1 Introduction
현재 널리 사용되는 radix-tree page table은 메모리를 효율적으로 사용하고 caching 구조에 최적화되어 있지만, scalability가 떨어진다는 한계점이 있다. Tree 계층 구조를 따라 sequential한 메모리 접근을 해야 하므로, memory-level parallelism을 활용할 수 없다.
이에 대한 하나의 대안은 hashed page table (HPT) 이다. VPN을 hashing한 값을 table의 index로 하여 entry를 접근하고, collision이 없는 효율적인 hashing을 사용한다는 전제 하에 이상적으로 1번의 메모리 접근만으로 address translation을 할 수 있다. 그러나 HPT는 크게 4가지의 이유로 인해 그동안 사용되지 못했다. 1) 연속적인 virtual page의 entry들이 scattered 하게 분포하여 spatial locality를 활용할 수 없다. 2) Hash tag (=VPN)를 entry에 저장해야 하는 추가적인 overhead가 있다. 3) Hash collision을 handling하기 위한 cost가 크다. 4) 모든 active process에 대한 translation을 저장하는 하나의 global HPT를 만드는 것이 어려우며, per-process HPT의 경우 sizing에 대한 문제가 있다.
HPT에 대한 선행 연구가 진행되며 위의 challenge들을 개선해왔다. 1) 하나의 cache line에 연속적인 page translation을 함께 저장함으로써 locality를 개선하였다. 2) 각 entry의 unused bit을 이용하여 hash tag를 저장하였다. 3) Hash conflict를 효율적으로 대응할 수 있는 Cucko hashing을 사용하였다. 4) Per-perprocess HPT를 초기에 작은 크기로 만들어두고, 요청에 따라 dynamic하게 resize할 수 있도록 하였다.
그러나 그럼에도 HPT는 상당히 큰 연속적인 physical memory를 요구하고, 이것이 큰 challenge가 된다. Radix-tree PT의 경우 항상 single page 단위로 할당을 하기 때문에 이것이 문제가 되지 않는다.
이에 여기서는 memory efficient한, discontiguous physical memory chunk 단위로 HPT를 구성하는 방법을 제안한다. 또한, HPT가 차지하는 메모리 용량을 줄임으로써 contiguity requirement를 완화하는 방법도 제안한다.
ME-HPT (Memory efficient) design의 성능 측정을 위해 memory-intensive한 workload를 full-system simulation 하였다. 그 결과, ME-HPT는 기존 HPT들에 비해 contiguous memory allocation에 대한 요구를 92% 줄였고, performance(=speedup)를 평균적으로 8.9% 향상시켰다. 또한 radix-tree PT에 비해서도 speedup을 약 1.2~1.3배 달성하였다.
2 Background
2.1 Limitations of Radix-Tree Page Tables

현대의 프로세서들이 대부분 사용하는 radix-based page table의 경우, TLB miss가 발생했을 때 PA->VA로의 translation을 얻기 위해 HW가 트리 구조의 page table을 sequential하게 walk 해야 한다. Page table walk의 cost를 줄이기 위해 intermediate PTE들을 위한 cache를 두기도 하지만, 여러 어플리케이션에서 cache overflow가 발생하여 추가적인 memory access를 발생시킨다. 또한 메모리 용량이 확대되는 추세 속에서 앞으로는 page table의 계층이 4개보다 더 늘어날 수 있음을 고려한다면, scalability가 떨어진다는 한계점이 있다.
2.2 Hashed Page Tables
Concept
Hashed page table (HPT)은 VPN을 hashing한 값을 index로 하여 page table에 접근한다. 이상적으로 collision이 없다면 메모리 접근을 1번만 하면 된다는 potential benefit이 있다.
Challenges
그러나 그 동안 몇 가지 challenge들로 인해 널리 사용되지 못하였다. 1) 연속적인 virtual page의 page table entry가 흩어져 있기 때문에 spatial locality를 효과적으로 활용할 수 없다. 2) Page table entry에 hash tag를 추가적으로 저장해야 한다는 overhead가 있다. 3) 실제로는 hashing collision으로 인해 추가적인 메모리 접근이 발생한다. 4) 모든 프로세스에 대한 single global HPT를 만드는 것이 불가능하다.
