1 Brief Summary
1.1 Motivation
Existing cache prefetchers keep track of metadata structures (for example, history table) in units of 4KB pages and stop prefetching if the predicted delta exceeds the 4KB page boundary. This is because going beyond the 4KB boundary doesn't assure physical contiguity. Cache prefetchers typically reside below the L2 hierarchy, where the address translation is already performed and therefore prefetching beyond the 4KB page boundary would entail a large overhead of additional address translation. However, as modern operating system provides 2MB page, a cache prefetcher might safely prefetch beyond the 4KB boundary if the page size is 2MB.
1.2 Key Idea
Solution consists of two parts.
(1) It suggests Pref-PSA (Page size aware prefetcher) which enables prefetching beyond the 4KB boundary for 2MB pages with the help of the new HW component that propagates page size information from the page table entry to the lower-level cache prefetcher.
(2) It adds a new prefetcher, Pref-PSA-2MB, which has the same mechanism as the existing prefetcher, except for tracking history in units of 2MB instead of 4KB. By monitoring the effectiveness of each prefetcher (Pref-PSA & Pref-PSA-2MB) using a counter-based scheme, it dynamically adjusts which prefetcher to issue prefetch requests.
1.3 Design Details
1.3.1 Pref-PSA (Page size aware prefetcher)

Page size information is available from the address translation metadata. It is stored in the MSHR entry of the L1 cache and then propagated to the L2 prefetcher. The prefetcher drives its prefetching mechanism in the same manner as the existing one, but it is page size aware in that it can allow prefetching beyond the 4KB boundary if the corresponding block resides in a 2MB page.
1.3.2 Pref-PSA-2MB and Pref-PSA-SD
A large page size, 2MB, can be integrated into the design of the prefetcher itself. For example, SPP uses the 4KB page number as an index for its signature table. Pref-PSA-2MB modifies the design by indexing with a 2MB page number regardless of the page size of the demand access request.
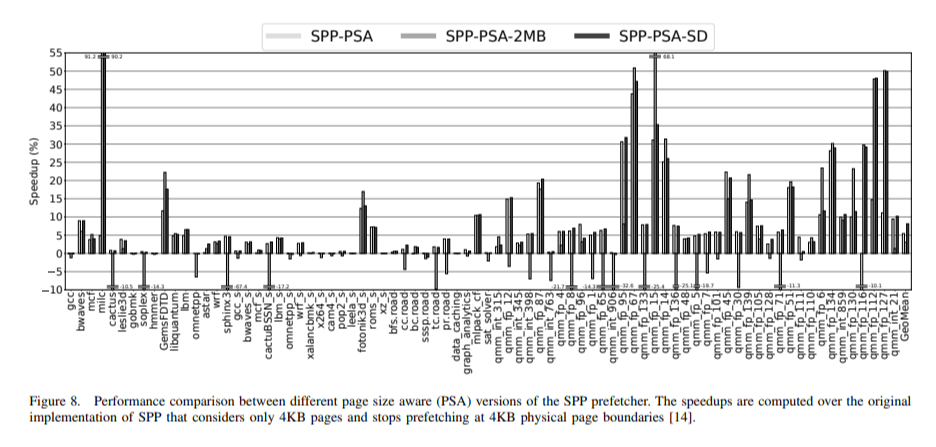
However as shown in figure 8 above, SPP-PSA-2MB exhibits a somewhat negative impact on performance for certain workloads because it provides a coarser representation of memory access pattern compared to the 4KB version. For workloads (for example, milc) that exhibit a wide stride, SPP-PSA-2MB can outperform the 4KB version, but it degrades performance for workloads (for example, tc.road) when it erroneously generalizes the access pattern between diffrent 4KB pages.
In PSA-SD (Set Dueling), both of the two different prefetchers mentioned above, the 4KB and 2MB versions, coexist. They are trained with every L2 access, and a single counter is incremented or decremented by checking which prefetcher correctly predicted the demand request. Prefetcher source information for prefetched cache lines is tracked using one additional bit per cache line.
2 Strength
(1) The limitation of not allowing prefetching beyond the 4KB boundary was common among all existing prefetchers.
(2) It effectively considered operating system component, page size, in designing cache prefetcher, which is a u-architectural concept. This serves as one of the successful examples of u-architectural optimization interacting with a system component (page size in this case), and this design perspective can be further applied to related topics.
3 Weakness
(1) It lacks scalability in terms of page size due to the additional storage requirements of 5~6KB for the prefetcher per page size. As modern system supports three different page sizes (4KB, 2MB, and 1GB), more scalable design is required. Using 3 different prefetchers concurrently might degrade performance as each prefetcher assumes a different memory access stride range.
(2) Workloads that heavily use 2MB pages do not necessarily benefit from Pref-PSA-2MB. (For example, bwaves and pc.road) In some cases, they show less speedup compared to Pref-PSA-4KB or the base SPP. The signature of SPP isn’t enough for effectively capturing memory access stride patterns for larger page sizes.
* Background
Here is a brief summary of one of the main references in the paper:
J. Kim. "Path confidence based lookahead prefetching." 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2016.
Architecture Overview
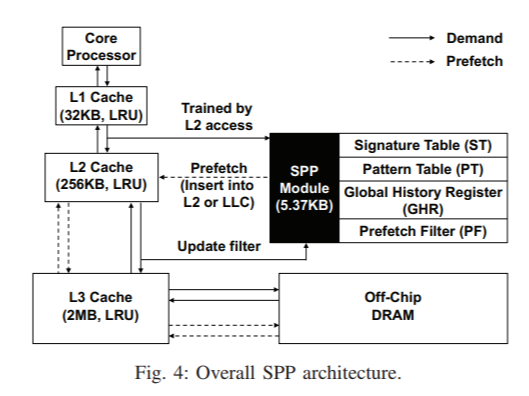
SPP (Signature path prefetcher) is a data prefetcher that resides in the L2 hierarchy and issues data load requests below L2, prefetching data before it is demaned by the core. It is trained with every L2 access, and issues prefetch requests for every L2 access except when there are few available L2 read queue resources because L1 miss is more performance-critical.
Update

