Transformer neural network의 구조를 공부하는 데에 아래의 3개 유튜브 영상과 NIPS 17년 논문을 참고하였다. 본 포스팅에서는 이들의 내용을 정리한다.
Youtube 영상 링크
Episode 1: Position Embeddings
https://www.youtube.com/watch?v=dichIcUZfOw
Episode 2: Multi-Head & Self-Attention
https://www.youtube.com/watch?v=mMa2PmYJlCo
Episode 3: Decoder's Masked Attention
https://www.youtube.com/watch?v=gJ9kaJsE78k
Paper
A. Vaswani, Attention is all you need, NIPS 2017

전반적인 transformer 모델 구조는 위 그림과 같다.
1. Position Embeddings
(1) What does transformer model do?
Transformer 모델은 language modeling, machine translation 등의 task에 주로 쓰인다. Video 3개에 걸쳐 등장하는 예시 task는 dialogue completion이다. 예를 들어, 아래 그림의 왼쪽과 같은 dialogue가 input으로 주어지면, 뒤를 이을 만한 가장 자연스러운 dialogue를 output으로 출력하여 완성하는 것이다.
Machine translation도 비슷한 맥락으로 생각하면 될 것이다.
(2) Raw input processing: mapping to index
우선 모델 input으로 주어지는 것을 raw input이라고 하면, 이것은 영단어의 sequence이다. 영어 알파벳을 모델이 직접 학습하기는 어려우므로, 각 단어에 대응되는 index로 mapping 된다. 이는 모델이 하나의 거대한 사전을 가지고 있어서 특정 단어는 고유의 index 숫자로 mapping 되는 식이다. 예를 들어, 'when'은 2458, 'you'는 5670 과 같은 숫자에 mapping 될 수 있다.

(3) Embedding layer
Dictionary에 존재하는 모든 단어에 대해 embedding size인 길이 512의 vector가 대응된다. Vector의 각 element는 저마다의 linguistic feature를 의미하고 있다고 보면 되고, 이를 통해 각 단어는 512 차원의 벡터 공간으로 mapping 된다. 만약 두 단어가 서로 유사한 linguistic context를 더 많이 공유할수록 벡터 공간 상의 거리가 가까울 것이다.
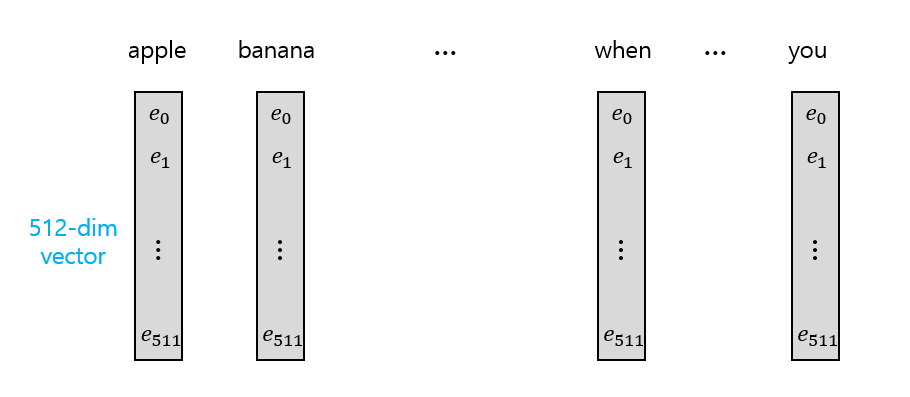

Embedding layer를 거치게 되면 index의 sequence가 (512, sequence_length)의 행렬이 된다. 여기서는 sequence length를 7로 가정하였다. 여기서 각 vector의 element는 처음에 (-1, 1) 사이의 random number이며, training phase를 거치면서 알맞은 값이 결정된다.
(4) Position embedding
LSTM과 같은 recurrent 모델의 단점이 sequential한 처리로 인해 느리다는 것이었는데, transformer는 input들을 한 번에 처리하기 때문에 이와 같은 단점을 해결한다. 하지만, parallel한 처리로 인해 순서 정보를 잃게 되므로, 순서 정보에 대한 처리가 요구된다.
