Nearest-Neighbor (NN) Classifier
Data driven 방식의 image classifier 중 가장 naive한 approach는 nearest-neighbor classifier이다. 우선 training data를 모두 메모리에 저장해둔 뒤, 판단하고자 하는 test data에 대해 미리 저장된 training data와 모두 비교해 가장 가까운(nearest) label로 분류하는 것이다.
Distance Metric: L1 Distance
'가장 가깝다'는 것을 이미지에 대해 어떻게 적용할 것인지를 판단해야 한다. 하나의 방식은 L1 distance이다. 이것은 (32, 32, 3)의 3차원의 이미지를 (32*32*3, 1)이라는 하나의 긴 벡터라고 생각하고, 비교하고자 하는 두 이미지 벡터 간의 거리를 구하는 것과 같다. 이 때, 두 이미지 벡터 간의 거리를 계산하는 방식은 다음과 같다.
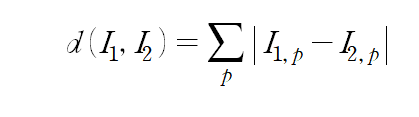
p는 이미지 벡터의 모든 element이다. 각 element의 절댓값 차를 모두 더한 것을 distance로 정의한다.
Is This Classifier Good?
NN classifier는 가장 단순한 classifier인데, 총 N개의 train data가 있을 때 training time은 O(1), test time은 O(N)이다. 이것은 좋지 않은데, 모델을 학습시키는 데에 오래 걸리더라도 테스트 데이터에 대한 판단을 빨리 하는 것이 더 자연스럽고 유리하기 때문이다.
K Nearest-Neighbors (KNN) Classifier
NN Classifier를 보완한 것이 KNN이다. 이는 테스트 데이터에 대해, 가장 가까운 k개의 train 이미지를 구한 뒤 이 중 가장 다수를 차지하는 majority vote 방식으로 분류한다.
Another Distance Metric: L2 Distance
문제에 따라서 여러 가지 distance metric을 사용할 수 있는데, L2 distance도 있다.

이는 각 pixel(=element) 값의 차의 제곱을 모두 더한 뒤, 루트를 취한 것이다.
Hyperparameter
KNN의 경우, k 값과 distance metric을 결정해야 한다. 이처럼, 모델 training을 하기 전에 모델(또는 알고리즘)에 관한 판단을 미리 해야 하는데, 이를 hyperparameter라고 한다. hyperparameter를 적절히 튜닝하는 것도 매우 중요한 문제인데, 이를 위해 dataset split을 한다.
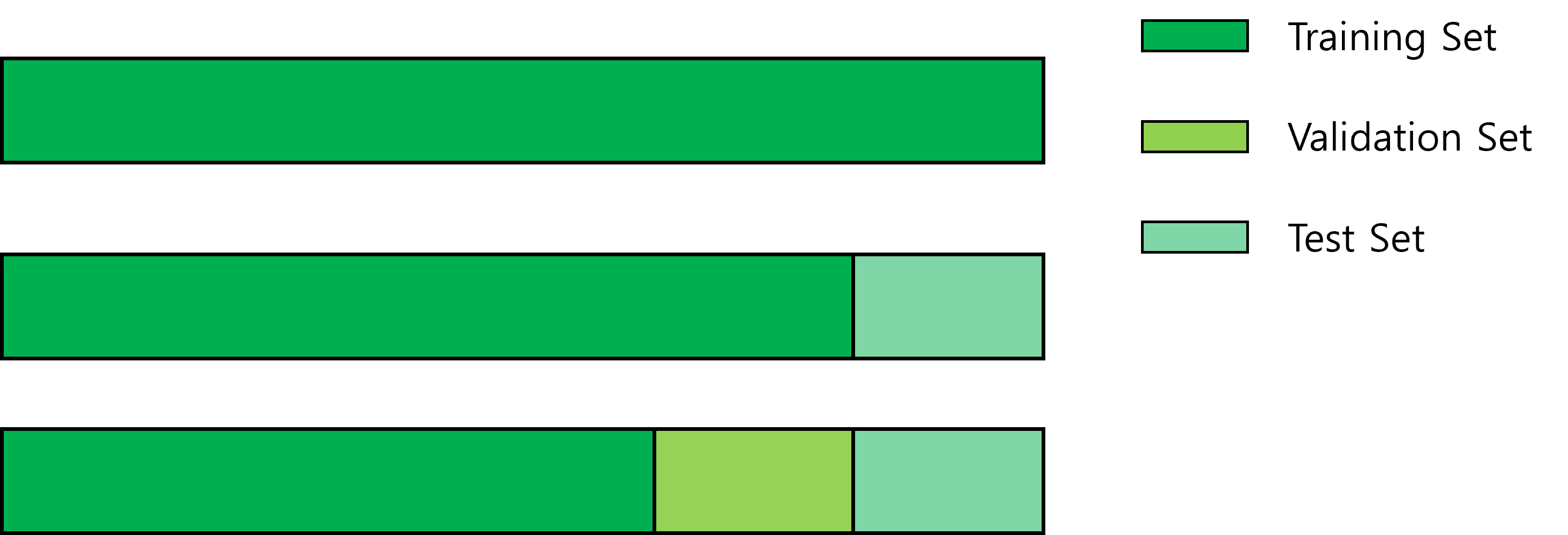
첫 번째는 모두 training set으로 사용하는 것인데, 이는 좋지 않다. 왜냐하면 이 모델은 우리가 가지고 있는 training set에 대해 overfit 될 것이기 때문이다. 두 번째는 test set을 따로 두고, test set에 대해 가장 좋은 성능을 내는 hyperparameter 값을 찾는 것이다. 이 때의 문제는 학습된 모델의 성능을 측정할 수 없다는 것이다. 왜냐하면 test set에 대해 hyperparameter를 튜닝했기 때문이다. 세 번째는 3개의 set으로 나누는 것이다. validation set에 대해 가장 좋은 성능을 내도록 hyperparameter를 튜닝하고, test set은 마지막 모델 성능 평가 시에만 사용한다.
Why Is KNN Not Used?
KNN이 사용되지 않는 이유는 우선 pixel 값의 차이를 바탕으로 하는 distance metric이 이미지 semantic 관점에서 not informative하기 때문이다. 또 하나의 이유로는 dimension의 관점에서 생각해볼 수 있는데, 이미지는 매우 high dimension 벡터이다. 이에 비해 가지고 있는 training data 이미지는 매우 적기 때문에, 이미지 벡터가 span하는 벡터 공간을 dense하게 채울 수 없다.



