Object Detection
Computer vision 분야에서 neural network를 사용하는 application으로서 object detection을 살펴볼 것이다. Object detection이란 주어진 이미지에서 물체가 속한 영역을 box 표시하고, 물체가 어느 class에 속하는지를 분류하는 task를 말하는데, 하나의 이미지 내에 여러 개의 물체가 들어있을 수 있다는 점에서 이전 포스팅에서 다루었던 classification+localization 문제와는 다르다.
먼저, 지난 포스팅의 classification+localization 방식을 리뷰해보면, label score 벡터와 함께 bounding box의 좌표 값을 output으로 추가함으로써 regression 문제로 만들어 이를 해결하였다. 그러나, object detection에서는 물체의 개수가 정해져있지 않으므로 이를 finite number of output에 대한 regression 문제로 만들어 풀 수 없다.
이번 포스팅에서는 object detection을 푸는 여러 접근법을 공부한다.
R-CNN
R-CNN을 제시한 논문은 아래와 같다.
Girshick, Rich feature hierarchies for accurate object detection and semantic segmentation, CVPR, 2014
Region Proposal
R-CNN은 문제를 두 단계로 나누어 해결한다. 첫 번째 단계에서는 탐지하고자 하는 물체가 속할 가능성이 있는 영역들을 찾는데, 이를 region proposal이라고 한다. 참고로 용어에 대해 언급하자면, region proposal이란 영역을 찾는 과정을 의미할 수도 있고, 그 결과로 찾은 영역을 의미하기도 한다. 예를 들어, 아래 그림에서 연두색으로 표시된 여러 box들이 곧 region proposal 알고리즘에 의해 생성된 영역들인데, 이는 category-independent한 것으로 여기에는 관심있는 물체가 존재하지 않을 수 있다.
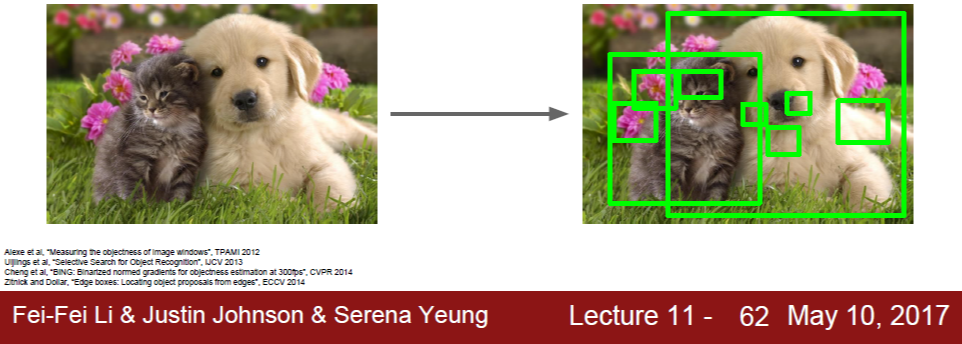
Region proposal을 RoI(Region of Interest)라고도 하며, 알고리즘에 따라 다르겠지만 R-CNN 논문이 사용한 알고리즘의 경우 약 2,000개의 RoI들을 얻는다. 사용한 알고리즘은 selective search라는 알고리즘인데, 이에 대한 설명은 아래 논문에 나와 있다.
J.Uijlings, Selective search for object recognition, IJCV, 2013
논문에 의하면, 이 알고리즘은 neural network와 같은 딥 러닝 방식이 아니며 traditional한 image processing 기반의 비전 알고리즘이다. (강의에서는 NN 기반의 학습 알고리즘과 대비되는 의미로서 'fixed algorithm'이라는 표현을 사용하였다.) Starting point를 다르게 잡고, color space, 픽셀 혹은 영역 간 similarity measure 등을 통해 hierarchical하게 segmentation 영역을 확장해나감으로써 물체가 있을 것 같은 영역을 찾아 나간다.
Pass through CNN
논문에서 제시한 R-CNN의 전반적인 구조 그림은 다음과 같다.
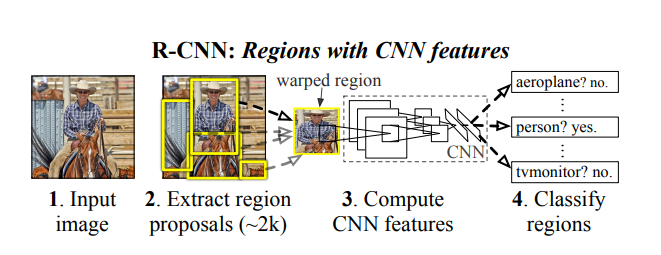
두 번째 단계에서는 첫 번째 단계를 통해 얻은 RoI들을 모두 미리 학습된 CNN에 통과시킨다. 여기서는 이미지 분류를 하는 CNN으로서 AlexNet을 사용하였다. 이 때, region proposal의 결과로 얻은 box들은 모두 크기가 다르기 때문에, CNN의 input으로 넣어주려면 size를 맞춰주어야 한다. 가장 simple한 방법으로서 RoI의 크기와 비율에 상관없이 모두 고정된 227*227 픽셀 크기로 warping 하도록 하였다.