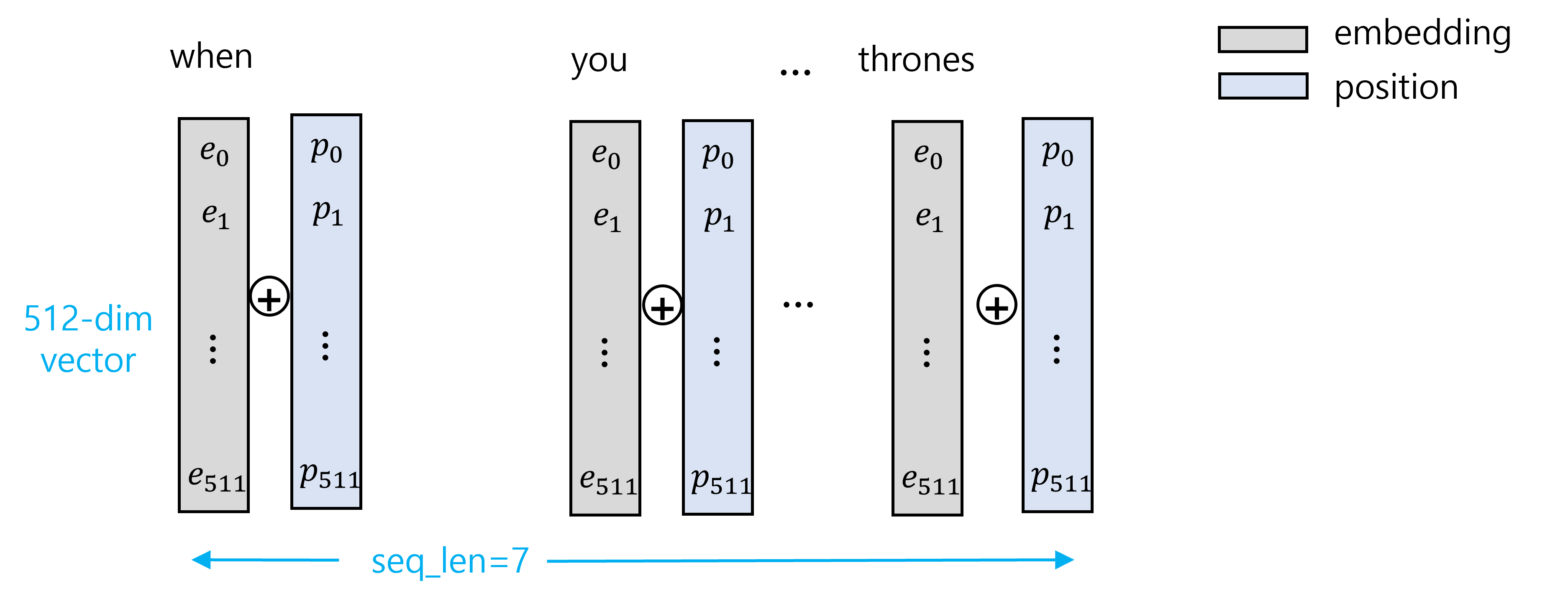
다음과 같이 모든 단어의 embedding vector에 position vector를 더하는 것을 생각할 수 있다. 이 때 position vector의 값을 어떻게 정할 것인지의 문제가 있는데, 단순히 몇 번째인지에 따라 1, 2, 등의 값을 mapping 한다고 생각해보자. 이 경우, position vector의 값이 scale이 너무 커서 embedding 정보를 잃게 된다. 만약 이를 문장 전체의 길이 N으로 나눠 1/N, 2/N, ... 의 값을 mapping 한다고 하면 이 때는 position 정보가 문장 전체의 길이에 의존적이게 된다.
다음과 같이 sin, cos을 통해 이 문제를 해결한다. pos는 1, 2, ...과 같이 문장 내에서 단어의 순서이고, i는 embedding vector의 index이다. sin, cos 함수의 주기성이 있어서 하나의 element만 봤을 때는 position이 달라도 같은 값을 가지게 될 수 있으나, index가 다르면 sin, cos 함수의 주파수가 달라지기 때문에 position이 다르면 vector 전체로 봤을 때는 고유한 vector 값을 갖게 된다.
