논문 정보는 아래와 같다.
M Wang, AsyMo: Scalable and Efficient Deep-Learning Inference on Asymmetric Mobile CPUs, ACM MobiCom, 2021
Abstract
최근 서버 컴퓨터 뿐만 아니라 on-device에서도 Deep Learning(이하 DL)을 돌리려는 시도들이 늘어나고 있다. 주로 이를 돌리는 하드웨어 플랫폼은 mobile CPU인데, 이러한 mobile CPU 기반 DL inference는 asymmetric multiprocessor를 이용할 때 발생하는 성능 향상의 한계와 에너지 비효율성이라는 2가지 문제점을 갖는다. 2가지 문제점에 대한 주요 원인으로는 1) task partitioning & distribution에서 발생하는 비효율성과 2) 모델의 에너지 효율성을 고려하지 않는다는 점을 제시한다.
이에 대한 해결책으로서 thread-level 솔루션을 제안하는데, DL inference가 deterministic하다는 데에 주목한다. DL 모델의 구조와 하드웨어 환경을 종합적으로 고려하여 최적의 execution plan을 offline으로 설계하는 것이다.
Introduction
Brief Background
최근 이미지 편집, 얼굴 인식, 목소리 인식 등의 딥 러닝 기반 기술들이 모바일 환경에서도 널리 사용되고 있다. 모바일 환경이 주목받는 이유는 서버 컴퓨터(on-cloud)에 비해 privacy 문제, 응답 시간 등의 이점이 있다. 그래서 on-device 전용 딥 러닝 프레임워크와 라이브러리들이 많이 개발되고 있다. 이들은 딥 러닝 워크로드를 주로 mobile CPU에서 돌리는데, 그 이유는 범용성, 여러 모델에 대한 robustness 측면에서의 이점이다. 본 논문에서도 하드웨어 플랫폼으로는 CPU를 선택하였다.
2 Main Problems
첫 번째 문제는 asymmetric multiprocessor(이하 AMP) 환경에서 성능 향상의 한계가 있다는 것이다.

위 그림은 코어 1개와 2개를 사용했을 때 inference latency를 기준으로 성능 차이를 비교한 그래프이다. 그림에 따르면, 코어 1개를 더 이용했음에도 latency 측면에서 성능 향상이 거의 일어나지 않았다.
두 번째 문제는 CPU의 동작 주파수와 관련된 에너지 효율성에 관한 문제이다. CPU 주파수를 최대로 하는 것은 성능 측면에서는 좋지만 에너지 효율성을 고려하지 않는 것이고, OS가 각 DL inference의 특성에 따라 최적의 주파수를 찾아 설정하지는 못한다.
More analysis on scalability issue
여러 개의 코어로 확장했을 때 성능 향상에 한계가 일어나는 이유에 대해 좀 더 살펴본다.
DL 모델은 기본적으로 tensor operation(대표적으로는 matrix multiplication, 이하 MM)으로 구성된다. 여러 개의 코어에서 병렬적으로 실행시키기 위해, thread pool은 MM을 여러 개의 sub-task MM로 partition하여 각 thread에 분배한다. 그 후에 OS는 scheduling policy에 의해 여러 개의 코어에서 thread가 실행된다.
(DL 뿐만 아니라 전반적인 thread-level parallel processing에 대한 배경 지식을 얻을 수 있는 부분이다)
그러나 기존의 방식처럼 OS scheduling에 모든 것을 맡긴다면, 여러 processor 간 asymmetry를 충분히 반영하지 못한다. 각 processor마다 연산 capability가 다르다는 점을 고려해야 하는데, 기존 방식은 capability에 비례하여 task distribution을 하지 못하고 있다.
또한 task partitioning, 특히 MM task를 어떻게 sub-task로 partition하는지도 모바일 환경에서는 중요한 문제이다. 최근의 서버 CPU의 경우 cache의 용량이 모바일 환경에 비해 여유로우므로 이것이 큰 문제가 되지 않지만, 모바일 DL framework에서는 고려해야 할 문제가 된다.
Overview of solution
Design principle 중 하나는 DL inference는 deterministic하다는 것이다. 딥 러닝 모델에 대한 정보는 사전에 주어져 있기 때문에, runtime이 아닌 offline에서 DL 모델 구조와 HW 환경(여기서는 AMP CPU 특성)을 함께 고려하여 최적의 execution plan을 설계하고자 한다. Execution plan은 task partitioning과 frequency setting을 말한다.
Partitioning의 경우, processor level->core level 순으로 이루어지며, core level에서 MM latency를 고려한 최적의 task size를 예측하게 된다. 사전에 cost model을 만들어놓아야 하는데, 이것은 MM latency에 영향을 줄 수 있는 memory access, task scheduling cost, parallelism의 정도 등의 요소를 복합적으로 고려하여 task size의 영향을 측정 및 판단하기 위함이다.
다음으로, least-energy frequency는 DL 모델의 data reuse rate에 의해 결정된다. 사전에 energy curve를 만들어놓는데, 이는 target CPU를 대상으로 여러 가지 computation과 memory-access benchmark가 다양한 frequency에서 어떤 energy performance를 보이는지를 측정해둠으로써 얻는다.