Recent works
최근 선행 연구들은 HPT의 위 challenge들을 일부 해결하였다. Cacheline 크기의 연속적인 page table entry를 cluster로 묶어서 하나의 HPT entry로 만들었다. 이렇게 함으로써 spatial locality 문제를 개선할 수 있다. 또한, 연속적인 page table entry에서 사용되지 않는 upper bit을 hash tag 저장에 사용함으로써 hash tag overhead도 개선할 수 있다.
Collision 문제는 HPT를 W-way set-associative로 만들고, 각 way들은 서로 다른 hash function을 이용하도록 함으로써 개선하였다. 새로운 element p를 삽입할 때, hashing index에 이미 다른 element가 있다면 해당 element는 다른 way의 hash function으로 hashing 한 뒤 새로운 entry에 삽입되도록 한다. 그 위치에 또 다른 element가 있다면, 위와 같은 re-insertion을 일정 횟수 반복하는 것이다. Element lookup 시에는 W way를 parallel하게 확인한다.
Elastic Cuckoo Page Table (ECPT)는 per-process private HPT를 사용하며, 처음에는 크기를 작게 초기화한 뒤 HPT의 크기를 dynamic하게 resizing 하는 design을 제안한다. 현재 HPT의 occupancy를 확인하여 upsize/downsize operation이 일어나며, 이는 프로세스가 실행 중일 때 동시에 일어날 수 있다.
Elastic Cuckoo Page Table: Upsize Operation
HPT occupancy가 threshold 이상이 되면 새로운 double-sized HPT가 할당된다. 그 이후에 OS가 HPT에 새로운 element를 삽입할 때마다, 하나의 element를 old HPT -> new HPT로 rehash 하여 옮기는 동작을 실행한다. Rehashing pointer P_i는 W-way old HPT의 각 way마다 존재하고, 이 way의 HPT에 대해 rehashing을 할 영역의 시작 지점을 가리키며, 동시에 이 지점은 이미 new HPT로의 migration이 끝난 직후의 지점이기도 하다.
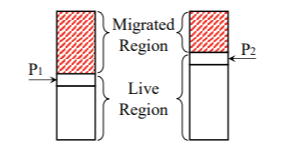
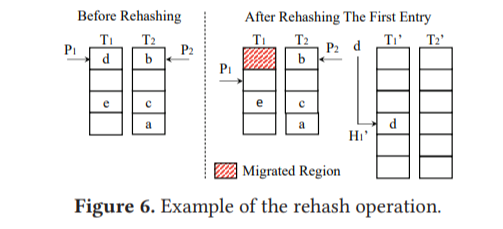
Rehashing이 일어날 때는 rehashing pointer P_i가 가리키는 element를 rehashing 하여 new HPT에 삽입한 뒤, P_i를 증가시킨다. Old HPT의 모든 영역이 migration 되면 upsize가 종료되고, old HPT는 deallocate 된다.
Resizing이 일어나는 도중에 새로운 element의 insertion은 다음과 같다. 우선 random하게 하나의 way를 선택하여 hashing을 한다. 이 값을 P_i와 비교하여 migrated/live region 중 어느 영역에 속하는지를 판단하고, live라면 그대로 old HPT에 삽입하고, migrated이면 새로운 hash function으로 다시 hashing 하여 new HPT에 삽입한다.
Resizing이 일어나는 도중에 lookup은 최대 W번 탐색을 하게 되며, 각 way마다 hash function으로 hashing하여 live/migrated 영역을 판단하고, live라면 old HPT를, migrated라면 new HPT의 entry를 읽어온다.
3 Motivation
HPT에 관한 선행 연구들이 개선을 이루었지만, 그럼에도 가지는 근본적인 한계는 W-way HPT에서 하나의 way에 대해서는 연속적인 physical memory를 요구한다는 것이고, 이를 만족시키는 것이 어렵다는 것이다. Radix-tree PT는 9-bit 단위로 hierarchical하게 구성되므로, 2^9 * 2^3B = 4KB의 연속적인 공간만 확보되면 된다. 하지만, 본 논문의 조사에 의하면 HPT의 경우 어플리케이션에 따라 최대 64MB의 연속적인 공간을 요구하기도 한다. Highly-fragmented 메모리에서 64MB의 연속적인 공간을 할당하는 것은 거의 불가능하고, 이로 인해 HPT가 사용될 수 없다.