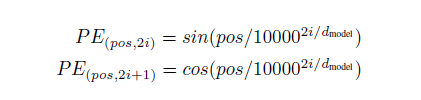
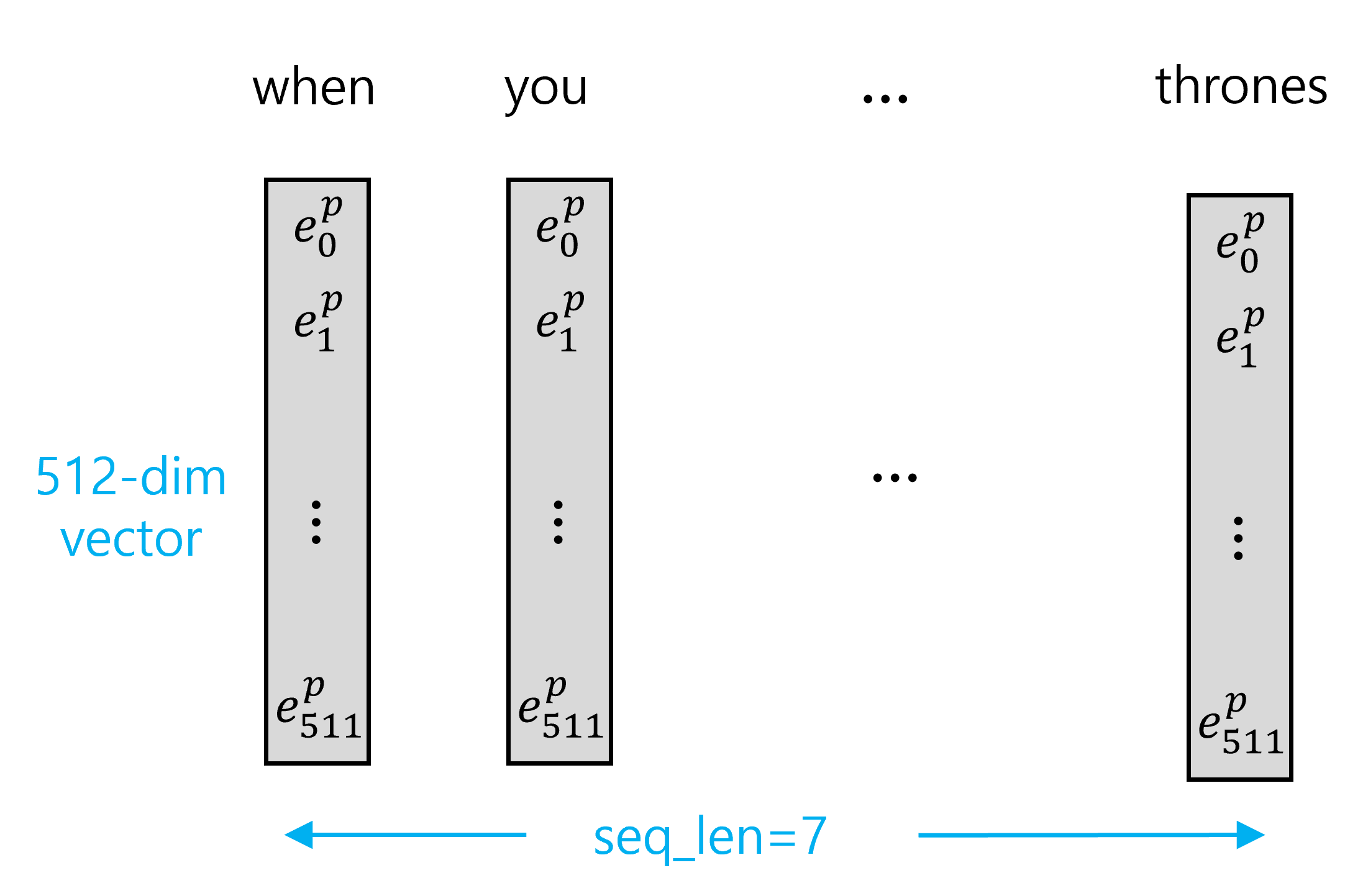
정리해보면 raw input은 word embedding 및 position embedding 되어 encoder에 다음과 같이 (512, 7) 크기의 행렬 형태로 변환되어 들어가게 된다.

