Lecture 6, 7에 걸쳐서 neural network를 training시키는 과정에 있어 중요한 요소들을 다룬다. 이번 포스팅에서는 convolution/fc layer 이후에 수행하게 되는 activation/nonlinearity function의 종류와 특징, training data에 대한 preprocessing에 대해 정리해본다.
Activation Functions
General Scheme of Activation Functions with Neuron
Neuron을 통과한 후 activation function을 통과하는 구조를 일반적으로 아래 그림과 같이 표현할 수 있다.
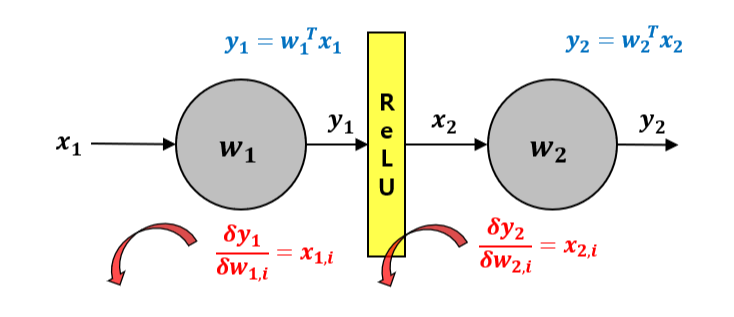
파란색, 빨간색 path는 각각 forward path, backpropagation를 나타낸다. ReLU는 activation function의 예시로 작성되었다. 하나의 neuron의 output이 y일 때, 이것이 activation function을 통과하면 다시 그 다음 neuron의 input x가 되는 상황이다. 또한, gradient를 계산하는 backpropagation의 관점에서 보면 activation function을 통과한 x_2는 곧 다음 neuron의 weight에 대한 local gradient이기도 하다.
강의에서 다룬 예시 activation function들의 수식과 그래프는 아래와 같다.

Sigmoid
Sigmoid 함수의 수식과 미분은 다음과 같다.

Neuron의 activation으로서의 해석이 용이하다는 면에서 유명한 함수인데, 이 함수를 activation function으로 사용하였을 때는 아래와 같은 한계점이 존재한다.
1) Saturation으로 인한 gradient kill: input의 절댓값이 어느 정도 커지면 부호에 따라 각각 0 또는 1에 매우 근접하게 saturation이 일어난다. Sigmoid 함수의 미분 식에 의해, 이 경우 sigmoid gate의 local gradient가 0에 매우 가까워지는 문제가 생긴다. 그러면 앞에서 전파되어오는 gradient flow에 비해 gate에서 local gradient에 의해 0으로 거의 죽는(killed) 효과가 크게 된다.
2) Zero-center 되지 않은 output: activation function의 output x_2는 곧 다음 neuron 입장에서는 input이며, gradient 계산 측면에서는 local gradient가 된다. 그런데 activation function이 항상 양수를 뿜는다는 것은 다음 뉴런의 local gradient가 항상 양수라는 것이다. 그러면 2번째 뉴런에 대해서는 모든 weight parameter의 gradient 부호가 앞에서 전파되어오는 gradient의 부호와 일치하게 되고, parameter update가 항상 같은 방향으로만 일어나게 된다. (모두 양수, 모두 음수의 2가지 경우의 수가 있다) 이는 weight update 과정이 매우 비효율적이도록 만든다. 강의 자료의 예시가 이를 잘 설명한다.

