이번 lecture에서는 computer vision 분야에서 사용되는 neural network를 구성하는 중요한 개념인 convolution layer에 대해 공부해본다.
Convolution Layer: How it works?
Idea: Compared to FC Layer...

이전 lecture에서 다뤘던 fc layer의 경우, 우선 input을 N*1 형태의 벡터로 표현한 뒤 weight matrix와의 행렬 곱을 통해 activation number를 얻었다.
fc layer과 비교했을 때 convolution layer에서 가장 큰 차이점 중 하나는 spatial dimension을 유지한다는 것이다.

위의 슬라이드와 같이, 3차원 형태의 input 그대로 3차원 filter와 convolution 연산을 해서 2차원 activation map을 얻는다. 아래 슬라이드를 보면 3차원 데이터 간 convolution 연산과 그 연산 결과인 2차원의 activation map이 그림으로 잘 나타나 있다.
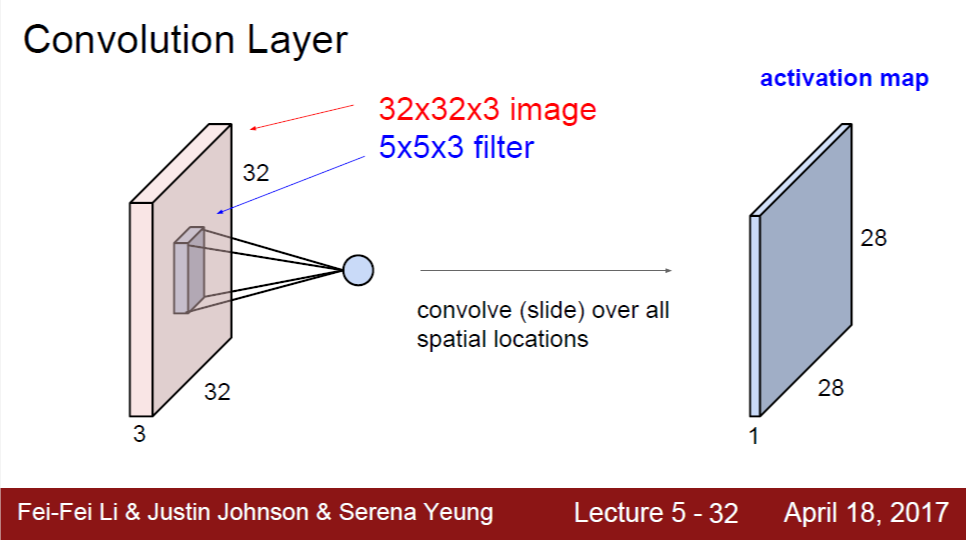
Recall: Definition of Convolution
두 개의 3차원 데이터 f, g가 있을 때, 이들의 convolution은 아래 수식의 1번째 줄과 같이 정의된다.
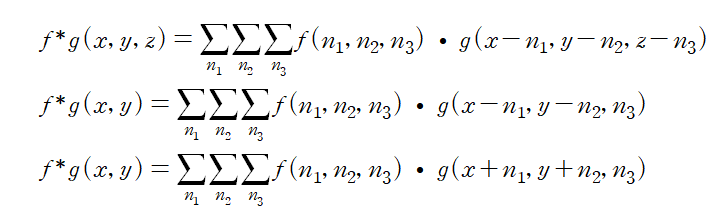
그런데, convolution layer에서는 convolution 결과에서 3번째 dimension이 없어지도록 되어 있다. 이는 다른 말로, 두 데이터 f, g의 3번째 dimension이 일치한다는 것이다. 강의에서는 이를 'filter has full depth with input' 이라는 표현을 사용하였다. 두 데이터가 곧 이미지에 대응되는 input과 filter이므로, 이들이 같은 depth를 갖는다는 것이다. 이러한 특징을 고려하여 위 수식의 2번째 줄과 같이 표현될 수 있다.