2. Multi-Head & Self-Attention
(1) Attention
Simple attention이란 외부의 query에 대한 정답을 결정하는 데에 있어 더 중요하다고 생각되는 단어에 더 많은 focus를 주고자 하는 mechanism이다. Transformer에서는 self-attention을 사용하는데, 이것은 simple attention에 더해 같은 문장 내에 존재하는 단어 간 관계를 모델링하는 것이다.
이제부터는 multi-head attention layer를 구성하는 component에 대해 살펴본다. 전반적인 block diagram은 아래 Figure과 같다.
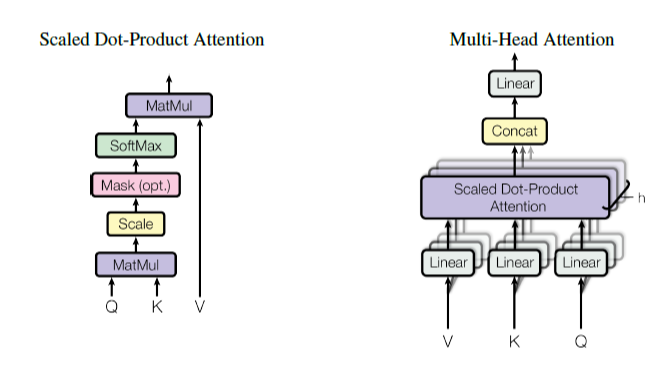
(2) 3 Linear layer & Attention output
Encoder에는 우선 3개의 linear layer가 있는데, 이들을 각각 Q (Query), K (Key), V (Value)로 표기한다. 