또한 page table이 차지하는 메모리 용량도 HPT가 radix-tree에 비해 크며, 이후에 서술할 본 논문의 솔루션을 통해 HPT의 메모리 용량을 줄임으로써 memory contiguity requirement를 완화할 수 있음을 보일 것이다.
4 Designing Memory-Efficient HPTs
HPT의 contiguity에 대한 솔루션으로서 크게 4가지의 HW-assisted 방법을 제안한다.
4.1 Logical to Physical (L2P) Table
기존 HPT는 way 당 contiguous memory가 필요한데 (Figure 2의 왼쪽), VPN을 hashing한 값을 HPT base에 더한 값을 index로 하여 접근하기 때문이다.
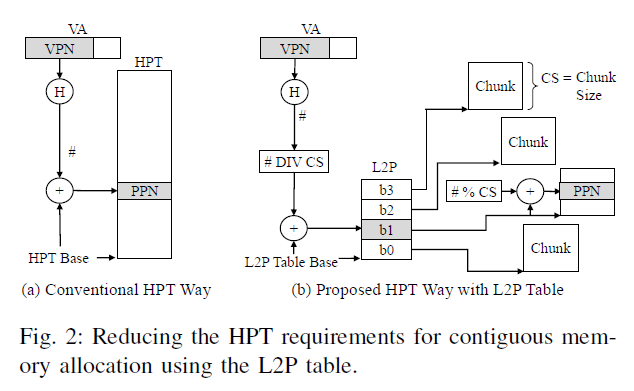
이에, 본 논문에서는 HPT를 여러 개의 ChunkSize (CS) 크기의 chunk 단위로 나누어 구성한다. 그러면 chunk들끼리는 contiguous하지 않아도 된다. Logical to Physical (L2P) table에는 각 chunk의 base 주소가 저장되어 있다. VPN의 hashing한 값을 CS로 나눈 몫으로 L2P table을 접근하여 chunk의 base 주소를 얻고, CS로 나눈 나머지를 offset으로 하여 chunk 내의 entry를 접근한다.
MMU는 현재 running 중인 프로세스에 대해서만 L2P table을 가지고 있다. 프로세스 간 L2P table의 save/restore은 context switch 시에 OS에 의해 이루어지도록 한다. L2P table의 크기가 작기 때문에 이로 인한 overhead는 작다. CS의 값은 2의 지수 승이기 때문에 division, modulo operation을 효율적으로 할 수 있다. L2P table로 인한 추가적인 overhead는 약 2 cycle로 추산하였고, Elastic Cuckoo Page Table (ECPT)의 design에서 Cuckoo Walk Cache (CWC) 접근과 overlap 됨으로써 overhead는 hide 될 수 있다.
4.2 Dynamically Changing Chunk Sizes
L2P table 접근으로 인한 overehead를 최소화하기 위해 L2P table의 entry 수가 작아야 하고, HPT 전체 메모리 용량을 고려한 적절한 CS 값의 설정이 중요하다. 그러나 big data application의 경우 MB 단위의 CS 값이 적절하고, system service긔 경우 수 KB만으로도 적절한 등 어플리케이션에 따라 HPT 용량의 requirement가 다르다. 이에, 어플리케이션에 따라 chunk size를 dynamic하게 바꾸는 방법을 제안한다. 시스템이 지원할 chunk size의 set을 사전에 정의해둔 뒤, 어플리케이션의 요구에 맞추어 chunk size를 바꾸는 것이다.

Example
위 Figure 3의 example은 L2P table의 entry 수는 64개, 지원 가능한 chunk size는 {8KB, 1MB}의 2개이다. (a)에서 어플리케이션의 초기 HPT 용량은 4KB이다. (b)는 (a)에서 HPT의 크기가 2배로 증가한 경우이며, 이 때는 이미 할당되어 있는 8KB chunk의 second half를 채우면 된다. (c)에서 다시 HPT의 크기가 8KB->16KB로 증가하면, 이번에는 새로운 8KB chunk가 할당되고, L2P table에도 새로운 entry가 생긴다. L2P table의 전체 entry 수 64개가 모두 채워질 때까지 이런 방식으로 double이 일어나고, 이는 최대 64*8KB = 512KB 용량까지를 지원할 수 있다. (d)
Doubling이 한 번 더 일어나면 8KB->1MB로 chunk size의 transition이 비로소 일어난다. 하나의 1MB chunk를 새롭게 할당하고, 모든 old chunk들을 rehashing을 하여 새로운 chunk로 옮기고, old chunk들을 free 한다. (e) 그 이후의 doubling에서는 1MB chunk를 새롭게 할당하고, L2B table의 entry 수도 할당에 따라 늘어나게 된다.
