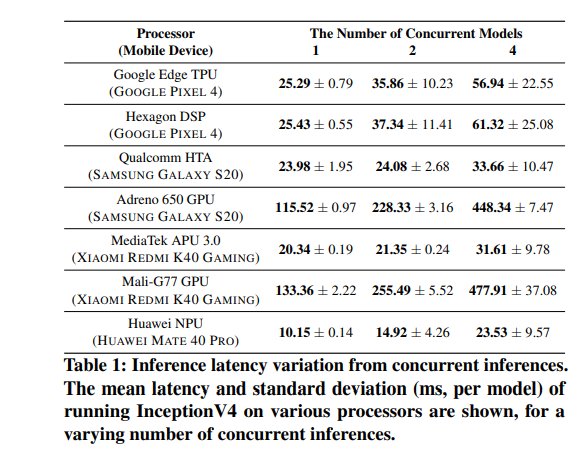
따라서, 워크로드를 scheduling할 때 하나의 프로세서에 여러 개의 DNN을 할당하는 것을 피해야 한다.
(2) Fallback operator
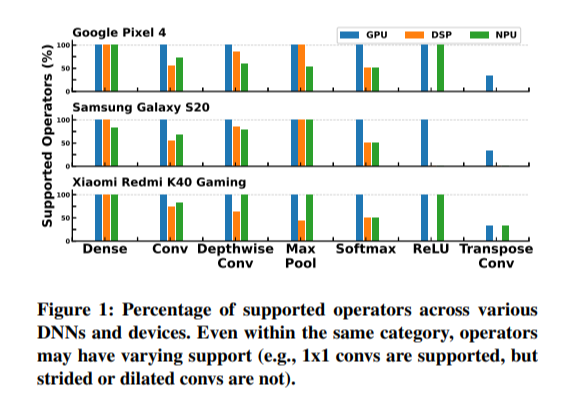
모바일 프로세서의 종류는 다양한데, 이로 인해 각 프로세서마다 지원하는 operator의 종류가 다르다. 특정 연산은 특정 프로세서에서 지원되지 않을 수 있다. 아래 그림은 여러 모바일 환경과 지원하는 operator의 종류를 나타낸다.
아래 그림은 여러 DNN 모델에 대한 구글의 Pixel 4 환경의 연산 지원 정도를 나타낸다.
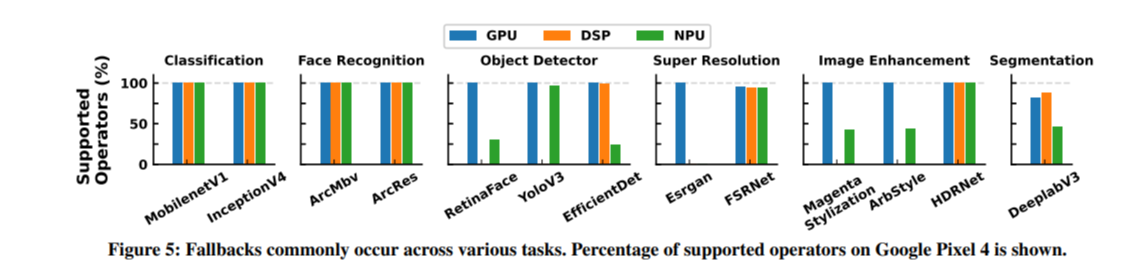
Classification은 워낙 유명하고 다른 어플리케이션에서도 사용되는 경우가 많아 최근 대부분의 프로세서에서 완전히 지원되지만, Super Resolution과 같은 모델의 경우 그렇지 않다. 예를 들어 이 모델은 stride가 4인 convolution 연산을 사용하는데, 이것은 DSP에서 실행될 수 없다.
구글의 TPU의 경우처럼 연산의 코어 부분은 아예 회로로 최적화시켜 구현되어 있는 경우도 있어서, 이렇듯 지원되지 않는 operator(또는 fallback operator라고도 부름) 문제에 대해서는 일반적으로 CPU로 돌아가 연산을 실행하는 식으로 해결한다. 그런데, 이는 2가지 측면에서 비효율적이다. Figure 6이 이를 설명하는데, EfficientDet에서 CPU fallback이 일어나고 이 연산이 CPU1에서 실행되는 동안 NPU는 idle 상태가 된다. 이 정보를 활용하여 MobileNet을 scheduling했다면, Figure 6의 아래 그림과 같이 이를 NPU에서 실행시킴으로써 보다 latency를 단축할 수 있었을 것이다. 또 하나의 비효율성은 항상 CPU에서 fallback operator를 실행시킨다는 것인데, 때로는 CPU보다 더 빠르게 이 연산을 할 수 있는 프로세서가 존재할 수도 있다.

따라서, 여러 가지 프로세서를 효율적으로 활용하려면 각 프로세서 별 fallback operator를 고려하여 scheduling을 해야 한다.
