Recurrent Neural Network: Processing Sequential Data
이전 lecture들에서 Convolutional Neural Network(이하 CNN)에 대해서 공부하였는데, CNN은 이미지 데이터를 대상으로 하며 목표는 이 이미지를 finite set of class 중 하나로 labeling(또는 classifying)하는 것이었다.
이번 lecture에서는 다른 neural network 구조인 Recurrent Neural Network(이하 RNN)에 대해 공부한다. CNN이 이미지 데이터를 대상으로 한 application에 쓰인다면, RNN은 sequential data를 대상으로 한다. 그 예로는 하나의 이미지로부터 이를 설명하는 sequence of word를 만들어내는 image captioning, sequence of word인 문장으로부터 어떤 sentiment에 속하는지를 분류하는 sentiment classification, 언어를 번역하는 machine translation 등이 있다. 이들은 모두 input이 sequential하게 주어지거나 output을 sequential하게 생성한다는 면에서, 하나의 input 이미지로부터 하나의 label을 출력하는 CNN과 다르다.
Basic Structure of RNN
RNN의 기본적인 구조를 아래 그림과 같이 표현할 수 있다.
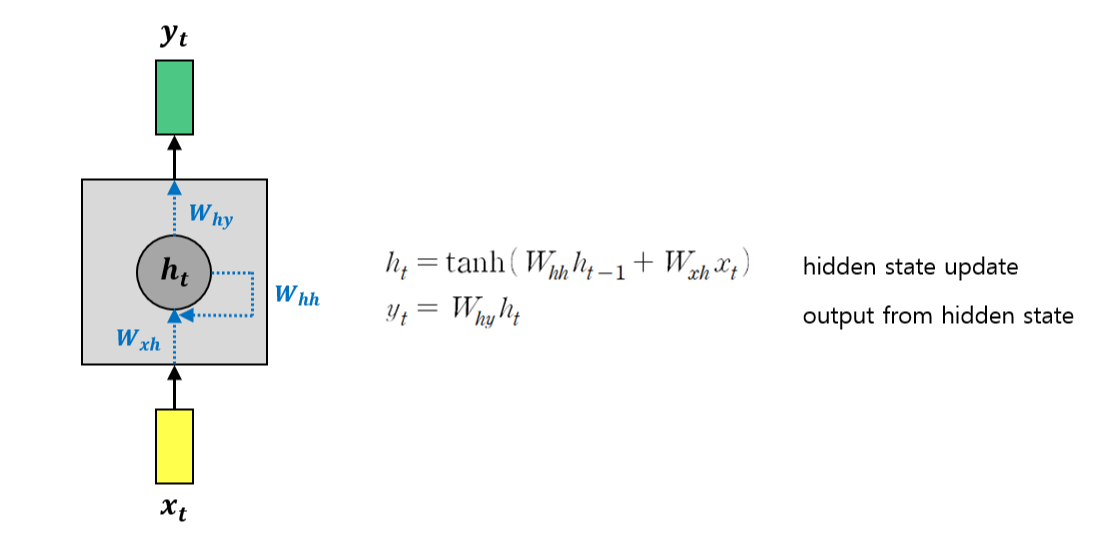
RNN의 큰 특징 중 하나는 hidden state가 있다는 것이다. Hidden state은 이전 hidden state과 현재의 input을 바탕으로 업데이트 되고, 이 때 곱해지는 weight matrix는 시간에 따라 변하지 않고 일정한 값이다. (물론 training 과정에서는 업데이트 되겠지만, 서로 다른 time step에서도 같은 weight 값을 사용한다는 의미이다)
매 time step마다 hidden state가 recurrent하게 업데이트 되며, 이 때의 output은 hidden state로부터 결정된다.
activation function은 tanh 함수를 사용하는 것이 일반적이다.
RNN structure wih computational graph
RNN 구조는 위와 같이 표현하기도 하지만, computational graph의 형태로 unroll하여 표현하는 것이 이해에 더 직관적일 수 있다.
