1 Introduction
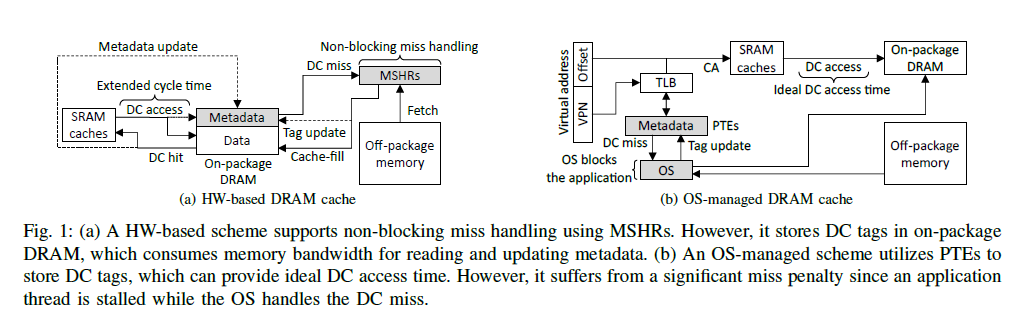
On-package DRAM을 캐시로 사용하는데, 이것을 구현하는 방식에는 HW-based, OS-managed의 두 가지 방식이 있다. HW-based는 non-blocking cache로 동작할 수 있기 때문에 여러 개의 miss handling을 동시에 처리할 수 있다는 장점이 있으나, metadata를 추가적으로 접근해야 한다는 한계점이 있다. OS-managed는 address translation mechanism을 활용해 tag를 저장하여 metadata overhead가 없어지지만, blocking으로 인해 miss 시의 penalty가 높다.
이에, 여기서는 non-blocking으로 동작하는 OS-managed DRAM cache design을 제안한다. 이는 OS handler 코드의 수정과 back-end HW 구조로 이루어져 있다. 이를 통해 application stall cycle을 효과적으로 줄이고, IPC performance를 향상시키는 결과를 얻었다.
2 Background and Motivation
메모리 시스템의 bandwidth, capacity 문제를 극복하는 한 대안으로서, 높은 BW를 제공하는 on-package DRAM과 높은 capacity를 제공하는 off-package DRAM을 모두 사용하는 heterogeneous memory system이 연구되어 왔다. Heterogeneous memory system에서는 on-package DRAM을 캐시(DRAM Cache, 이하 DC) 의 일환으로 사용하는데, 이는 크게 HW-based, OS-managed의 2가지 방식으로 관리된다.
2.1 HW-based DRAM Caches
Advantage
HW-based의 경우, Figure 1의 (a)와 같이 MSHR을 바탕으로 non-blocking cache를 구현할 수 있다. Cache miss가 나도 miss handling을 MSHR으로 offloading하기 때문에, 메모리 요청을 멈추지 않고 DRAM cache가 servicing을 계속할 수 있다. (= Memory-level parallelism을 활용할 수 있다)
Disadvantage
그러나 hit/miss 판단을 위한 tag, 그 외에 status를 표시하는 valid, dirty bit과 같은 metadata가 on-package DRAM에 저장되기 때문에, metadata 접근에 추가적인 BW 소모가 일어난다는 것이 한계점이다. DC를 접근할 때마다 DC controller는 tag를 읽어와야 하고, hit 시에 LRU bit을, write 시 dirty bit을 업데이트해야 하는데, 이 때마다 메모리 BW를 추가적으로 사용하게 된다. 이는 결국 DC access time을 증가시키기에 performance degradation의 주요 요소가 된다.
2.2 OS-managed DRAM Caches
Mechanism & Advantage
OS-managed 방식에서는 DRAM cache를 OS가 관리할 수 있도록 하고, 데이터를 page 단위로 저장한다. Caching mechanism은 tag (=cache frame number/CFN)를 PTE에 저장하여 이를 TLB 접근할 때 얻을 수 있도록 하는 것이다. TLB hit 시에는 cache address (CA)를 바로 얻을 수 있으므로, HW-based에 비해 tag 비교를 통한 hit/miss 판단에서 추가적인 메모리 BW를 소모하지 않는다.
