지금까지 하나의 이미지를 정해진 class set 중 하나로 분류하는 image classification을 풀기 위해 CNN에 대한 여러 논의를 전개시켜왔다. Image classification 외에도 neural network를 활용하는 vision application은 다양한데, 이번 포스팅에서는 semantic segmentation, classification+localization의 두 가지 application에 대해 공부한다.
Semantic Segmentation
Semantic segmentaion이란, 아래와 같이 주어진 이미지의 각 픽셀이 어느 label에 속하는지를 모두 판단함으로써 이미지를 여러 class의 구역으로 분할하는 것이다.

Image classification과 마찬가지로 미리 정의된 label set이 있으며, 픽셀들을 모두 이 label set에 속하는 하나의 label로 분류하는 것이 목표이다. 그렇기 때문에, 오른쪽 사진의 소 두 마리를 서로 구분하지는 않으며, 모두 'cow'라는 class에 속한다고 판단하게 된다.
Sliding window: Small patches through CNN
Sliding window란, 작은 크기의 window를 x, y dimension으로 움직이며 이미지 전체를 훑는 방법이다. 작은 크기의 window란 예를 들어 5*5 크기를 생각할 수 있으며, 이를 patch라고 부르기도 한다. 이처럼 window size는 고정된 채로, window의 중심 좌표가 x, y dimension으로 움직이면서 이미지 전체를 window 단위로 훑게 된다.
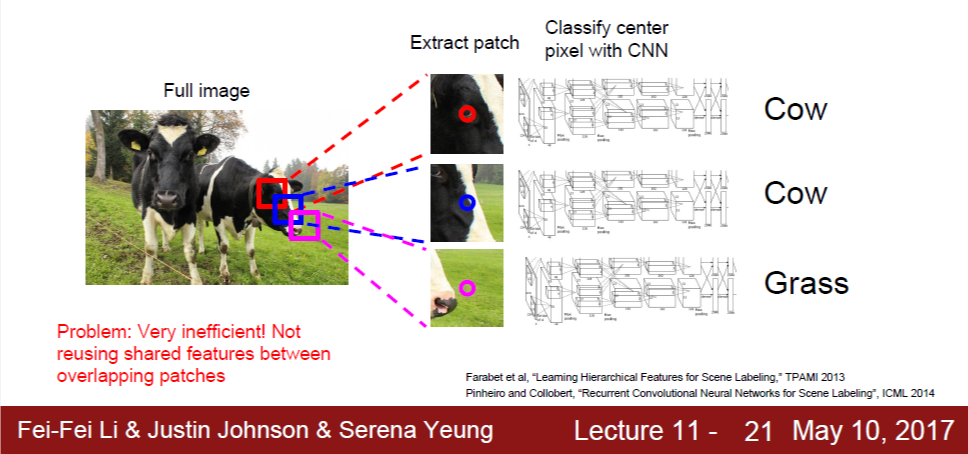
이제 이 small patch를 input 이미지로 하여 CNN에 통과시켜 class 판단 결과를 얻는다. 그러면 이것이 곧 small patch(=sliding window)의 중심 좌표의 class에 해당하게 된다. 이처럼, 모든 픽셀에 대하여 해당 픽셀을 중심으로 하는 small patch의 class 판단 결과를 얻는 것이다.
이 방식의 한계는 연산 관점에서 매우 비효율적이라는 것인데, 이웃한 patch 간에는 겹치는 정보들이 많이 있으나 이를 재활용하지 못하고 항상 다시 연산을 하기 때문이다.
Make it fully convolutional
이미지가 주어졌을 때, 모든 픽셀에 대한 class score(또는 probabililty)를 예측하도록 하는 CNN을 만들 수 있다. Image classification에서는 네트워크의 최종 output이 C*1 벡터이고, argmax를 취해 하나의 class로 예측을 했다면, 여기서는 네트워크의 최종 output이 C*H*W tensor가 되며(H*W는 이미지의 2D 크기), argmax를 취해 이미지의 모든 픽셀에 대한 class를 예측하도록 하는 것이다.