CNN을 통해 feature extraction을 하는데, 추출된 feature란 강의에서 자주 언급되곤 하는 마지막 conv. layer를 통과한 후의 4,096 크기의 벡터이다. 이제 이를 fc layer에 통과시켜 score를 얻는데, 여기서는 SVM loss를 사용하였다. 기존에는 softmax 기반이었는데, 아무튼 최종적으로 score 벡터로 환산시킨다는 정도로 이해할 수 있다. Test time에 약 2,000개의 RoI에 대한 label score를 얻게 되는데, 마지막에는 이 box들을 모두 출력하는 것이 아니라 non-maximum suppression을 거친다. 일정 threshold 이상의 IoU(Intersect-over-Union) overlap을 갖는 두 영역 중에서는 높은 score의 RoI를 선택해나가는 방식이다. 참고로, 분류하는 class label 중에는 background도 있어서, 어느 종류에도 해당하지 않는 부류는 background 라벨이 붙여지게 된다.
논문 3.4에 보면 bounding box regression에 관한 내용이 조금 있는데, 기본적으로는 selective search로 찾은 RoI에 대한 error correction이다. 논문에서도 이에 대한 자세한 내용은 supplementary material로 빼두었으므로, 여기서도 자세히 다루지는 않겠다. 이전의 classification+localization에서 bounding box의 좌표 값을 regression을 통해 찾은 것과 비슷한 맥락이라는 정도로 이해하고 넘어가기로 한다.
Variation: Fast R-CNN
R-CNN 방식을 보다 효율적으로 개선한 것이 Fast R-CNN이다. Fast R-CNN은 기존 R-CNN에서 모든 region proposal을 CNN에 통과시킴으로써 발생하는 비효율성을 개선한다. 우선, 이미지 전체를 CNN에 통과시켜 feature extraction을 한다. Feature이란 마지막 conv. layer의 output을 말한다. 그리고, selective search와 같은 region proposal 알고리즘을 통해 얻은 RoI들을 feature map에 적용시킨다. 여기서부터 RoI마다 각각 score 벡터와 region error correction 값을 얻게 된다.
아래 그림을 통해 R-CNN과 fast R-CNN을 비교할 수 있다.

Variation: Faster R-CNN
Region proposal 알고리즘이 bottleneck이라는 점을 개선한 것이 faster R-CNN이다. 여기서는 region proposal 과정을 CNN에 포함시킨다.

Region proposal에 대한 training 및 loss를 어떻게 잡는지에 대해서는 강의에서 자세히 다루지 않았는데, 대략적인 설명으로는 우선 training 데이터셋에는 관심 물체의 영역 좌표를 ground truth로 가지고 있다. 그리고, region proposal network가 만들어낸 region 중 ground truth 영역과 어느 정도 비율 이상의 overlap을 가진다면 positive로 분류하는 식이다.
YOLO: Without region
위의 R-CNN 계열 방식은 모두 region proposal 후 각 region에 대해 object classification을 한다는 두 단계 접근법을 가진다. 그런데, 이렇게 두 단계를 거치지 않고 한 단계 만에 이 과정을 모두 하도록 하는 구조가 YOLO이고, 이는 You Only Look Once의 약자이다.
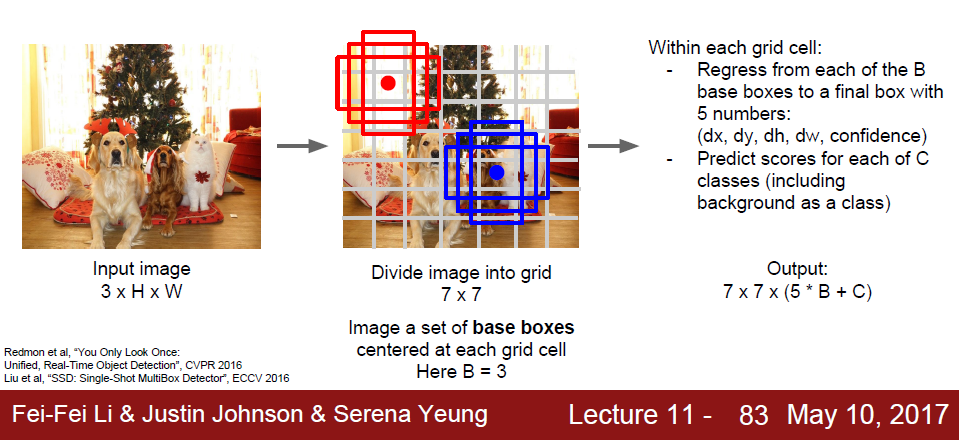
우선 이미지에 7*7 격자선을 그어서 여러 개의 작은 cell로 분할하고, 이들이 곧 base bounding box들이 된다. CNN을 통해서 이 49개의 base bounding box에 대한 class와 correction 수치들을 학습하게 된다. Region을 먼저 얻은 뒤 classification을 하도록 단계를 나누는 것이 아니라, 전체를 거대한 regression 문제로 만들어 object detection 문제를 풀었다고 볼 수 있다.