Disadvantage
그러나 DC miss가 났을 때 OS handler 코드가 실행되면서 application thread는 멈추게 된다. 여기서 OS miss handler는 크게 2가지 기능을 수행하는데, 1) physical frame과 cache frame의 mapping 정보를 kernel data structure에 기록하고, PTE의 PFN을 CFN으로 수정하는 것 (tag management) 과 2) off-package memory로부터 DRAM cache로 page를 복사해오는 것 (data management) 이다. 이로 인해 ~수천 cycle이 소모되며, 이 중 2)의 cache-fill의 실행 시간이 주요 요인이다.
2.3 Motivation
Miss handling mechanism의 영향을 알아보기 위하여, 여기서는 TDC(=OS-managed), TiD(=HW-based)의 2가지 선행 연구의 방식에 대해 cycle-level simulator 상에서 workload를 실행시켜 그 결과를 측정하였다. 여기서 RMHB, LLC MPMS의 2가지 지표는 각각 workload 고유의 off-package memory, LLC에서 miss handling BW 요구량이고, 요구량이 큰 것에서 작은 것 순으로 excess-tight-loose-few의 4가지 그룹으로 workload를 분류하였다.
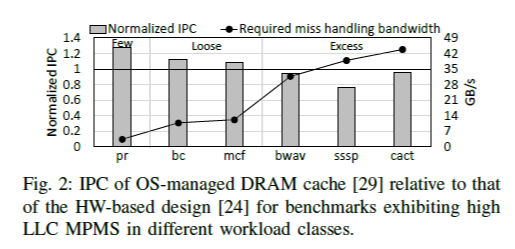
Figure 2를 보면 miss handling BW가 작은 경우 OS-managed가 더 좋은 성능을 보이며, 이는 HW-based에서 metadata 접근으로 인한 추가적인 latency의 영향이다. 반면, miss handling BW가 커질수록 OS-managed의 blocking으로 인한 miss handling latency가 dominant 하게 되어 HW-based에 비해 더 성능이 안 좋아진다.
3 NOMAD Cache Design
3.1 Decoupled Tag-Data Management Scheme
OS-managed의 가장 큰 한계점은 miss 시 application을 stall 해야 한다는 것인데, 그 이유는 OS가 cache fill을 수행하기 때문이다. 따라서, 본 논문에서는 근본적인 한계점을 해결하는 non-blocking OS-managed DC를 만들기 위해 tag-data management를 분리시키는 방식을 제안한다. 여기서는 DC miss가 났을 때, front-end OS는 tag만을 업데이트하고 application thread는 바로 실행을 이어가도록 한다. 대신 back-end HW가 cache-fill command를 실행한다.
그 대신 이제 tag hit이 data hit까지를 보장하지 않으므로 DC access마다 tag hit이 나더라도 back-end HW를 살펴봐서 data hit 여부를 확인해야 한다. 이러한 추가적인 overhead가 있으나, 그럼에도 non-blocking miss handling을 할 수 있게 됨으로써 miss handling latency를 줄일 수 있다.
3.2 Overall Structure

Figure 3에서 보는 것과 같이 NOMAD는 DC tag를 관리하는 front-end OS와 데이터를 관리하는 back-end HW로 구성된다.
TLB hit/miss 여부에 따라 TLB 또는 page table walk를 통해 PTE를 얻을 수 있고, 여기서 요청된 데이터의 caching 여부를 확인한다. 만약 데이터가 caching 되어 있지 않다면, 우선 새로운 cache frame을 할당하고, DC tag miss handler가 새롭게 바뀐 tag 정보를 kernel data structure에 업데이트한다. 여기까지가 끝나면 application thread의 실행을 이어가고, 나머지 data에 관한 처리는 back-end HW가 이어서 수행한다. Eviction 시에도 mapping 정보에 관한 restore만을 수행하고, writeback이 필요한 경우 back-end HW로 offloading 한다.
Back-end HW는 PCSHR (page copy status holding register)를 두어 front-end로부터 온 command들을 저장한다. 핵심 기능은 front-end로부터 cache-fill 또는 writeback command를 받은 것을 실제로 실행하며, 중간 진행 상황을 HW에 적절히 기록해두는 것이다. 한편, TLB hit이 났어도 여기서의 tag hit이 data hit을 보장하지는 못하므로, back-end HW를 검사하여 요청된 데이터 블록이 존재하는지를 확인한다. 이것은 PCSHR에 match가 있는지 여부를 통해 확인할 수 있고, 만약 match가 있다면 아직 data transaction은 진행 중이므로 data miss이며 진행 상황에 따라 대기한 뒤 service 하게 된다.