기존 convolution 정의와 또 다른 점 중 하나는 filter가 reverse되지 않고 바로 input과 곱해진다는 것이다. 이를 반영하여 3번째 줄과 같이 최종적으로 표현된다. filter의 reverse 여부가 큰 상관이 없는 이유는, convolution layer에서 말하는 convolution 연산은 input 데이터의 일부와 filter 간의 elementwise multiplication을 한 후 모두 더하여 하나의 숫자를 얻는 것이 핵심이기 때문이다. 따라서 reverse를 고려하여 연산을 해도 되지만, 굳이 filter reverse가 갖는 의미가 없으므로 이 연산은 생략해도 된다.
4 Hyperparameters: Number of Filters, Filter Size, Stride, Padding
하나의 convolution layer에 대해서 4개의 hyperparameter가 정의될 수 있고, 이를 그림으로 표현한 것은 아래와 같다.
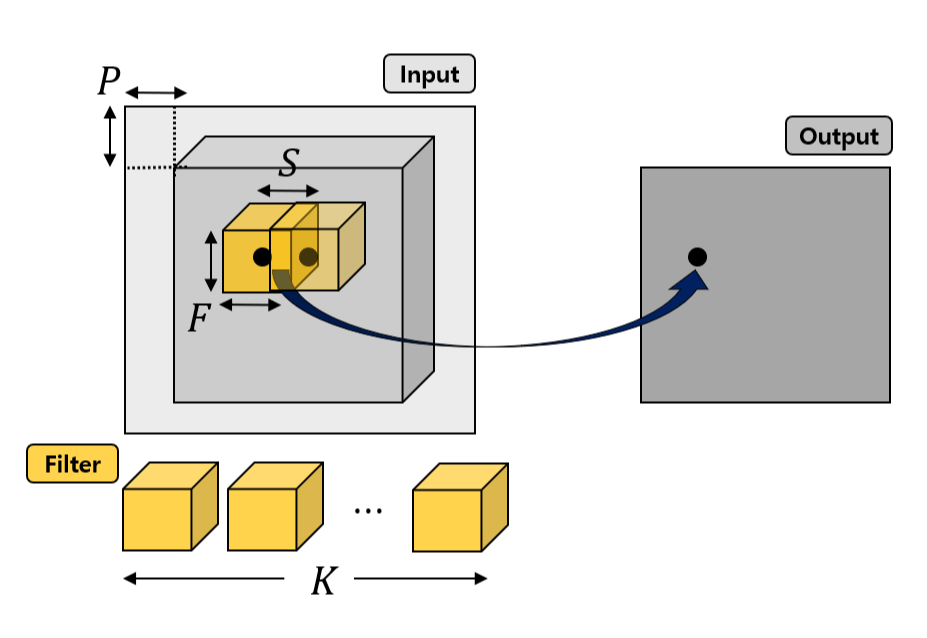
1) Filter Size (F): 하나의 filter는 3차원인데 depth라고 불리는 3번째 dimension은 input에 의해 자동으로 결정된다. 1, 2번째 dimension은 서로 같은 것이 일반적이며, 이 길이가 곧 filter size이다.
2) Number of Filters (K): 하나의 filter에 의해 output은 하나의 2차원 activation map이 형성된다. filter는 일반적으로 하나가 아니라 여러 개이며, filter 개수만큼 2차원 activation map이 생긴다. Number of filters는 output의 depth dimension과도 같다.
3) Stride (S): filter의 중심 좌표를 (x, y, z)라고 했을 때, convolution 연산을 하면서 filter가 input의 2차원 공간을 쭉 훑게 된다. 이 때, 이 훑는 간격을 몇으로 하느냐이다. 디폴트는 1이고, input의 모든 2차원 공간을 대상으로 계산하는 것이다. 만약 stride가 2라면 하나씩 건너 뛰고 filter가 input 공간을 훑는 것이 된다.
