논문 정보는 아래와 같다.
Youngsok Kim, μLayer: Low Latency On-Device Inference Using Cooperative Single-Layer Acceleration and Processor-Friendly Quantization, EuroSys, 2019
Introduction
과거에는 모바일 기기에서 NN 어플리케이션을 실행시킬 때 cloud(=서버) 환경에서 실행시킨 뒤 결과를 받는 방식을 사용하였다. 그러나, 최근 모바일 SoC 기술의 발달과 함께 모바일 기기의 하드웨어 환경에서 실행시키는 on-device inference가 주목받고 있다.
Low-latency라는 목표를 달성하기 위해 한정적인 모바일 환경의 하드웨어 자원들을 최대한 효율적으로 활용하는 것이 중요하다. 기존 연구들은 CPU-friendly 최적화(quantization, vectorization)나 GPU와 같은 heterogeneous 프로세서의 사용 등을 통해 이를 개선하고자 하였다. 비교적 간단한 모델의 경우 on-device inference를 통해 거의 실시간으로 돌리는 것이 가능하나, 여전히 복잡한 모델의 경우 서버로 offloading 시켜 연산하는 방식으로 이루어진다.
본 논문에서는 이에 대한 솔루션을 제안하는데, 솔루션의 기반을 이루는 2가지 관찰은 다음과 같다. 첫째, 기존 방식은 single processor에서 NN을 실행하기 때문에, 여러 프로세서로 이루어진 하드웨어 환경을 모두 활용하지는 않다는 면에서 개선할 여지가 있다. 둘째, 모바일 환경에서는 CPU와 GPU의 개별 성능이 어느 한 쪽이 압도적이지 않고 비슷하다. 만약 성능이 매우 불균형하다면, 여러 프로세서를 통해 얻는 성능의 이득보다 multi-processor 관리를 하는 데에 들어가는 overhead가 더 클 수 있다. 모바일 환경에서는 그렇지 않기 때문에, multi-processor 연산이 성능 이득에 기여할 여지가 있다.
이러한 관찰로부터 제안하는 솔루션의 3가지 핵심 아이디어는 다음과 같다. 첫째, NN layer의 output channel 별로 워크로드를 독립적으로 쪼개는 방법이다. 둘째, 각 프로세서를 활용할 때 프로세서에 최적화된 자료형을 사용하는 것이다. 데이터를 표현하는 bit 수가 조금 줄어들었을 때도 NN의 성능이 거의 유지될 수 있기 때문이다. 셋째, NN의 branch 중에서 서로 data-parallel한 branch를 찾아서 쪼개는 방법이다.
Background
Neural Networks
본 논문에서는 여러 종류의 NN 중에서도 CNN을 대상으로 하는데, 왜냐하면 현재 많은 모바일 어플리케이션에 적용되고 있기 때문이다. 또한, 학습시키는 과정보다는 inference에 초점을 맞추는데, 학습 과정은 offline에 이루어질 수 있기 때문에 사용자가 경험하는 latency 측면에서는 inference가 더 중요하기 때문이다.
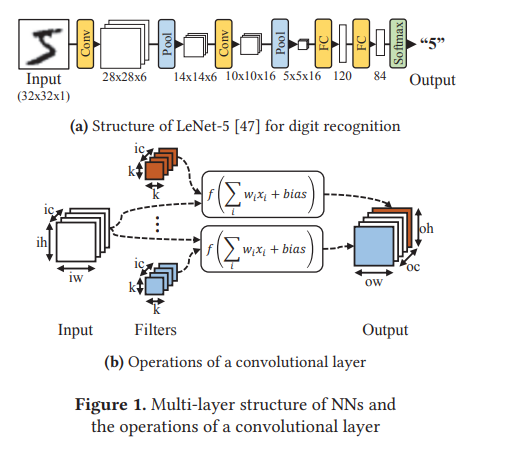
On-device Inference
On-device inference란 외부로 데이터를 보내지 않고 모바일 기기의 하드웨어 환경만을 활용하여 연산을 하는 방식을 말한다. 아래 그림의 (c)와 같다.