유튜브 영상 검색을 예로 들면 query는 입력하고자 하는 요청, key는 탐색 대상이 되는 영상 제목들, value는 영상의 content를 의미한다. Linear layer는 input과 output을 mapping 시켜주며, input의 dimension을 바꿔서 output으로 내보낸다.
각 layer 별로 weight parameter matrix W_Q, W_K, W_V가 존재하며, 여기서 W_Q, W_K는 서로 차원이 같다.
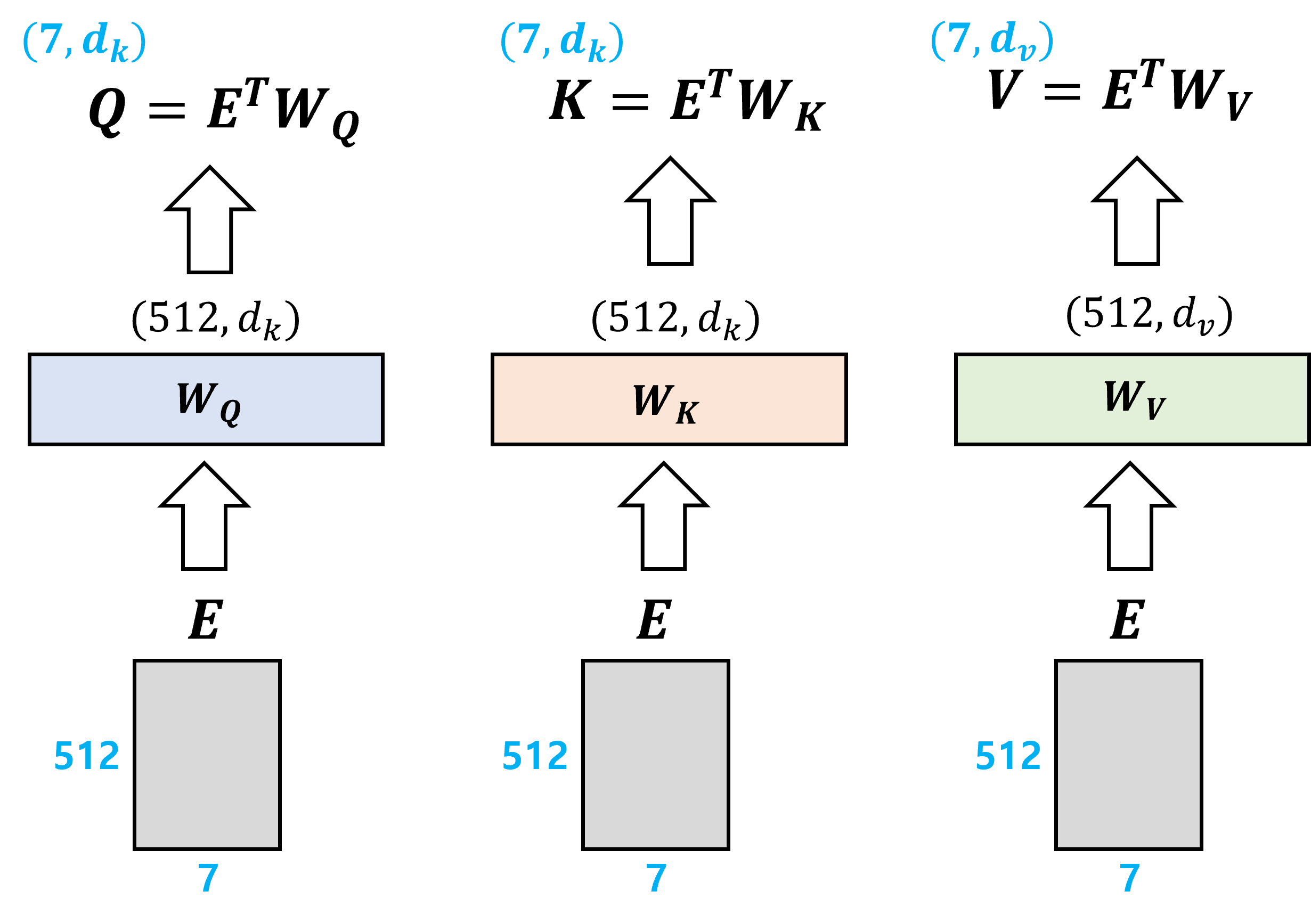
E는 이전에 input이 embedding 된 (512, 7) 크기의 행렬이며, weight matrix와의 행렬 곱을 통해 output이 계산된다.
Q와 K^T의 행렬 곱으로 attention filter가 계산된다. attention filter의 크기는 (7, 7), 일반화하면 (sequence_length, sequence_length) 이다. (i, j) element의 값은 i, j번째 단어 간 관계를 의미하며, 1에 가까울수록 유사도가 높다는 것이다.

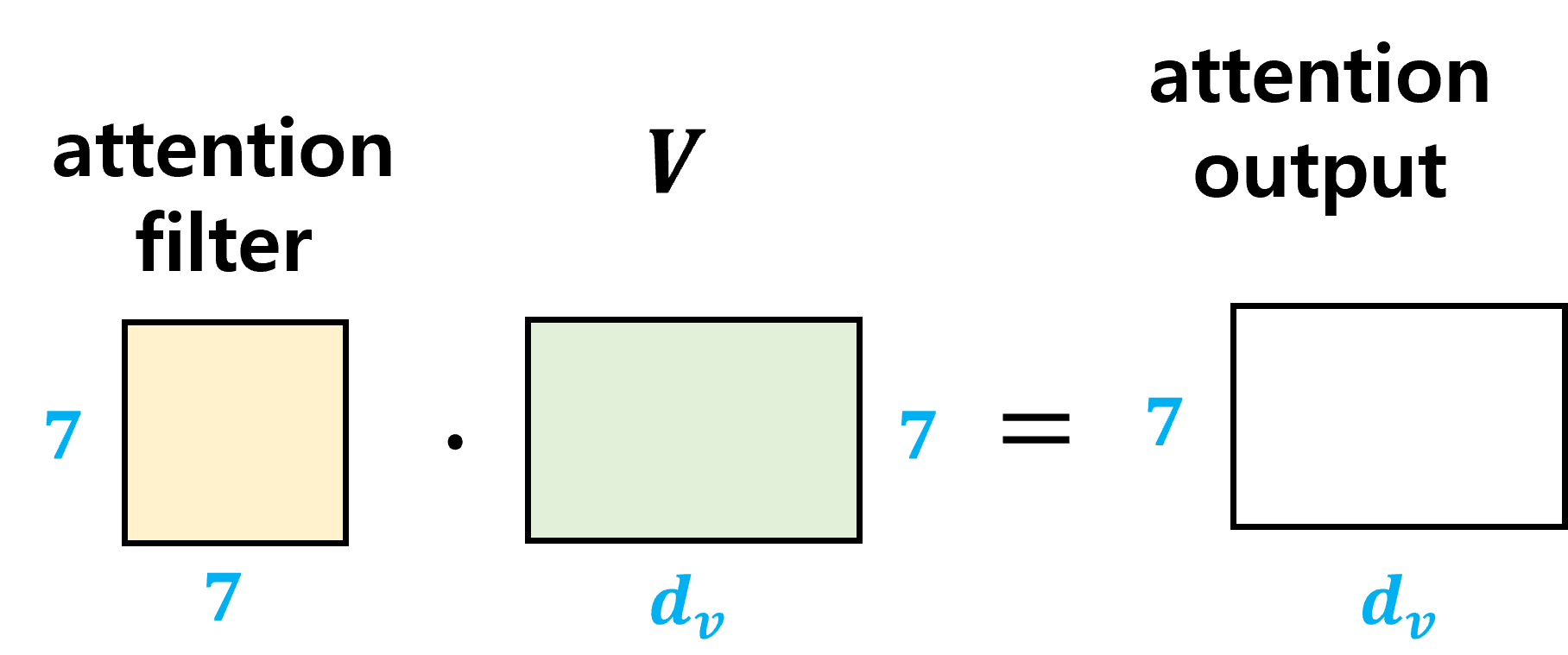