Background
Parallelism in DL inference
DL 모델은 아래 그림과 같이 dataflow graph로 표현될 수 있다. 각 노드는 operation을, 연결에 해당하는 edge는 연산에 사용되는 tensor들을 의미한다. Dataflow graph로 표현하는 것의 장점은 parallelism이 용이하다는 것인데, 여기서 말하는 parallelism은 서로 다른 연산 간에 존재하는 inter-op level과 하나의 연산 내에 존재하는 intra-op level의 두 가지로 나뉜다.
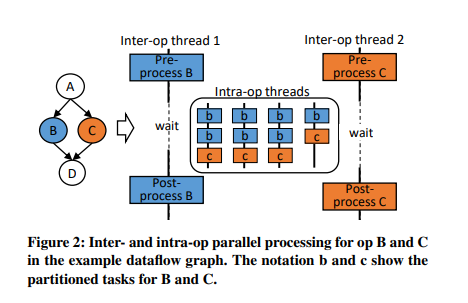
위의 예시에서 operation B와 C는 서로에 대해 dependency 없이 parallel하게 수행될 수 있고, 이를 inter-op thread pool이라고 한다. B, C가 적절히 preprocess된 후에는 sub-task b, c들로 나뉘어져서, 이들이 intra-op thread pool로 분배되어 실행된다. Inter-op thread들은 intra-op thread가 연산을 마칠 때까지 대기하게 된다. 본 논문에서는 intra-op thread optimization에 집중한다.
현재의 thread pool 구현 방식은 AMP CPU와 관계없이 task를 균일하게 각 thread의 task queue에 분배한다. 여기서 thread 수는 일반적으로 CPU 코어의 수로 맞춰진다.
MM Partitioning
DL inference에서 중요한 부분을 차지하는 MM에 초점을 맞추어 좀 더 구체적으로 살펴본다. 아래는 (M, K), (K, N)의 dimension을 갖는 두 행렬의 곱에 대한 partition 예시이다.

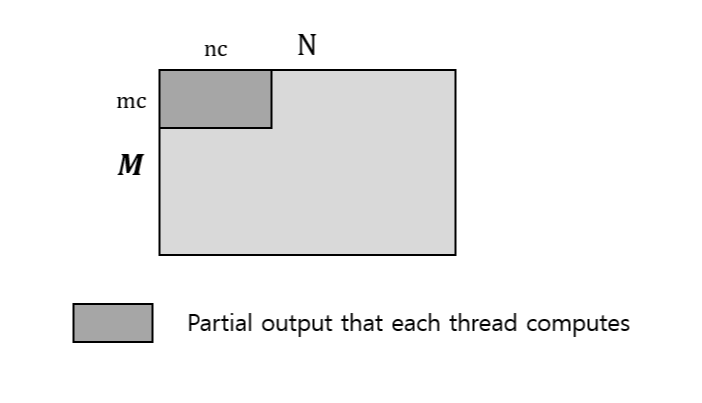
먼저 outer 2중 loop을 보면, (mc, K), (K, nc) 크기의 sub-matrix의 multiplication으로 쪼갠 뒤 각 thread에 할당한다. 이것을 output 관점에서 보면 서로 independent한 (mc, nc) 크기의 partial matrix를 계산하는 것이다.
하나의 thread 내에서 다시 (mr, nr)이라는 block size 단위로 연산을 하게 되는데, 논문에서 elementary block size라고 부르는 이 크기는 일반적으로 하드웨어 스펙에 해당하는 SIMD 레지스터를 최적으로 활용할 수 있도록 정해진다.
논문에서 주목하는 부분은 어떻게 mc, nc를 정하느냐인데, 기존 방식은 각 thread로의 균등한 분배와 task data가 캐시에 저장될 수 있도록 한다는 원리 하에 이루어진다. 그러나 AMP CPU에 대해서 제한된 성능 향상을 이루어내기 위해서는 이 부분에 주목해 개선할 여지가 있다.
Mobile AMP and OS DVFS
프로세서의 종류에 따라 동작하는 power domain이 다르기 때문에 각각에 대하여 동작 주파수를 제어할 수 있도록 되어 있다. OS DVFS(Dynamic Voltage and Frequency Setting)는 현재의 워크로드에 대하여 에너지 효율성을 고려한 적절한 주파수를 프로세서마다 할당하게 된다.
(여러 개의 프로세서가 존재하는 경우 동작 주파수가 어떻게 설정되는가에 대한 배경 지식을 얻을 수 있는 부분이다)
기존 방식의 경우 scheduler가 thread를 바꿀 때마다 다시 frequency를 설정하도록 되어 있으나, 본 논문에서는 DL inference는 'short-run'이라서 여전히 최적의 frequency와의 mismatch가 존재한다는 점에 주목한다.
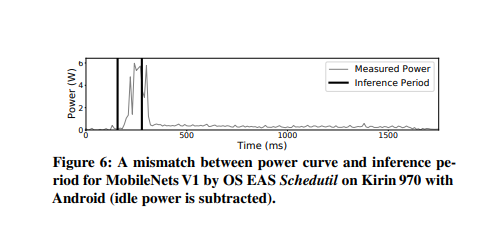
위 그림을 보면 DL inference가 시작된 후 일정 시간이 지난 뒤 frequency scaling이 일어나는 것을 알 수 있다. OS frequency scaling 대신 user 의해 직접 frequency를 설정할 수 있고, 논문에서는 이 방법을 이용해 위 그림의 mismatch를 해결한다.