3.5 Analysis of Effective Cache Access Latency
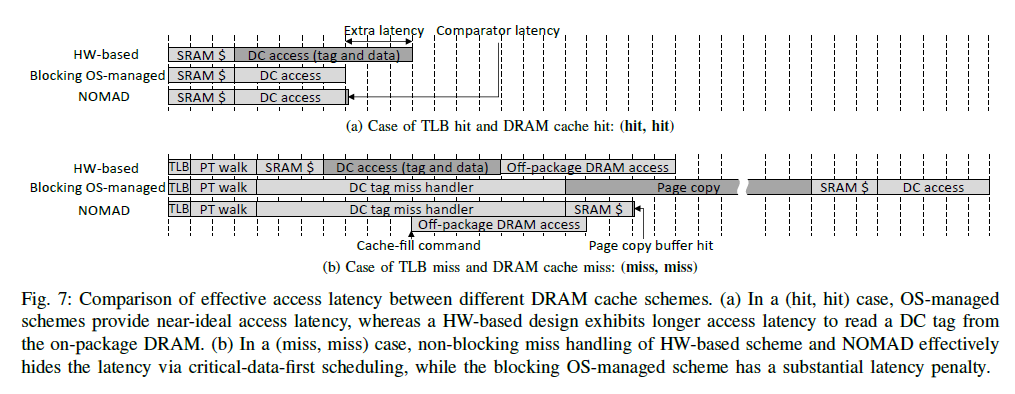
Figure 7은 TLB, DC의 (hit, hit)과 (miss, miss)인 경우에 latency가 어떻게 나타나는지에 대한 분석이다.
HW-based의 경우 (hit, hit) 시에 tag와 같은 metadata를 접근하는 데에 추가적인 memory BW를 소모하여 latency가 길게 나타난다. OS-managed는 (hit, hit) 시에 TLB hit으로부터 metadata까지 얻기 때문에 ideal한 latency를 얻지만, (miss, miss) 시에는 blocking mechanism으로 인해 긴 latency를 보인다.
NOMAD design의 경우 (hit, hit) 시에 near-ideal latency를 보이는데, OS-managed에 비해 추가된 약간의 latency는 back-end HW의 PCSHR entry와의 비교를 통한 data hit 판단 overhead 이다. 또한, (miss, miss) 시에는 miss handling latency를 hiding 하는 효과를 얻는데, DC tag miss handler가 cache-fill을 back-end HW에 offloading 하고 바로 application thread 실행을 이어가기 때문이다. 미리 back-end HW가 cache-fill을 시작한 상태이므로, application thread의 실행을 다시 이어간 뒤 DC에 접근했을 때는 page copy buffer hit이 날 가능성이 매우 높다. (실험 결과 약 91.6%의 경우 page copy buffer hit)
4 Evaluation

Workload class 분류는 excess가 miss handling BW를 많이 요구하는 것, few로 갈수록 적게 요구하는 것이다. TiD, TDC는 각각 HW-based, OS-managed 방식이며, ideal은 miss handling penalty가 없는 경우로서 design의 upper bound를 의미한다.
결과를 보면, few class에서는 OS-managed TDC의 성능이 좋게 나타나며 이는 ideal hit latency를 갖기 때문이다. 하지만 excess class로 갈수록 blocking miss handling으로 인해 latency가 늘어나서 성능이 안 좋아진다. HW-based의 경우 excess class의 경우 non-blocking 방식으로 인해 DC miss에 대응을 잘 해서 성능이 좋게 나타나지만, few로 갈수록 metadata 접근에 드는 추가적인 memory BW의 효과가 크게 나타나 성능이 안 좋게 나타난다. NOMAD는 non-blocking을 가능하게 함과 동시에 near ideal hit latency를 갖기 때문에, 이들의 약점을 모두 보완하여 더 좋은 성능을 얻을 수 있었다.



