Regularization: Make a Model Better for Unseen Data
Optimization은 주어진 training 데이터셋에 대해 loss function을 최소화시키는 parameter들을 찾는 과정이다. 그러나, 실제 모델을 학습할 때 training 데이터셋에 대한 loss를 줄이는 것 뿐만 아니라, unseen data에 대한 loss와의 gap을 줄이는 것 역시 중요한 문제이다. 가지고 있는 training 데이터셋에 대해서 overfit 된 모델이라면, test time에 unseen data에 대해서는 좋은 performance를 낼 수 없고, 이것은 우리가 원하는 바가 아니다.
Regularization은 모델이 training 데이터셋에 대해 overfit 되는 것을 완화하기 위함인데, 그 방법으로 training 과정에서 loss function 수식에 additional한 term들을 추가하거나, 혹은 추가적인 연산을 하는 것들이 있다.
여기서는 강의에서 다룬 regularization 방법 몇 가지를 공부해보도록 한다.
L2 Regularization (Review on Lec 3)

먼저, loss function에 additional term을 추가하는 방식이 있다. 강의 자료의 예시는 fc layer에서 input x가 4*1 크기의 벡터인 경우를 가정한다. w1, w2의 2가지 parameter 모두 같은 output을 주기 때문에, loss function의 측면에서 보면 같은 performance를 낸다. 하지만, w1의 경우 x의 첫 번째 성분을 다른 것들에 비해 많이 이용하므로, 여러 성분을 균일하게 이용하는 w2에 비해 overfit될 가능성이 높다. 따라서, weight parameter의 크기 제곱들을 regularization term으로 두고, 이를 최소화하도록 하는 것이다. 이는 w1과 같이 특정한 성분을 지나치게 많이 이용하는 weight에 대해 penalty를 주는 term이라고 해석하기도 한다.
이는 머신 러닝에서 전반적으로 많이 이용되는 regularization 방식인데, neural network에서는
Dropout
How it works?
Dropout은 training 시 forward path로 값을 계산해나가면서, 임의로 뉴런 일부의 값을 0으로 만듦으로써 연결을 끊어버리는 것이다. 아래 그림은 dropout이 없는 경우와 있는 경우를 그림으로 비교하고 있다.
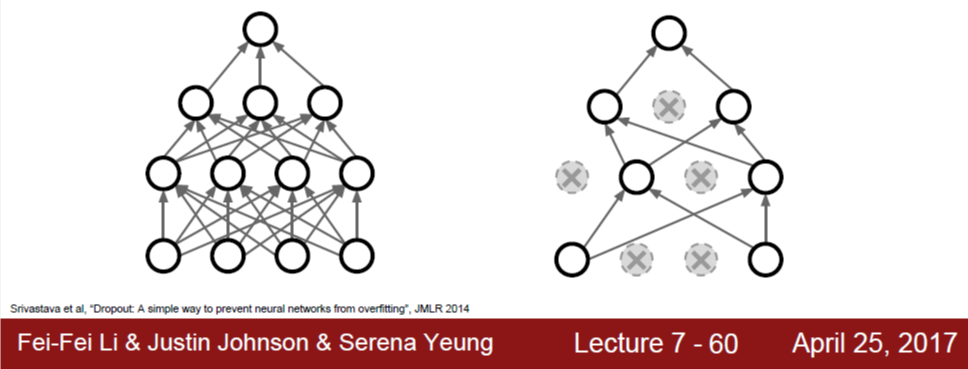
예를 들어 fc layer를 통과한다면, 우선 이 layer의 input x와 weight w 간에 elementwise multiplication을 한 뒤 activation function을 통과할 것이다. 그러면 이 지점에서 임의로 (random하게) 몇 개의 뉴런의 값을 0으로 만드는 것이다. 그러면 forward path 상에 존재하는 이 뉴런과의 모든 연결이 끊긴 효과가 생긴다.
물론, training 반복 횟수가 한 번이 아니라 매우 많은데, 그 때마다 random하게 뉴런을 선택해 0으로 만들어준다.
일반적으로 fc layer에 대해서 dropout을 하는데, convolution layer에 적용할 수도 있다. Conv. layer의 경우, activation map 단위로 dropout을 적용할 수도 있는데, 예를 들어 하나의 2D activation map 값을 모두 0으로 만들어버리는 식이다.
Interpretation: Why it works?
Training phase마다 연결이 끊어지는 뉴런이 다른데, 이를 다르게 표현하면 매번 학습하는 sub-network가 달라진다고 볼 수 있다. 이는 여러 개의 model을 학습시킨 뒤, test time에는 이들에 대한 결과를 average하여 output을 낸다는 model ensemble의 관점에서 해석할 수 있다. 여러 개의 model을 학습시킴으로써 overfit을 완화한다는 것이다.
Test time: Remove randomness
Dropout 방식은 L2 regularization과 달리 randomness를 갖게 되는데, 이것이 test time에는 문제가 될 수 있다. 예를 들어, 이미 학습이 완료된 모델인데 같은 이미지에 대해서 서로 다른 결과를 줄 수 있다는 것이다. 그래서, test time에는 dropout으로 인한 randomness를 다시 없애야 한다.
확률의 관점에서 생각해보면, 모든 random mask에 대해 expectation을 취함으로써 randomness를 없앨 수 있는데, mask의 조합이 매우 많기 때문에 이는 어렵다.
대신 보다 practical한 방법은 dropout 없이 우선 값을 계산한 뒤, 여기에 dropout 확률을 곱하는 것이다. Test time의 연산 양을 줄이기 위해, 이 곱셈을 training time으로 옮길 수도 있는데, training 시 구한 값을 dropout 확률로 나누어주는 것이다. 이를 inverted dropout이라고 한다.
Data Augmentation
또 하나의 regularization 방식으로는 data augmentation이 있는데, 용어의 뜻처럼 training data를 이용해 보다 확장된 데이터를 만들어서 training에 사용한다는 것이다. 해당 데이터의 ground truth(classification의 경우 label)가 변하지 않으면서 데이터를 변형시킬 수 있다면, 변형된 데이터를 또 다른 training 데이터로 이용한다는 것이다.
이러한 변형의 예로는 horizontal flip, crop & scaling, rotation 등이 있다. 예를 들어, 고양이 사진을 좌우로 뒤집더라도 여전히 고양이라는 것은 변하지 않으므로, 좌우로 뒤집은 새로운 이미지를 training 데이터로 이용할 수 있다는 것이다.