4) Padding (P): 예를 들어 filter size가 3이라면 output을 input 좌표 (0, 0)을 중심으로는 계산할 수가 없고 맨 처음 계산 가능한 input 좌표가 (1, 1)이다. 왜냐하면 (0, 0)을 중심으로는 filter가 input 공간 안에 포함될 수 없기 때문이다. padding이 없다면 이렇게 양 끝 점들이 사라지는 것 때문에 output의 spatial dimension이 작아지게 된다. 그래서 일반적으로 양 끝을 zero padding 하여 input의 2차원 dimension이 output에서도 유지될 수 있도록 한다.
Practice: Dimension of Convolution
fc layer의 경우, output dimension이 행렬 곱 dimension에 의해 바로 결정되는데, convolution layer의 경우 위에서 소개한 4가지 hyperparameter들이 모두 output dimension에 영향을 주기 때문에 이를 모두 고려하여 dimension을 결정하게 된다. 강의에서 다룬 예제를 통해 연습해보자.
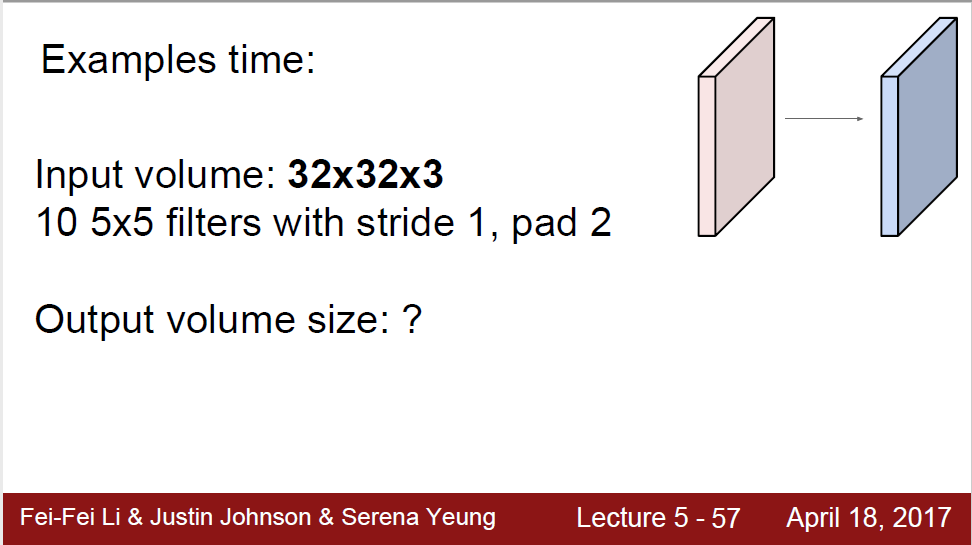
만약 padding이 없었다면, input 좌표 (2, 2)부터 시작해서 맨 마지막에 (29, 29)까지 계산 가능하다. filter의 크기가 5이기 때문에 좌우로 2칸이 확보되어야 filter가 input 공간 안에 모두 포함되어 연산이 가능하기 때문이다. 그런데, 양쪽에 2씩 zero padding을 해주게 되면, input 좌표 (0, 0)부터 시작할 수 있고, 맨 마지막에도 (31, 31)까지 계산 가능하다. zero padding을 양 끝에 2칸씩 해주었으므로, (0, 0), (31, 31) 등의 좌표를 중심으로 해도 좌우로 2칸이 확보되기 때문이다. 따라서, output의 2D dimension은 input의 크기를 그대로 유지할 수 있어서 (32, 32)이다.
output의 depth는 곧 filter의 수와 같다. 총 10개의 filter가 있고, 서로 다른 10개의 2D 32 by 32 activation map이 만들어진다. 즉 depth는 10이다.