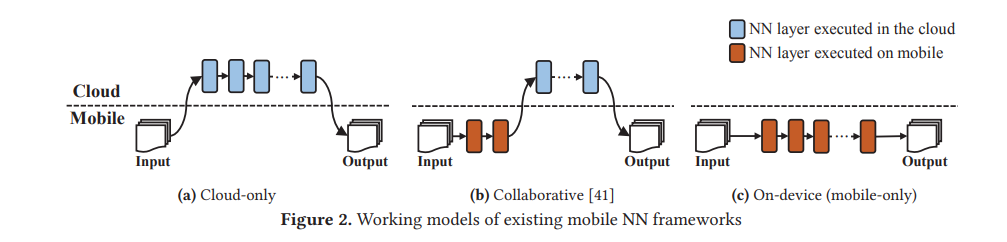
장점으로는 외부로 데이터를 보내지 않기 때문에 보안 측면에서 유리하고, 인터넷 환경에 영향을 받지 않고 연산이 가능하며, 통신으로 인한 추가적인 delay가 발생하지 않는다. 과거에는 (a), (b)와 같이 연산 전체 또는 일부를 서버로 보내서 연산을 했지만, 최근 SoC의 연산 환경의 발전으로 인해 on-device inference가 현실적으로 고려할 만한 좋은 해결책이 되어가고 있다.
On-device에서 NN을 실행시킬 때 프로세서를 이용하는 방식을 두 가지로 분류할 수 있다. 첫째는 네트워크마다 프로세서에 mapping 시키는 것인데, 아래 그림의 (a)에 해당한다.
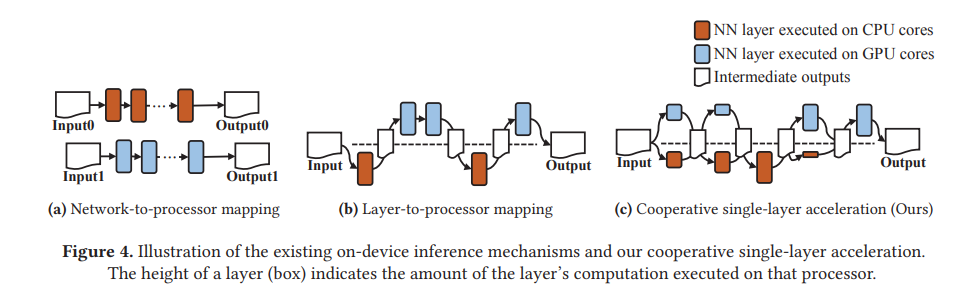
프로세서를 병렬적으로 활용함으로써 성능 개선을 이룰 수 있지만, 기본적으로 single processor의 성능에 의해 제한받는다는 한계가 있다.
둘째는 NN layer마다 프로세서의 mapping 시키는 방식인데, 위 그림의 (b)에 해당한다. 이 경우 각 layer마다 최적화된 프로세서로 mapping 시켜 연산을 한다는 면에서 첫째 방식에 비해 개선이 있을 수 있지만, 여전히 single processor의 성능에 의해 제한받는다는 한계는 존재한다.
본 논문은 위와 같은 한계를 극복하기 위해 (c)와 같이 하나의 layer 내에서도 CPU와 GPU를 모두 적절히 활용하는 방식을 사용한다.
Channel-wise Workload Distribution
하나의 layer 연산을 CPU와 GPU에 각각 어떻게 분배할지에 대한 기준이 필요한데, output channel 기준으로 disjoint set을 만들어 분배하는 방법을 제안한다.