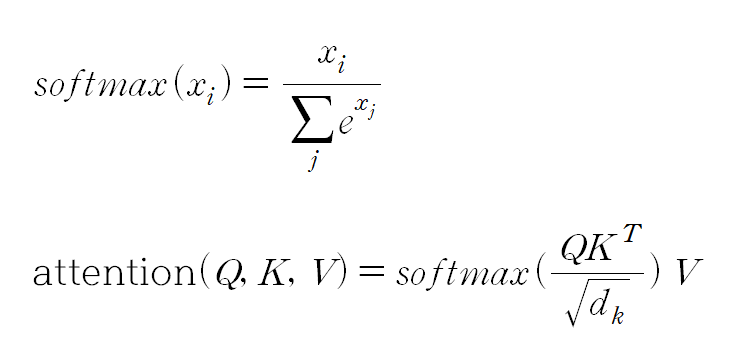
attention filter의 각 행에 대해 softmax를 하여 모든 값을 (0, 1) 범위의 값으로 만들어준다. 그 후에 value matrix와 행렬 곱을 하여 attention output을 만들어낸다. output의 의미는 value matrix를 attention filter에 통과시켜 더 focus 하고자 하는 영역을 filtering 한 것이다.
(3) Multi-head attention
이러한 attention filter 구조를 여러 개 (h개) 둠으로써 training phase에 서로 다른 attention을 학습하도록 한다. 각각의 attention filter의 output이 (7, d_v) 크기의 행렬이므로 총 h개의 (7, d_v) 크기 행렬을 얻게 된다. 마지막에는 이를 하나의 (7, h*d_v) 행렬로 concat. 시킨 뒤 linear filter에 통과시킨다.

Multi-head attention layer의 output은 (7, 512) 크기의 행렬이 된다.