이를 통해 메모리 요구량이 다른 다양한 어플리케이션에 대해 HPT는 메모리를 효율적으로 사용할 수 있다. 이 기능을 MMU에서 HW적으로 지원하기 위해, 현재 사용 중인 chunk size 값과 upsizing이 chunk size의 변화를 필요로 하는지 여부를 기록할 수 있는 추가적인 bit을 둔다.
4.3 In-place Page Table Resizing
ECPT는 프로그램 실행을 멈추지 않고 동시에 HPT의 크기를 resizing 한다. Resizing이 진행되는 도중에 old HPT, new HPT가 모두 메모리에 존재하게 되는데, 본 논문에서는 이것이 HPT 메모리 consumption의 비효율성이라고 주목하였다. 실제로 전체 실행 시간 중 약 87% 동안 계속해서 resizing이 일어나기 때문에 old, new HPT가 동시에 메모리에 존재하는 시간이 매우 많으며, 여러 개의 process가 동시에 실행될 때는 HPT가 per-process마다 존재하므로 이로 인한 overhead가 더 커진다.
ECPT의 resizing 및 rehashing의 매커니즘은 OS가 HPT에 새로운 entry를 삽입하는 operation을 할 때 하나의 entry를 rehash(=new HPT로 옮기기) 하는 것이다. 물론 OS thread 하나를 만들어 모든 old entry를 rehash 하도록 할 수도 있으나, 이것은 overhead가 크기 때문에 기존 OS invocation 매커니즘을 활용한 것이다.
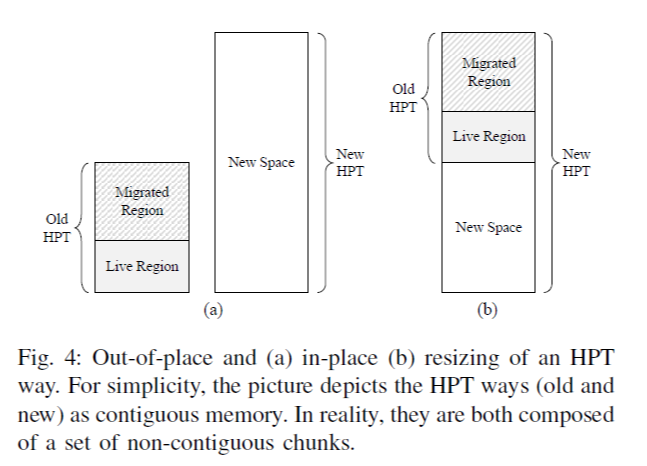
본 논문에서는 figure 4와 같이 old, new HPT가 동일한 physical memory space를 사용하도록 한다. (Figure 4는 upsize operation 기준, single way HPT만을 나타냄. 또한 4.1의 desing에 의해 실제로는 하나의 contiguous 대신 chunk-wise contiguous하게 구성되나, 여기서는 simplicity를 위해 위와 같이 표현함) 기존 ECPT의 경우, insertion/rehashing은 live region 또는 new space에만 위치할 수 있었다. 하지만, 여기서는 insertion/rehashing 시 migrated region에도 포함될 수 있도록 하였는데, 이것이 new HPT에도 여전히 속하기 때문이다. old, new HPT는 서로 같은 hash function을 사용하되, 영역의 확장(downsize 시 축소)을 위해 new HPT의 index에는 추가적인 bit(downsize 시 1-bit을 제외)을 MSB에 둔다.