이 때 하나의 문제점은 이미지 원본을 대상으로 convolution 연산을 하는 것은 computationally expensive하다는 것인데, 이를 위해 downsampling을 거치고 convolution 연산을 진행해 feature extraction을 하고 다시 upsampling 하여 마지막 결과를 얻도록 한다.
Downsampling의 경우, pooling layer나 stride convolution을 이용한다. Upsampling은 지금까지 다룬 방식이 없는데, 이는 기본적으로 downsampling의 역연산으로 접근한다.
첫 번째는 unpooling인데, pooling과 반대로 1*1 -> 2*2로 upsampling 할 때는 2*2 중 하나에는 픽셀 값을, 나머지 세 곳은 0으로 채우는 식이다. 이 때, 2*2 중 어느 위치를 픽셀 값으로 채울지에 대한 선택지가 있는데, 그냥 왼쪽 위를 택할 수 있고, 아니면 이전에 downsampling 시 max pool이 일어났던 픽셀 위치를 기억함으로써 여기에 다시 값을 채워넣을 수 있다.
두 번째는 filter와 transpose convolution 연산을 하는 것이다.

Element 간 대응되는 것은 역방향의 convolution에서와 같다. 위 예시는 2*2 input, 3*3 filter, 3*3 output, stride 2인 상황이다. Filter가 input element의 크기 만큼 scaling된 채로 output 값으로 들어가게 된다. Output 좌표에서 오직 하나의 filter 값만 있으면 그 값이 그대로 output이 되며, 여러 filter가 겹치는 경우, 겹치는 모든 값을 합친 것이 output이 된다. 위의 경우, output의 한가운데 좌표는 4개의 filter와 모두 겹치므로, 4개의 값을 모두 더하여 output 값이 계산된다.
Training dataset
Training 과정에서 ground truth가 필요하기 때문에, training 데이터셋에 대해 모든 픽셀의 label 값을 미리 가지고 있어야 한다. 픽셀 당 일일이 입력할 수도 있고, 드래그나 색칠 등을 통해 영역을 표시하면 이를 픽셀 당 label로 변환해주는 프로그램을 이용할 수도 있는데, 어느 방법이든 이미지와 함께 모든 픽셀의 label 값을 데이터셋으로 가지고 있으므로, 이전의 image classification의 데이터셋과는 형태가 다르다.
Classification + Localization
다음 application은 이미지가 주어졌을 때 어떤 class에 속하는지를 분류하고, 동시에 물체가 어느 위치에 있는지를 box 표시하는 것이다. 여기서의 가정은 이미지 하나 당 관심 물체는 항상 1개 존재한다는 것이다.
CNN with multitask loss
여기서도 이미지를 input으로 하여 CNN에 통과시키는데, output이 두 가지 부분으로 구성된다. 하나는 기존 image classification처럼 각 class에 대한 score 벡터, 또 하나는 관심 물체가 존재하는 box에 대한 양 끝 좌표 4개의 숫자이다.
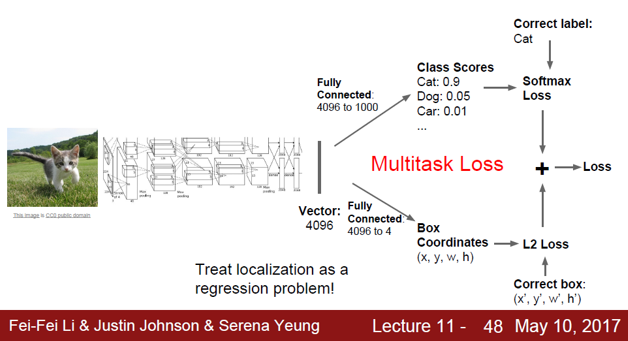
Loss function 역시 위와 같이 두 가지 부분으로 구성되며, 기존의 softmax loss에 더해 box 좌표에 대한 mean squared error term이 더해진다. 이 때도 training 데이터셋에 이미지가 속하는 class와 관심 물체의 영역 좌표를 groud truth로 가지고 있다는 가정이다.
이 때, 두 가지 loss를 단순히 더하게 되면 scale 문제로 인해 둘 중 한 쪽이 과도하게 고려되는 문제가 생긴다. 따라서, 각각의 term에 적절히 weight을 분배해서 더해야 하며, 이것도 hyperparameter이다.
Another example: Human pose estimation
Classification+localization 구조를 이용하는 또 다른 예시로서 사람 사진을 보고 사람의 자세를 추적하는 human pose estimation이 있다. 이 구조에서 output은 사람 몸의 14개의 관절에 해당하는 좌표 값인데, 즉 28개의 숫자를 최종 output으로 출력하게 된다. 미리 labeling이 되어 있는 ground truth 좌표와의 L2(=mean squared error) loss의 합을 loss function으로 한다.