3. Decoder's Masked Attention
(1) Residual connection, Add&Norm layer
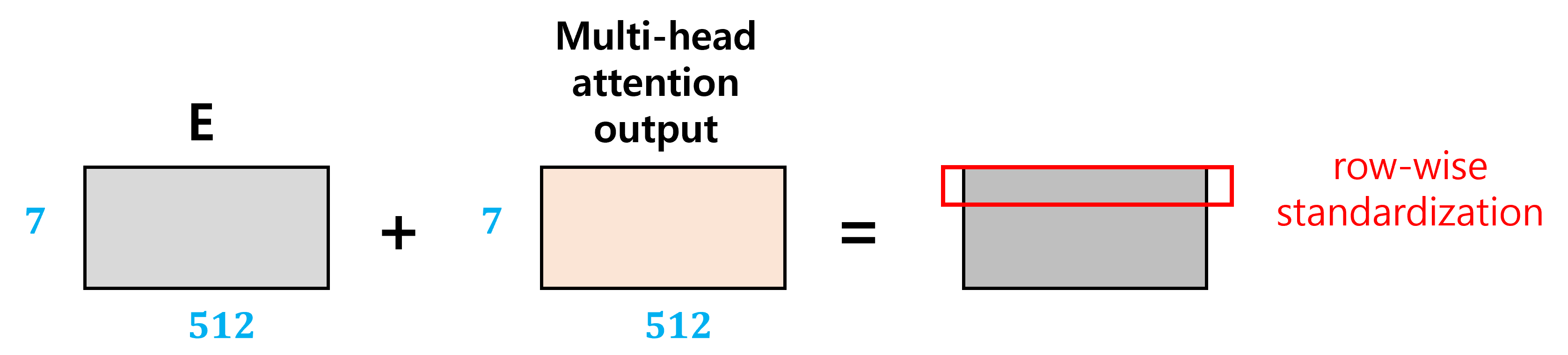
다시 전체적인 구조를 보면 multi-head attention의 output과 encoder의 input이 함께 Add & Norm layer의 input으로 들어간다. Encoder의 input이 layer를 bypassing 하여 바로 Add & Norm layer로 넘어간 것인데, 이는 knowledge preservation 이다. 계속 linear layer를 통과시키면서 old information이 없어지는 것을 방지하기 위함이다.
따라서 아래 그림과 같이 encoder의 input, 즉 모델의 input이 embedding 된 matrix E와 multi-head attention layer의 output을 더한 뒤, 이를 normalization 한다. Normalization이란 각 행에 대해 평균, 표준편차를 구해 평균을 빼고 표준편차로 나누어주는 것이다.
Encoder의 다음 부분은 feed forward라고 되어 있는데, 이것은 여러 개의 linear layer, ReLU layer 등으로 이루어져 있다.
(2) Decoder: Generating text sequence as output
Encoder은 input text sequence를 받아서 이를 (sequence_length, 512) 크기의 행렬로 변환시킨다. Decoder은 다시 output text sequence를 만들어내는데, input으로는 encoder의 output과 이전에 decoder가 만들어냈던 output, 이렇게 2가지를 받는다.
Decoder의 multi-head attention layer의 input 3가지 Q, K, V를 보면, 여기서 Q와 K는 encoder의 output이다. V는 masked multi-head attention layer로부터 오는데, 이것은 이전에 decoder의 output과 관련이 있는 것이다. Masked multi-head attention layer는 뒤에서 조금 더 설명하기로 한다.
그 다음에 이어서 오는 feed forward 등은 encoder에서와 동일하다.