3) Computation cost 측면에서 exponential 연산은 expensive하다. 강의에서는 1, 2의 한계점에 비해서는 덜 강조된다.
tanh
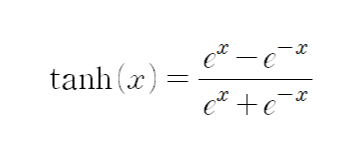
tanh는 sigmoid 함수와 유사한 형태로 생겼지만, zero-center되지 않은 output이라는 한계점을 해결할 수 있다. 여전히 절댓값이 큰 데이터에 대해 saturation이 일어나는 문제를 갖는다.
ReLU (Rectified Linear Unit)
ReLU 함수는 sigmoid 함수의 단점을 해결한다. max(0, x)와 같은 형태이므로 기본적으로 nonlinearity를 갖는다. positive 영역에서 saturation 문제를 갖지 않고, 연산도 매우 간단하다.
ReLU 함수는 음수인 데이터에 대해서 항상 0을 뿜는데, 이러한 특징을 dead ReLU라고 한다. 문제점 중 하나는 training 데이터에 따라서 어떤 neuron은 항상 0으로 죽어있는(dead) 상태여서 한 번도 update 되지 않고 초기값 그대로 남아있을 수 있다는 것이다.
Leaky ReLU
Leaky ReLU는 ReLU 함수의 특징을 유지하되, 음수 영역에서도 기울기가 더 작은 linear 형태를 가짐으로써 dead ReLU 문제를 해결한 activation function이다.
Maxout Neuron: Generalized Version of ReLU & Leaky ReLU
Leaky ReLU에서 음수 영역의 linearity 기울기를 parameterize할 수 있는데, 이렇듯 양수/음수 영역에 따라 다른 기울기를 갖는 보다 general한 형태의 함수를 생각할 수 있다. maxout 뉴런의 경우, weight parameter를 두 개 갖고, 이 중에서 더 큰 값을 output으로 뿜게 된다. general한 형태의 ReLU 함수인데, 학습시켜야 할 parameter는 2배가 된다는 tradeoff가 있다.
Data Preprocessing
With No Preprocessing...
만약 training 데이터셋에 대한 preprocessing 없이 그대로 input으로 넣고 training을 시작한 경우를 생각해보자. 이미지의 경우 픽셀 값이 양수이기 때문에 모든 input data가 positive 값을 갖는다. 위의 neuron structure 그림으로부터, 모든 input이 positive라는 것은 다음 뉴런에 대해 모든 weight parameter의 gradient 부호가 같다는 것이고, 이는 gradient descent에 의한 weight update 방향이 두 가지로 한정되게 한다. (모든 weight이 + 방향 또는 모두 - 방향의 두 가지) 즉, weight update가 비효율적이게 된다.
General Preprocessing
일반적으로 training 데이터셋 전체를 기준으로 평균을 구해 zero-centered로 만들고, 표준편차로 나누어서 크기를 normalize하는 것이 preprocessing이다.
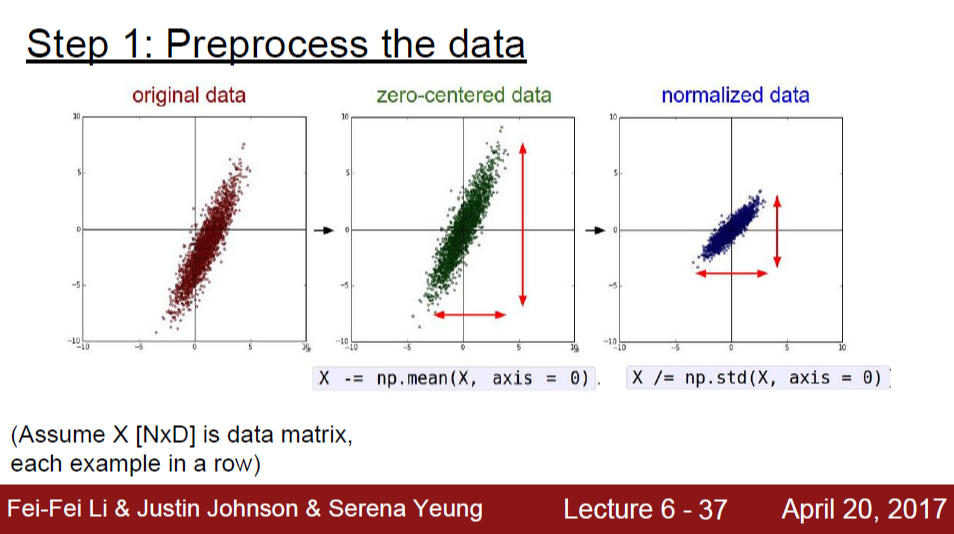
그런데, 이미지 데이터의 경우 spatial 특성을 고려했을 때 값의 분포가 고른 경우가 많아서 표준편차로 나누는 과정은 하지 않는 것이 일반적이다. 평균 값을 빼주어 zero-centered로 만드는 과정만을 거친다.
평균 값을 RGB 채널 상관없이 모든 픽셀 값을 기준으로 계산하여 뺄 수도 있고, 이 작업을 R, G, B 3개의 채널에 대해 독립적으로 할 수도 있다.



