논문 정보는 다음과 같다.
F. Jia, CoDL: Efficient CPU-GPU Co-execution for Deep Learning Inference on Mobile Device, ACM MobiSys, 2022
1. Introduction
On-device DL inference
On-cloud와 비교했을 때 on-device DL inference는 사용자 데이터 안전성을 확보하고, 인터넷에 의존하지 않으며, cloud-operation을 줄인다는 측면에서 이점을 갖는다. 하지만 현재는 간단한 DL 모델에 대해서는 충분히 짧은 응답 시간을 갖지만, 예를 들어 object detection 모델인 YOLO의 경우 약 200ms가 걸리고 이는 응답 시간 면에서 개선이 필요하다.
2 Properties of Mobile SoC Architecture
만약 서로 다른 프로세서들(여기서는 CPU, GPU)을 동시에 효율적으로 사용할 수 있다면, 응답 시간의 개선을 이룰 수 있을 것이다. 이에 대한 근거로서, 우선 다음 2가지의 모바일 SoC(System on Chips) 환경의 특성을 제시한다.
첫째, CPU, GPU의 성능이 어느 한 쪽이 우세하지 않다. 이는 GPU가 CPU에 비해 병렬 계산에 대해 매우 우수한 성능을 보이는 서버 환경과 다른 점이다.
둘째, CPU와 GPU는 unified memory를 사용한다. 서버 환경의 경우 각 프로세서마다 구분된 메모리를 사용한다. Unified memory를 사용함으로써 data copying을 없앨 수 있다.
2 Challenges of Concurrent Execution
현행 DL framework들은 하나의 프로세서만을 사용하는데, 다음의 2가지 challenge 때문에 그러하다.
첫째, unified memory를 가지고 있으나 데이터를 공유하는 과정에서 추가적인 overhead가 발생하기 때문이다. 여기서 말하는 추가적인 overhead란 공유되는 데이터들의 coherency를 말하는데, processor synchronization, data mapping, 만약 서로 다른 data type을 사용한다면 data transformation 등이 포함된다. Data sharing으로 인한 overhead가 충분히 작아야 concurrent execution를 이용하여 성능 이득을 얻을 수 있다.
둘째, 여러 프로세서들에 어떻게 operator를 적절히 partition할 것인가의 문제이다. Runtime에 직접 실행시키면서 판단할 수는 없기 때문에, 정확하면서도 light-weight한 latency predictor가 요구된다. Latency predictor는 concurrency로 인한 overhead도 고려해야 한다. (예를 들어, 위 문단에서 언급한 data sharing overhead 등)
2 Key Findings and Solution Overview
본 논문에서는 이러한 challenge를 극복할 수 있는 2가지 key finding을 제시한다. 첫째는 프로세서마다 효율적인 자료형이 다르다는 것이다. 예를 들어, GPU의 경우 'image' type이 convolution 연산을 하는 데에 있어 'buffer' type보다 효율적이다. 둘째는 정확한 latency predictor를 만들기 위해서는 platform feature도 고려해야 한다. 여기서 말하는 platform이란 concurrent execution으로 인해 발생하는 overhead 등을 말하는 것으로 보인다.
이러한 key finding에 기반하여, 2가지의 핵심 솔루션을 제안한다. 첫째, 프로세서 종류마다 서로 다른 자료형을 사용한다. Partitioning 시에는 hybrid dimension partitioning, operator chain이라는 방법을 사용한다. Operator shape에 대해 최적의 partitioning dimension을 찾고, local data만을 활용하는 operator chain 단위를 설정한다. 둘째, concurrency-related overhead에 대한 latency 예측을 하기 위해 analytic한 방식을 제안한다. Linear component에 대해서는 linear regression 모델을 사용한다. Introduction에서는 analytic한 접근에 대해 더 서술되어 있지는 않다.
Motivation and Analysis
Existing works: 3 Aspects of Performance Bottleneck
논문에서는 CPU, GPU co-execution을 제안한 기존 연구에 대해 performance bottleneck을 분석한다. 아래 그래프는 기존 기술을 바탕으로 DL inference의 latency를 측정하여 비교한 것이다. Single processor의 경우 MACE를, co-execution은 uLayer라는 논문의 구현을 대상으로 하였다.
MACE: https://github.com/XiaoMi/mace
GitHub - XiaoMi/mace: MACE is a deep learning inference framework optimized for mobile heterogeneous computing platforms.
MACE is a deep learning inference framework optimized for mobile heterogeneous computing platforms. - GitHub - XiaoMi/mace: MACE is a deep learning inference framework optimized for mobile heteroge...
github.com
uLayer: Y. Kim, μLayer: Low Latency On-Device Inference Using Cooperative Single-Layer Acceleration and Processor-Friendly Quantization, EuroSys, 2019
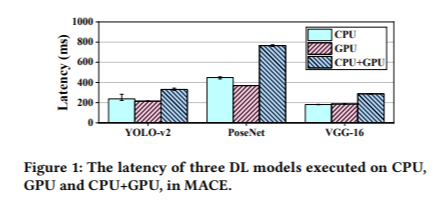
위 그래프를 보면 CPU, GPU를 모두 활용한 것에 비해 CPU-only 또는 GPU-only로 실행한 경우의 latency가 더 낮은 것을 알 수 있다. 이에 대한 분석을 3가지 제시한다.