(3) Uncertainties in Performance
서버 환경에서 GPU가 일정한 performance를 제공하는 것과 달리, 모바일 환경에서는 SoC의 설계 방식에 따라 performance fluctuation이 더 크다. SoC는 DVFS(Dynamic Voltage Frequency Scaling)라고 하는 설계 원리에 따라 동작 주파수가 자동적으로 변하게 되는데, 이로 인해 정확한 연산 성능을 예측하는 것이 어렵게 된다.
아래 Figure 7을 보면, 하나의 모델을 연속적으로 실행시키는 경우 비교적 일정한 latency를 얻지만, 만약 중간에 idle 상태로 두다가 실행시키기를 반복한 경우 latency fluctuation이 생기는 것을 볼 수 있다. 이는 DSP, NPU와 같은 전용 가속기에 대해서는 더 심하게 나타난다.

Solution Overview
본 논문은 여러 가지 프로세서를 이용하여 multi-DNN 워크로드 연산을 하는 시스템을 솔루션으로 제안하며, overall structure은 아래와 같다.
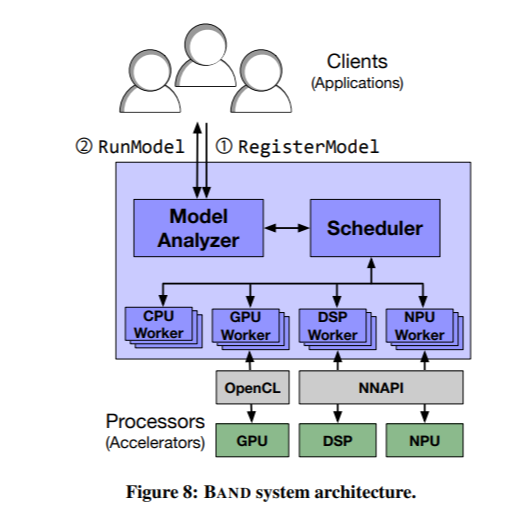
크게 3가지 부분으로 구성되는데, model analyzer, scheduler, per processor worker이다.
먼저, client는 실행시키고자 하는 DNN 모델을 시스템에 등록하게 되며, model analyzer는 모델을 분석함으로써 모델의 inference 연산에 대한 subgraph를 생성한다. 이 때, 각 프로세서 별로 지원 가능한 operator 종류를 고려하여 operator를 적절히 grouping 한다. Model analyzer가 생성하는 subgraph는 특정 프로세서에 mapping 되는 것은 아니며, 프로세서에 mapping 시키는 것은 scheduler의 역할이다.
다음으로, client는 inference 실행 요청을 하게 되며, 이는 내부의 queue에 job이라는 단위로 저장된다. Scheduler는 적절한 policy에 따라, model analyzer가 만들어둔 subgraph 중 적절한 것을 하나 선택하여 프로세서에 mapping 시킴으로써 dequeue한다.
각 프로세서마다 worker thread 하나를 할당하며, 각각의 thread는 하나의 subgraph를 실행한다. 실행이 끝났을 때 만약 inference가 모두 종료되었다면 결과를 client에게 보내고, 연산이 남아있다면 다시 job을 enqueue하여 위의 과정이 반복된다.
Subgraph Partitioning
Model analyzer는 모델에 대해 가능한 여러 subgraph set을 만드는 것이다. 예를 들어 어떤 모델이 Figure 9의 왼쪽 그림과 같은 graph로 표현될 수 있다고 하자.
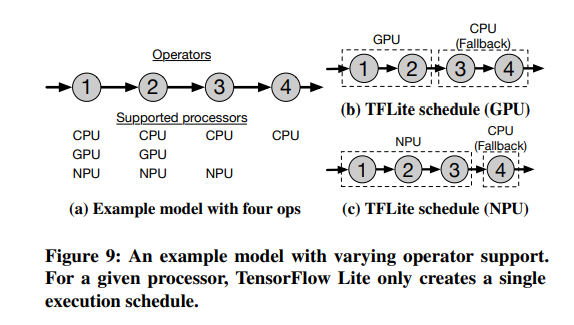
이 때 가능한 모든 경우의 수는 3*3*2*1=18개이다. 현행 프레임워크는 하나의 프로세서를 선택한 뒤 fallback operator는 모두 CPU에서 돌리는 방식이다. 그러나, 18개의 모든 경우의 수를 다 고려할 필요는 없는데, 프로세서 간 transition이 너무 많은 것도 좋지 않기 때문이다. 논문에서 제안하고자 하는 것은 operator-level과 model-level 중간 지점에서 partitioning하는 것이다.
Units and Subgraphs
먼저, 인접한 operator들을 unit 단위로 묶는데, 서로 지원되는 프로세서의 종류가 같은 operator끼리 최대한 묶는다.