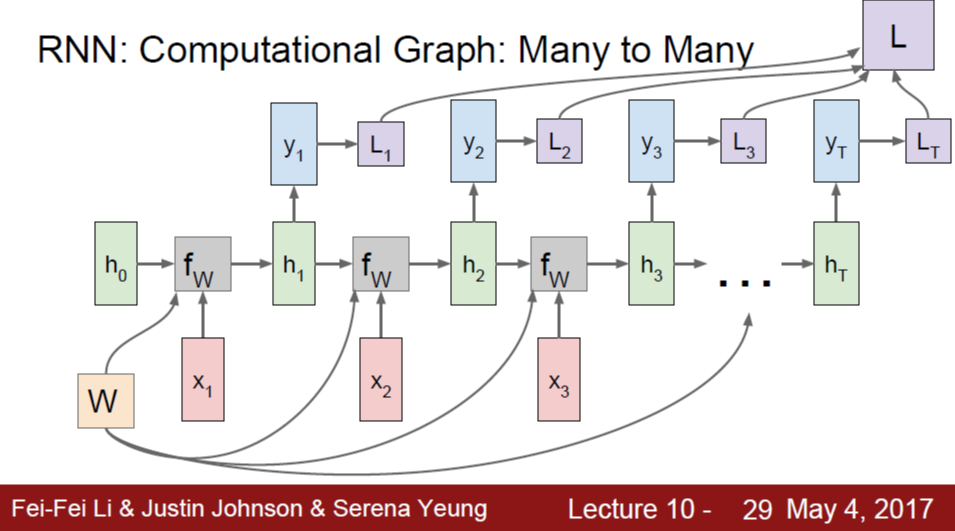
처음에는 initial hidden state h0로부터 시작한다. 이 그림을 보면 위의 그림과 같은 RNN 구조를 나타내지만, time step이 지나는 것이 오른쪽 방향으로의 flow에 대응되기 때문에, 매 time step마다 새로운 input이 들어오고 hidden state의 업데이트와 output 출력이 이루어지는 것을 보다 잘 이해할 수 있다.
Backpropagation of RNN: Summing all from each time step
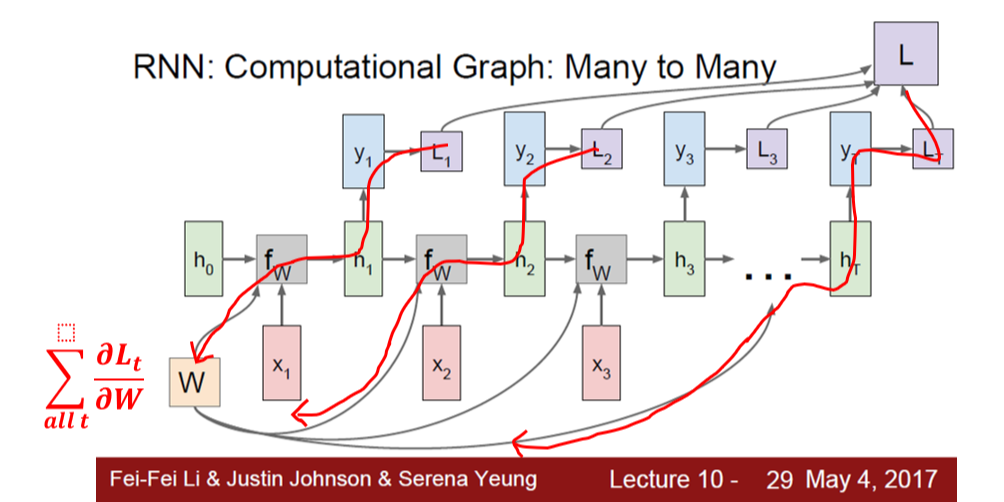
Backpropagation에서 gradient flow를 살펴보자. 여기서는 같은 weight matrix W가 매 time step마다 쓰이고 있으므로, multivariable chain rule에 따라, W의 gradient를 구하기 위해 모든 time step에서 loss의 gradient를 더한다.
Many to one, One to many
위 그림은 매 time step마다 input이 들어오고, output도 매번 출력되는 상황을 표현하였는데, 꼭 그렇지는 않다. 매 time step마다 hidden state가 업데이트되는 것은 공통적이지만, input이 매 time step마다 들어오지만 output은 마지막 time step에서 한 번만 출력하는 many to one 구조, input이 처음 한 번만 주어지고 매 time step마다 output을 출력하는 one to many 구조 역시 가능하다.
이 둘을 합친 것이 아래 그림의 encoder, decoder이다.