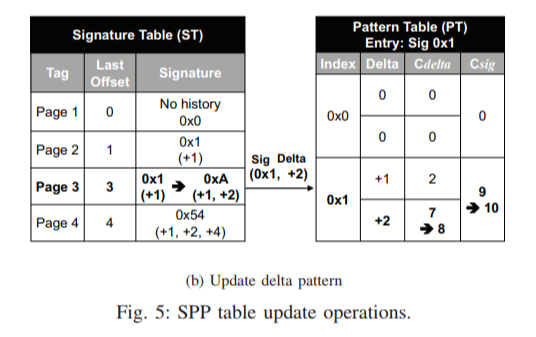
For a demand request, SPP accesses an entry in ST (Signature table) using its physical page number. ST records the signature, which is a compressed form of the memory access pattern within a page, along with its last offset in the page. Current delta is calculated using the offset of the demand request and the last offset. PT (Pattern table) tracks potential deltas per signature, and confidence score for the current delta is increased as it is an actually-observed memory access pattern.
Finally, the signature of the demand request page is updated with the current delta.
Prediction / Lookahead Process

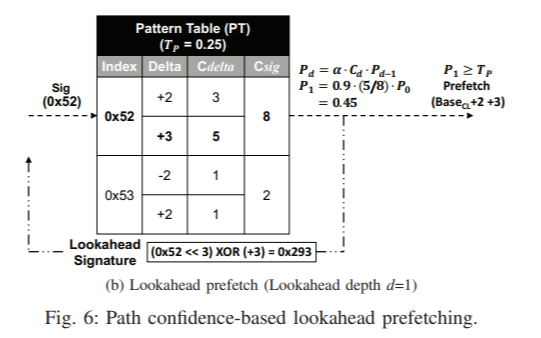
Prefetching based on the lookahead mechanism starts just after updating the signature. SPP accesses the PT with the updated signature and finds the candidate delta with the highest confidence score. It issues a prefetch request if the confidence score exceeds a threshold. The speculative signature is updated with the predicted delta, and the process above is repeated until the path confidence score, which is the product of the confidence scores of all the preceding predicted deltas, gets lower than threshold.
Minor Optimization: GHR (Global history register)


To learn the memory access pattern across physical page boundaries, boundary-crossing prediction is tracked in the GHR. For an access to a page that are not tracked in ST, the offset is compared to the sum of the last offset and delta in the GHR entry. If there is a match, SPP starts prefetching using the signature of the corresponding GHR entry. This can partially address the fundamental limitation of data prefetching under virtual memory system, where prefetching beyond the physical page is not allowed.