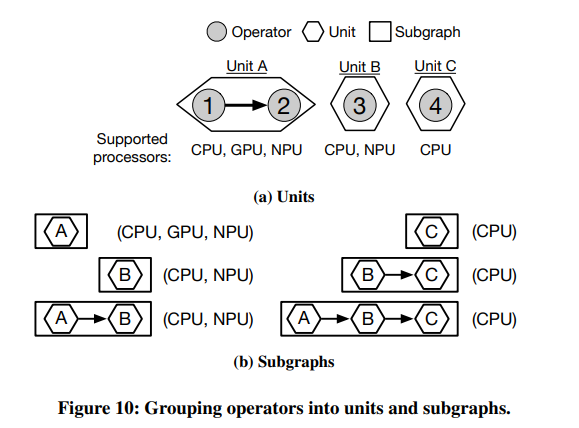
그리고 scheduling에 활용할 subgraph는 unit 단위로 만들어낸다. 우선 single unit으로 구성된 subgraph를 만들고, 만약 인접한 unit 간에 공유되는 프로세서가 있다면 서로 합쳐서 더 큰 subgraph를 만들어나간다.
Subgraph Scheduling
Scheduler의 역할은 model analyzer가 만들어놓은 여러 개의 subgraph 중에서 policy에 따라 하나를 선택하고, 어느 프로세서에서 실행시킬지도 선택한 뒤, worker thread로 요청을 보내는 것이다.
Scheduling
Scheduling policy는 LST (Least Slack Time)를 예로 드는데, slack time이란 SLO (Service-Level Objective)에서 예상 latency를 뺀 값을 말한다. 전반적인 구조는 아래 그림과 같다.
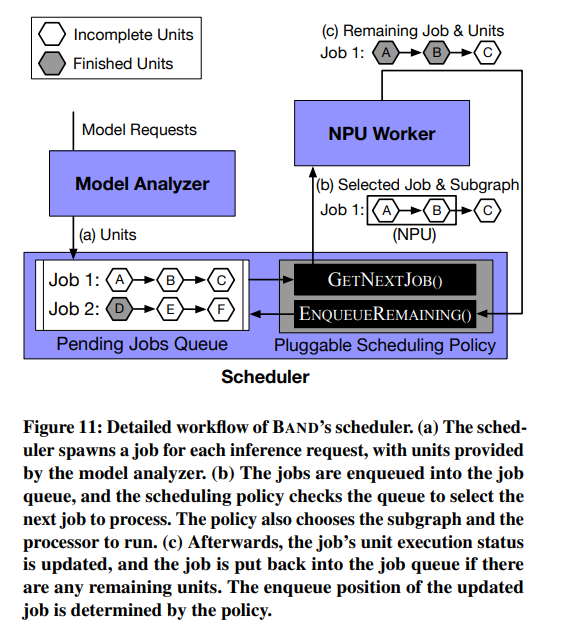
아래 그림은 scheduling policy에 따라 job을 선택하는 예시를 보여주는데, 그림의 상황은 모델 2개를 동시에 실행하고 있는 상황이다. 큐에는 2개의 job이 있다.
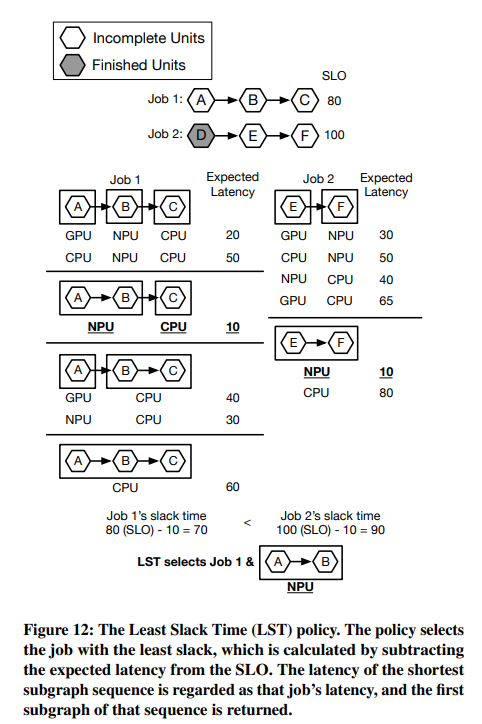
두 개의 job 중에서 더 작은 LST를 갖는 job의 subgraph를 실행시키고, 프로세서는 예상 latency가 가장 적은 것으로 성택한다.
남아있는 unit은 해당 subgraph의 실행이 모두 끝난 뒤 다시 job queue에 enqueue된다. 이후에 다른 job들과 함께 다시 scheduling policy에 따라 고려될 것이다.
Execution Time Profiles
LST를 비교하기 위해서 각 모델에 대한 실행 시간 profile 정보를 가지고 있어야 한다. 하지만 challenge 문단에서 설명했듯이 모바일 환경에서는 성능의 fluctuation이 존재하기 때문에, offline에서 미리 모델에 대한 분석을 하지는 않는다.
대신, 처음 모델이 등록되었을 때 baseline execution time을 측정하기 위해 미리 몇 번 실행시키고, 이후 워크로드를 계속 돌리면서 이 값을 업데이트하게 된다. 미리 돌릴 때는 largest subgraph를 하나의 프로세서에서 돌린 뒤, 각 subgraph의 FLOP, tensor size를 고려하여 값을 estimate한다.