Encoder 부분에서는 매 time step마다 input이 들어오고, 맨 마지막에 이에 대한 summary라고 볼 수 있는 hidden state을 계산한다. 그러면 decoder 부분에서는 encoder의 마지막 time step의 hidden state을 input으로 하여 매 time step마다 output을 출력하는 구조이다.
Ex. Character-level Language Model
RNN 모델이 활용되는 예시로서, character-level language model가 있다. Language model을 character-level이 아니라 word-level을 표현하도록 설계할 수도 있을 것이다. 여기서 살펴볼 character-level의 경우, 하나의 character이 매 time step마다 순차적으로 입력되고, output으로는 매 time step마다 다음에 이어지기에 가장 적절할 character를 출력한다.
Character: Represent as a one-hot vector
이미지의 경우, RGB 채널의 픽셀 값으로 이루어진 3 dimension tensor를 입력으로 사용했다. 여기서는 a, b, c와 같은 character를 숫자의 형태로 표현해야 하는데, 여기서는 one-hot vector로 나타내었다. 총 n개의 표현 가능한 character가 존재할 때, character를 나타내는 input, output 벡터는 모두 크기가 n이다. 그리고, 각 character마다 고유한 index(또는 순서)가 부여되어, 해당 순서의 element만 1이고 나머지 값을 0으로 갖는 벡터로 표현된다.

예를 들어, 강의 자료의 예시에서는 hello라는 단어를 RNN 모델에 넣는 상황이다. 여기서는 전체 character set을 {h, e, l, o}의 4개의 알파벳으로 잡았으므로, input, output은 모두 크기가 4인 벡터이다. h는 1번째 element만 1, e는 2번째만, ... 이런 식으로 각 character들이 표현된다.
Character가 입력으로 들어올 때마다 RNN 모델의 hidden state인 h 벡터가 업데이트 된다. h로부터 크기가 4인 output y 벡터를 출력하고, 이것이 곧 다음 time step에 가장 등장할 확률이 높다고 모델이 판단한 character가 된다.
Test time: Generate a possible sequence with prefix
RNN 모델의 학습이 끝난 뒤, test time에는 prefix가 먼저 input으로 주어진다고 가정한다. 예를 들어, 위 상황의 경우 'h'라는 character이 첫 번째 time step의 input으로 주어졌다고 가정한다. 그러면 이 때의 output이 다시 다음 time step의 input으로 피드백되어 이어지는 time step의 output을 생성한다.
이 때, output으로부터 input으로 피드백되는 방법이 두 가지 있는데, 첫째는 output 벡터가 각 element에 대응되는 character들의 확률 분포를 나타내므로, 이 확률 분포로부터 하나를 sampling 하여 input으로 취하는 것이다. 둘째는 output 벡터에 대해 argmax를 취해 가장 큰 값을 갖는 element를 input으로 취하는 것이다. 첫 번째 방식의 장점 중 하나는 모델이 variety를 갖는다는 것인데, 같은 input에 대해서도 여러 output을 생성하는 것이 가능하기 때문에, 상황에 따라 이러한 특징이 유용하게 사용될 수도 있을 것이다.
Ex. Image captioning
Image captioning이란, 이미지가 주어졌을 때 이를 설명하는 문장을 출력하는 것이다. 크게 두 가지 부분으로 구성되는데, 첫 번째 부분에서는 이미지 input을 CNN에 통과시킨다. 이 때, image classification에서 마지막에 fc layer들을 중첩하여 class set 크기의 vector로 압축했던 것과 달리, 크기 4096 벡터를 최종 output으로 출력하도록 한다. 이것이 곧 이미지에 대한 summary 벡터가 된다.

두 번째 부분은 RNN 모델인데, 위의 character-level language model과 비슷하지만, 이번에는 word-level이다. Input과 output이 모두 하나의 단어 단위이다. Test time에 prefix로서 문장이 시작한다는 start symbol을 넣어준다. 그러면 time step의 output이 다음 time step의 input으로 피드백되어 단어들의 sequence를 생성한다.
Train 시, 이미지 input과 함께 이미지에 대한 설명이 담긴 문장이 ground truth로 활용되며, Microsoft Coco라는 널리 쓰이는 데이터셋이 있다고 한다.

Input, output이 길이가 variant한 sequential 데이터라는 점에서 이는 RNN 모델을 활용하기에 적절한 application이라고 볼 수 있다.