첫째, 서로 다른 프로세서에 대해 같은 data type을 사용하는 것은 비효율적이다. 기존 연구에서는 CPU, GPU에서 모두 buffer라는 같은 data type을 사용하는데, GPU에서는 image라는 data type이 더 효율적이다. 따라서, 각 프로세서별로 최적의 성능을 낼 수 있는 data type을 사용해야 한다.
둘째, data shraing overhead가 크다. 서로 다른 data type을 사용하는 경우 data transformation이 필요하고, CPU address space로의 input data mapping, mapping/computation 결과를 다른 프로세서에게 알리는 synchronization, output data에 대한 CPU address space에서의 unmapping 등이 요구되는 추가적인 overhead이다.
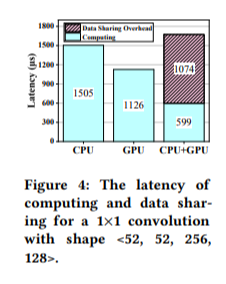
위 그림을 보면, 특히 small operator의 경우 co-execution을 통해 얻을 수 있는 latency 이득에 비해 data sharing으로 인한 overhead가 더 크기 때문에 비효율성이 발생하고 있다.
셋째, 워크로드를 적절한 partitioning 하기 위해서는 latency에 대한 정확한 예측이 요구된다. 그 이유는 latency가 적다고 판단되는 프로세서에게 더 많은 워크로드를 분배하게 될텐데, 예를 들어 아래 그림의 경우 GPU의 예측된 latency를 바탕으로 약 60% 정도의 워크로드를 할당하였지만 실제 latency는 더 작았고 이에 따른 optimal한 워크로드 비율은 더 높게 나타난다.
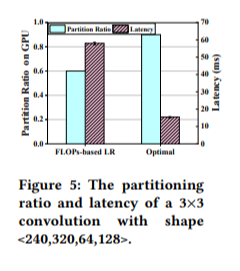
기존 방식의 경우 정확도가 낮거나 overhead가 크다는 문제점을 갖는다. 전자의 예시는 FLOP와 같은 연산의 수에 대해 linear regression을 하여 예측을 하는 방식인데, 정확도가 약 10% 정도로 낮다. (위 그림이 이 방식 기반이다) 그 이유는 연산의 수 외에도 알고리즘의 구현이나 data block size와 같은 플랫폼과 관련된 정보 역시 latency에 영향을 끼치기 때문이다. 후자의 예시는 이런 non-linearity에 대응하기 위해 보다 복잡한 black-box ML 모델을 통해 latency를 예측하는 것인데, 이는 모바일 기기에 응용하기에는 overhead가 크다.
Brief guide of solution 'CoDL'
본 논문에서는 CPU, GPU를 동시에 사용하여 DL inference를 최적화하는 프레임워크를 솔루션으로 제안한다. 솔루션은 크게 offline/online phase로 나뉜다.
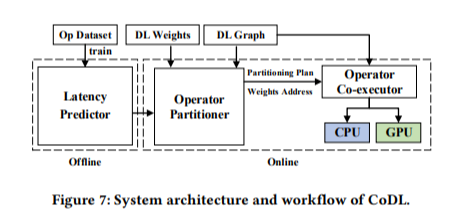
먼저, offline에서 latency predictor를 설계한다. Online에서는 미리 설계된 latency predictor에 기반하여 operator partitioning을 하게 된다. 이 때, data sharing으로 인해 발생하는 overhead를 고려하며, non-linearity에 대해서는 ML 모델이 아닌 별도의 analytical한 방법을 사용하고 linearity에 대해서만 linear regression 모델을 사용하여 학습하도록 하였다.
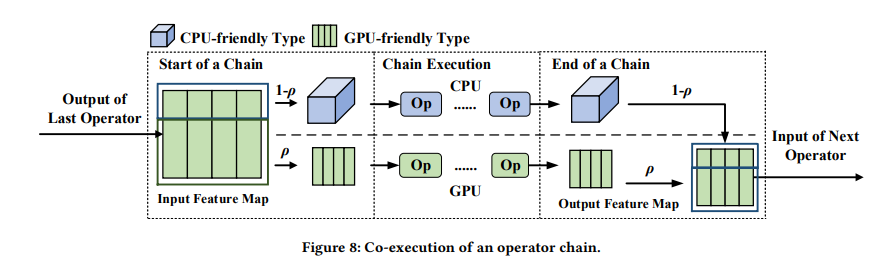
다음으로, online phase는 partitioning과 co-executor 두 개의 부분으로 구성된다. 우선, 미리 설계된 latency predictor에 기반하여, 최적의 partitioning plan을 찾는다. 최적의 partitioning dimension(height일지, output channel일지)과 비율을 찾고, operator chain이라는 방법을 이용해 shared data 없이 연산이 가능한 operator들의 묶음을 찾는다. 이러한 묶음(=chains)들의 집합을 찾는 것이 이 과정의 최종 output이다. 다음으로 co-executor는 프로세서 friendly data type을 활용해 concurrent execution을 한다. 이 때, GPU-friendly type이 디폴트이며, CPU에서 실행을 할 때는 data transformation을 거치게 된다. 그 후 CPU, GPU는 각각에 할당된 chain을 동시에 실행하며, 모든 연산을 마친 뒤에는 다시 GPU-friendly type으로 변환한다.