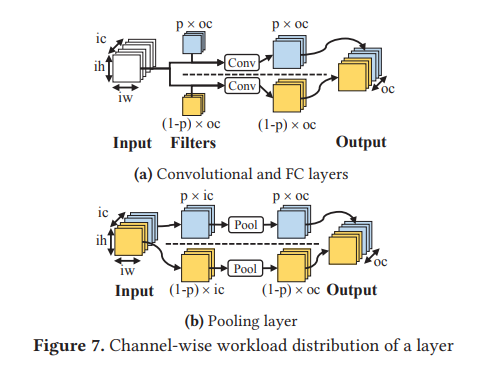
중요한 것은 서로 겹치는 영역이 생기지 않게 나누는 것인데, 위 그림과 같이 conv, fc layer의 경우 filter의 output channel dimension을 기준으로 두 부분으로 나눈다. FC의 경우 따로 논문에 표현되어 있지 않지만, weight matrix가 3차원이 아니라 2차원이기 때문에 column-wise 나눈다고 생각하면 될 것 같다. Pool layer의 경우 input의 channel dimension이 그대로 유지되기 때문에, 이 dimension을 기준으로 나눈다.
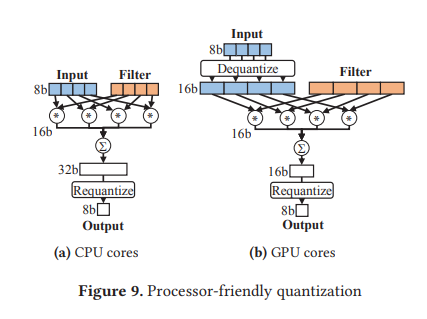
Processor-Friendly Quantization
이어서 각 프로세서의 성능 최적화를 할 수 있는 방안을 제시한다. NN을 실행시킬 때 32-bit의 디폴트 bit size를 쓰는 대신 더 적은 bit size를 사용함으로써 속도와 에너지 효율성의 개선을 이룰 수 있음이 알려져 있다. CPU, GPU에 대해 각각 8-bit, 16-bit 자료형을 사용함으로써 각 프로세서에서 최대의 효율성을 이끌어낼 수 있다. Bit size가 줄어들기 때문에 NN의 정확도 측면에서 성능 감소가 일부 일어나지만, 실험에 의하면 감소 비율이 크지 않다.
데이터를 프로세서 간 이동시키는 것이 모바일 환경에서 overhead로 작용할 수 있기 때문에, 여기서는 아래 그림과 같이 기본적으로 데이터들을 8-bit 형태로 다루고 GPU에서 연산을 할 때만 16-bit으로 dequantize하여 처리하도록 하였다.
Branch Distribution
일부 DNN은 branch 구조를 가지는데, 이 경우 channel-wise로 워크로드를 분배하는 것보다 branch distribution이 더 많은 parallelism을 이용할 수 있다. 우선 branch 구조란 아래와 같이 같은 input을 취하되, 서로 독립적인 연산 과정을 거쳐 partial output을 각각 출력하며, 이 output이 마지막에 합쳐지는 구조를 말한다.
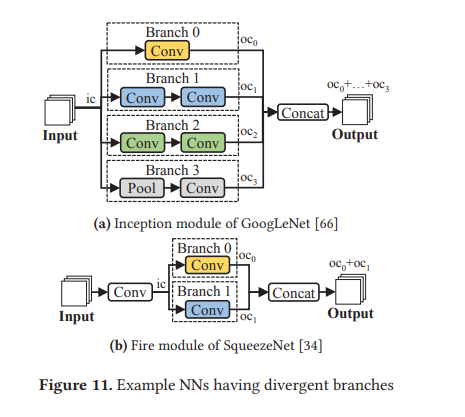
이 때 CPU, GPU로 분배하는 기준은 각 프로세서에서의 실행 latency 예측 값을 서로 비교해 가장 적은 값을 갖도록 하는 것이다. 각 프로세서에서의 연산 시간에 대한 예측은 선행 연구의 모델을 이용했다고 하는데, 이에 대해 본 논문에서 자세히 설명하지는 않았다.