Algorithm with example
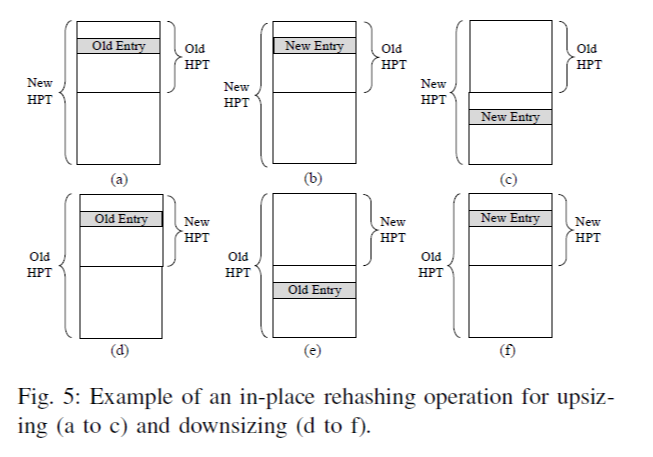
HPT resizing이 일어날 때, way i에서 rehashing pointer P_i가 가리키고 있는 element를 old HPT로부터 new HPT로 옮기는 operation을 수행한다. Rehashing을 수행할 대상이 figure 5 (a)에 표시되어 있다. New HPT에 대해서도 VPN을 같은 hash function으로 hashing 하는데, 추가적인 MSB가 1-bit 더 존재하므로 (b), (c)의 두 가지 indexing이 가능하다. (b)는 기존 위치가 되고, (c)는 MSB가 1인 경우에 새로 할당된 영역의 위치가 된다. Hashing 결과에 따라 (b), (c) 중 하나로 indexing 하여 그 곳에 rehashing 대상이 되는 entry를 위치시킨다.
Downsize 시에는 (d), (e)에서 표현되듯이 2개의 old entry가 (f)의 새로운 영역의 같은 new entry로 mapping 된다. 이 때는 둘 중 하나가 cuckoo hash에 의해 다른 way로 들어간다.
Other operations
Lookup의 경우, old hash function으로 VPN을 hashing 하여 P_i 보다 작다면 MSB가 추가된 new hash key를, P_i보다 같거나 크다면 old hash key를 그대로 index로 하여 HPT에 접근한다. Way 당 1번의 memory access만이 필요하다.
Delete의 경우 lookup과 같은 방식으로 element를 찾은 뒤 clear 한다.
Insertion은 우선 random하게 way i를 선택한 뒤, old hash function으로 hashing한 값을 P_i와 비교하여 old hash key/new hash key로 entry를 접근하여 삽입한다. Conflict가 발생할 경우 cuckoo 매커니즘을 통해 다른 way로 삽입된다.
In-place resizing은 chunk size가 변하지 않을 때만 일어난다. Chunk size가 변할 때는 새로운 연속적인 physical memory로 복사를 해야하므로, out-of-place resizing을 한다.
4.4 Per-way Resizing
기존의 HPT들은 W-way set associative 방식으로 구성하는데, 이는 resize 시 모든 way를 대상으로 resize operation을 하기 때문에, 약간의 추가적인 메모리 요구가 있을 때에도 전체를 resize해야 한다는 inefficieny가 있다. 이에, 본 논문에서는 per-way resizing, 즉 한 번에 하나의 way만 upsize/downsize 하는 방식을 제안한다.
Deciding which way to upsize/downsize
기존에는 OS가 전체 HPT의 occupancy를 추적하고, 이를 바탕으로 HPT의 resize 여부를 결정한다. 여기서는 OS가 각 way 별 occupancy를 추적하도록 한다. Way들 간에 balance를 유지하기 위해서, upsize 하고자 하는 way가 다른 way들보다 이미 크기가 크다면 upsize 하지 않는다.
Deciding where to insert an element
기존에는 insertion 시에 random하게 하나의 way를 선택했는데, per-way resizing에서도 이렇게 한다면 더 큰 크기를 할당받은 way를 충분히 활용하지 못하는 문제가 있다. 이에 weighted random insertion을 제안한다. OS가 way 별로 occupancy를 추적하고 있으므로, 각 way 별 free slot의 수를 weight으로 하여 random하게 선택한다. 그러면 free slot이 많을수록 insertion 될 확률이 높다. 어떤 way가 직전에 upsize가 되었다면 여기에 free slot이 많아 당분간은 upsize된 이 way로 더 많이 insertion 될 것이다.
5 Implemention Aspects
5.1 L2P Table Entry Stealing
L2p table의 entry 수는 각 page 당 32개로 하였다. 여기서 지원하는 page size는 4KB, 2MB, 1GB의 3가지이고, 만약 3개의 way를 둔다면 총 9개의 L2P subtable이 존재한다.