강의에서 추가적으로 parameter가 몇 개인지를 다루었는데, filter의 숫자를 세면 된다. 여기서는 (5*5*3)*10=750이다. 그리고 bias도 있는데, 이것은 하나의 activation map에 대해서는 모두 동일하게 더해지게 된다. 즉, bias의 수는 filter의 수, output의 depth와 같다. 예제의 경우, filter의 parameter 750개, bias 10개를 더한 760개의 parameter가 나온다.
Max Pooling Layer
Max pooling layer는 아래 그림과 같이 input 데이터를 downsampling 하는 것이다.

Downsampling은 각 activation map 내에서 이루어지기 때문에, input 데이터의 1, 2번째 dimension은 줄어들지만, 3번째 dimension인 depth는 유지된다.
위 그림의 예시에서는 2*2 input 중 가장 큰 1개를 골라서 sample하는 방식으로 downsampling이 이루어지고, 1, 2번째 dimension 모두 절반으로 줄어들게 된다.
Hyperparameters & Parameter
Convolution layer에서 filter size에 해당하는 hyperparameter F가 여기서도 유사하게 정의될 수 있는데, 하나의 output sample을 만들어낼 input 묶음의 크기에 해당한다. 위 예시의 경우 F=2가 된다.
Stride(S) 역시 동일하게 정의되며, input 데이터의 묶음을 몇 칸 씩 건너뛰며 다음 sample을 얻을지에 대한 것이다. 디폴트는 S가 F와 같은 것인데, 기본적으로 max pool 시 input 데이터 간 겹치지 않고 다음 sample을 얻기 때문이다.
물론 S가 F보다 작아서 overlap이 있는 경우도 존재하며, 아래 그림과 같이 F=3, S=2를 들 수 있다. 이 경우, 하나의 input 열이 다음 sample을 얻는 과정에서 한 번 더 쓰이게 된다.

Intuition on Convolutional Neural Network
Convolution layer이 image classifier 관점에서 어떤 동작을 하는지를 이해해보자.
먼저, fc layer 하나로만 구성된 경우, 즉 linear classifier의 한계 중 하나는 하나의 class 당 오직 하나의 template만을 학습한다는 것이었다. Training을 진행한 결과, weight matrix의 row가 곧 class에 대한 template이 된다. Test 시, 이미지를 각 class의 template과 유사도를 측정하여 label을 얻는 방식이었다.
그 다음으로 linear classifier 여러 개를 중간에 nonlinear function과 함께 중첩한 architecture의 경우, 각 layer마다 서로 다른 template을 학습한다는 특징이 있었다. 이를 통해 single linear classifier의 한계점을 보완할 수 있었다.
Convolution layer의 경우 spatial dimension을 그대로 유지한다는 것이 가장 큰 차이점인데, 여기서 각 filter는 서로 다른 역할을 하는 특징 추출기 정도로 이해할 수 있다. 하나의 filter와 convolution 연산을 수행할 때, 모든 input 공간을 탐색하면서 이 filter와 유사도가 높은 부분일수록 activation map에서 더 강조되어 나타날 것이다. filter가 의미하는 바가 모두 다를 것이므로, 서로 다른 activation map들은 서로 다른 특징에 대한 activation 정도를 나타내게 된다. 이러한 과정을 반복하기 때문에, 뒤로 갈수록 high complex feature를 추출하게 되며, 마지막에 이들을 바탕으로 fc layer에서 class를 최종적으로 판단하게 된다.
'Deep Learning > cs231n Lecture' 카테고리의 다른 글
| Lec 6-2. Weight Initialization, Batch Normalization (0) | 2023.03.23 |
|---|---|
| Lec 6-1. Activation Functions, Data Preprocessing (0) | 2023.03.20 |
| Lec 4-2. Introduction to Neural Network (0) | 2023.03.13 |
| Lec 4-1. Gradient with Computational Graph: Forward Path, Backpropagation, Vectorized Operation (0) | 2023.03.09 |
| Lec 3-2. Optimization: Gradient Descent, Stochastic Gradient Descent (0) | 2023.03.06 |



