Optimization: How to find best weight parameters W?
Loss function은 weight parameter들이 training dataset에 대해 얼마나 좋은 성능을 내는가에 대한 측정 지표이다. 그렇다면 좋은 성능을 내도록 weight parameter들을 어떻게 찾아갈 것인가? 이러한 문제를 optimization이라고 한다.
Gradient Descent: Following direction of gradient
Weight parameter는 I*c개이다. (I는 이미지 벡터의 size, c는 label 수일 때) Weight parameter들이 만들어내는 I*c 차원의 벡터 공간을 생각해보면, weight parameter들이 random하게 초기화되어 있는 상태는 벡터 공간 상의 임의의 점에서 출발하는 것으로 볼 수 있다. Loss function은 weight parameter들의 함수이므로, 이 벡터 공간 상에서 정의되어 있는 함수이다. 그리고 이 점에서 loss function의 gradient 벡터를 구하고, 이 방향으로 점을 이동시킨다. gradient 벡터는 그 점에서 함수의 증감이 가장 큰 방향이다. 따라서 만약 초기 상태의 어떠한 점으로부터 시작하여 이 점에서 loss function의 gradient를 구하고 그 방향으로 한 step 이동하고, 다시 이 점에서 gradient 구하는 과정을 반복한다면 loss function의 최소 지점을 찾을 수 있을 것이다.
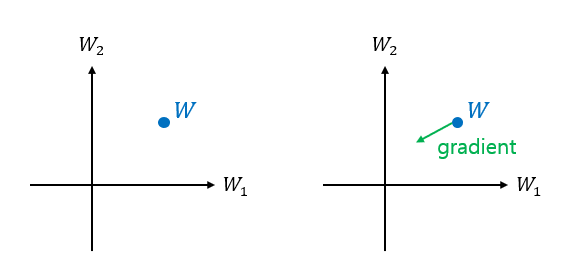
weight W의 dimension은 시각화할 수 없으므로, 단순화시켜서 2차원인 경우를 그림으로 시각화해보면 아래와 같다. 2차원 벡터 공간 상의 어느 지점으로부터 출발한다. (초기화 지점, weight의 초기값) gradient의 정의를 생각해보면, 각 변수의 편미분을 element로 하는 벡터이다. 2차원이므로 loss function이 w1, w2의 2변수 함수이고, gradient 벡터도 2차원 벡터가 된다. gradient 방향을 아래 그림과 같이 표시할 수 있고, 현재 지점인 W에서 가장 함수가 증가율이 큰 방향이다. 우리는 loss function이 최소가 되는 지점을 찾고 싶기 때문에, gradient 방향만큼 빼주면 된다.
Numerical Gradient
그렇다면 다음으로는 고차원인 weight에 대해 gradient를 어떻게 계산할지를 알아야 한다. 먼저, numerical한 방식을 생각할 수 있다. 이는 미분의 근사식으로부터 얻는데, 다음과 같다.
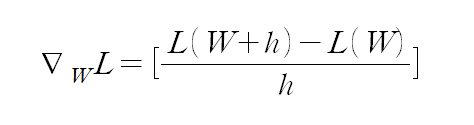
수식을 표현하는 것이 쉽지 않아 우선 이렇게 작성하였다. gradient 벡터는 I*c 차원일텐데, 이 때 i번째 element에 대한 계산식을 표현한 것이다. h는 미소 크기로서, 예를 들어 0.0001과 같은 값이다. 그리고 벡터 W에 h를 더하는 표기가 조금 이상한데, 이것은 W 벡터의 i번째 element에만 h 값(=0.0001)을 더하고 loss function 값을 계산한다는 의미이다.
이러한 numerical gradient는 수식을 표현하기에 편리하지만, 계산하기에 느리고 근사값을 계산한다는 단점이 있다.
Analytical Gradient
analytical 방식은 미분을 이용하는 것이다. Loss function L()은 weight W들의 함수이고, w_i에 대한 편미분을 함수의 형태로 구할 수 있다. 이 함수에 W 값을 넣으면 곧 편미분 값을 얻을 수 있다. 이런 방식으로 gradient 벡터의 각 element 값을 계산할 수 있다.

이제 gradient descent를 다음과 같이 weight 벡터의 형태로 표현할 수 있다. 참고로, weight matrix W는 (c, I)의 차원을 갖는데, 여기서 W라는 notation은 편의상 c*I 차원의 벡터와 혼용하고 있다. 아래의 경우 벡터이다.

Practical Version: Stochastic Gradient Descent
weight parameter를 한 번 업데이트할 때마다 현재 지점에서의 gradient를 계산해야 하는데, 모든 이미지 데이터에 대한 loss function을 고려한다면 계산하는 것이 매우 오래 걸린다. 그래서 보다 practical한 관점에서 mini-batch 단위로 gradient descent를 실행하는데, 이를 stochastic gradient descent라고 한다. loss function의 gradient를 계산할 때 training dataset 전체를 대상으로 하는 것이 아니라 32/64/128개 등 일부를 sampling하여 이 이미지 데이터들에 대해서만 계산하는 것이다.
Summary
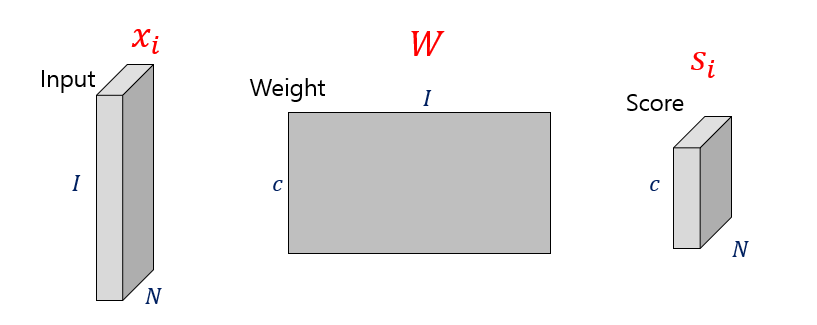
지금까지 한 내용을 그림으로 요약해보자면 위와 같다. Input(=image) training dataset이 N개 있고, weight parameter는 어떠한 초기값으로 initialize되어 있다. 그리고 이들의 곱으로 표현된 score vector도 각 데이터마다 총 N개 계산된다. 각 i번째 input data와 계산된 score를 통해 loss L_i를 계산하고, 이들을 sum한 것이 total loss L이 된다. 이 L을 최소화하도록 하는 W를 찾아나가고, 그 방식으로서 gradient descent를 공부하였다.
이 과정을 계속 반복한 결과로서, 주어진 image dataset에 대한 최적의 parameter들, 곧 linear classifier를 찾을 수 있다.