이 때 모든 3개의 subtable이 비슷한 빈도로 많이 사용되는 경우는 잘 없기 때문에, 이들 간의 entry stealing을 허용하여 많이 사용되는 page size의 L2P subtable이 더 많은 entry를 가질 수 있도록 한다. Figure 6의 (b)를 보면 4KB page에 대한 HPT 요구가 많아서 가운데 영역까지 확장된 것을 볼 수 있다. 그 이후에 1GB page에 대한 HPT L2P table entry가 필요하다면, (c)와 같이 사용되지 않는 2MB 영역을 사용하게 된다.
다른 page size의 stealing으로 인해 L2P table entry가 모두 사용 중이 되어버린다면, 본문에 나와있지는 않지만 어떤 page size에 대해서 chunk size를 늘림으로써 entry의 수를 다시 줄일 것이다.
5.2 Chosen Chunk Sizes
여기서는 {8KB, 1MB}의 2가지 chunk size를 사용한다. 만약 1MB chunk에 대해서 64개의 entry를 모두 사용한다면 HPT가 64MB 이상을 요구하는 것인데, 사전에 조사한 workload에 대해서 이런 경우는 없었기 때문에 실험 setting에서는 이렇게 둔 것이다. 물론, 이것은 OS에 의해 확장될 수 있다.
L2P table의 크기는 8KB chunk, 3-way 기준으로 프로세스 당 1.16KB로 계산되었으며, 이것은 적절한 크기의 overhead이다.
5.3 Scalability of L2P Tables with Changing Chunks

Chunk size를 다르게 함으로써 HPT는 어플리케이션이 필요로 하는 다양한 범위의 memory mapping을 제공할 수 있다. 예를 들어, 8KB일 때를 살펴보자. 하나의 way 당 최대 HPT 크기는 8KB * 64 = 512KB이다. 이 때, entry 수로 환산하면 512KB/8B = 64K 개이다. (여기서 직접 언급되지는 않았지만 PTE의 크기가 8B라는 가정이 있는 것으로 보인다) 하나의 mapping 당 4KB page에 대응되므로, 64K * 4KB * 3 way = 768 MB의 mapping을 제공할 수 있다.
큰 chunk를 할당하기 위해서는 contiguity가 필요한데, 이 때 필요에 따라서 OS의 memory compaction operation이 수행될 것이다.
5.4 Hiding the Access to the L2P Table
Page table walk에서 L2P table 접근은 overhead로 작용하지 않는데, 이를 CWC (Cuckoo Walk Cache) 접근과 parallel하게 수행함으로써 latency를 hiding 할 수 있기 때문이다.
6 Experimental Methodology
Full-system cycle-level 시뮬레이션을 하며, 8 core, 64GB의 서버 환경을 모델링한다. Baseline은 ECPT, radix-tree PT이다. Application은 graph processing, HPC, bioinfo 등의 다양한 분야의 benchmark를 테스트하며, 이들이 Simic 에 의해 capture 되어 cycle-level simulator에서 실행되는 방식이다.
7 Evaluation
7.1 Memory Contiguity Savings

Figure 8을 보면 ECPT에 비해 contiguous memory allocation이 평균적으로 92% 정도 줄었다. (THP 없이) 값을 보면 항상 8KB, 1MB인 것을 볼 수 있는데, contiguity를 chunk size 단위로만 요구하기 때문이다.
7.2 Application Performance

ECPT에 비해 약 1.09x의 speedup을 얻었고, radix-tree page table에 비해서는 약 1.23x의 speedup을 얻었다. ECPT에 비해 speedup을 얻은 이유는 contiguity requirement가 낮아지면서 memory allocation cost가 더 낮아졌기 때문이다.
7.3 Memory Savings

평균적으로 ECPT의 page table 메모리 사용량의 43%를 아낄 수 있었다. Figure 10의 bar는 per-way resizing, in-place resizing으로 인한 각각의 contribution 퍼센트를 표현한다. 이를 보면 in-place resizing이 75~80%, per-way resizing이 25~20%만큼 기여한다.
7.4 Why Reducing the Page Table Size Matters
Page table의 크기는 수 MB 단위이지만, 이를 줄이는 것이 의미있는 이유는 이를 통해 contiguous allocation requirement를 더 완화할 수 있기 때문이다. Page table의 크기가 줄어들면 L2P table도 더 효율적으로 쓸 수 있고, contiguous chunk 자체를 더 적게 쓸 수 있다. L2P table이 overflow 되면 더 큰 chunk size를 요구하기 때문에, 이를 효율적으로 사용하는 것은 중요하다.