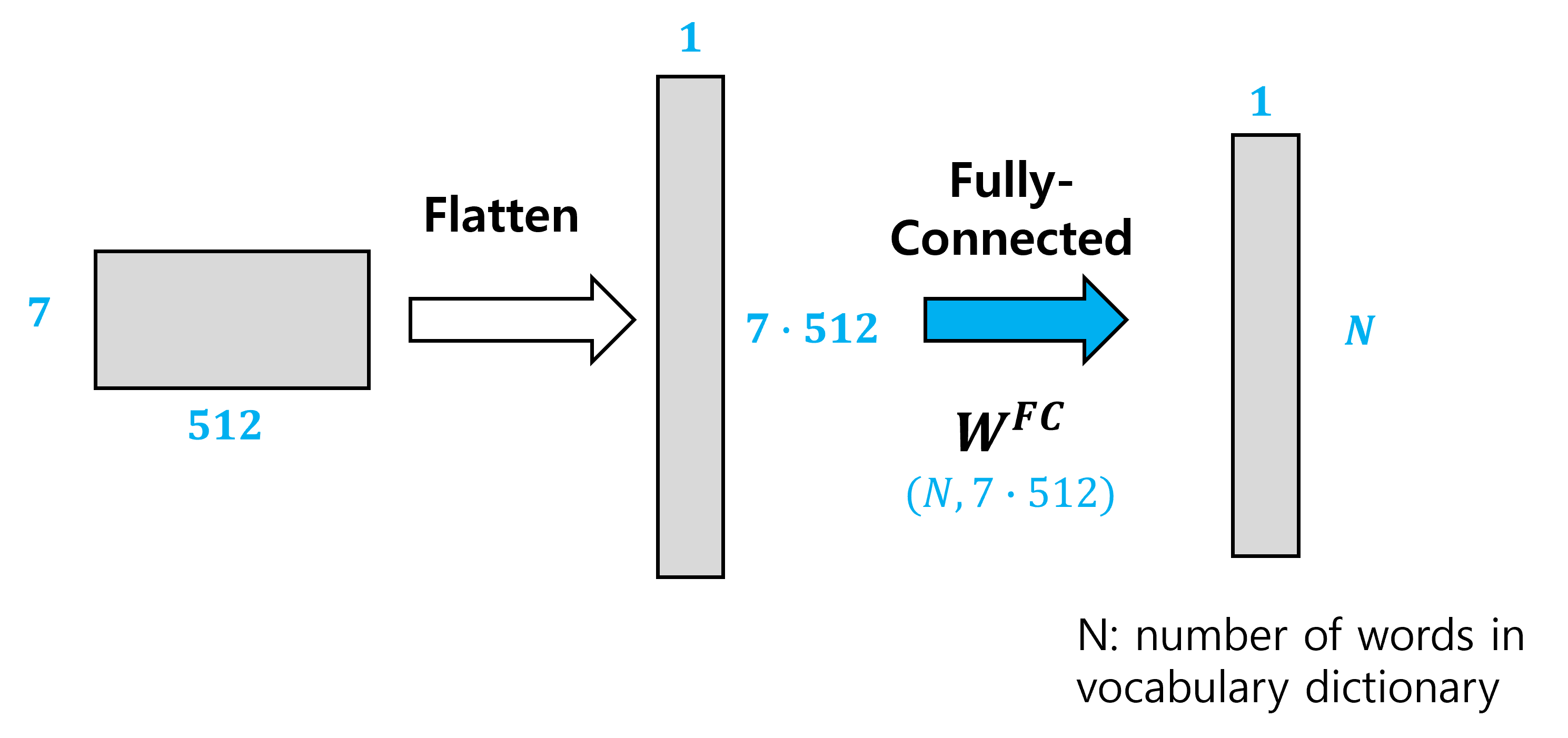
맨 마지막에 output text가 출력되는 형태는 vocabulary dictionary의 모든 단어의 확률을 값으로 하는 vector 이다. 여기서는 그 크기를 N이라고 한다. 따라서 먼저 (7, 512) 행렬을 flatten 시키고, 이것을 fully connected layer에 통과시켜 확률을 얻게 된다. 확률이 가장 높은 단어를 output으로 출력하게 된다.
Image classification에서 여러 class에 대한 확률 vector를 마지막에 얻고, 가장 높은 확률을 갖는 class로 예측하는 것과 유사하다.
(3) Decoder: Masked multi-head attention
Inference time에는 input만 주어지고 어떤 output이 적절한지가 주어지지 않지만, training phase에는 input과 함께 학습해야 하는 완전한 dialogue가 주어진다. 이 때 completed dialogue에 대해서는 masking을 취하는데, 이것은 비유적으로 이해하자면 정답을 미리 보지 않고 학습을 하게 하는 것이다. 우선 output 정답을 보지 않고 모델이 prediction을 한 뒤에 completed dialogue와 비교하여 피드백 (back propagation을 통한 parameter update)을 주는 것이다. 그리고 다음 단어를 prediction 할 때에는 이전 단어에 대해서는 complete dialogue로부터 올바른 단어를 decoder에 넣어준다.
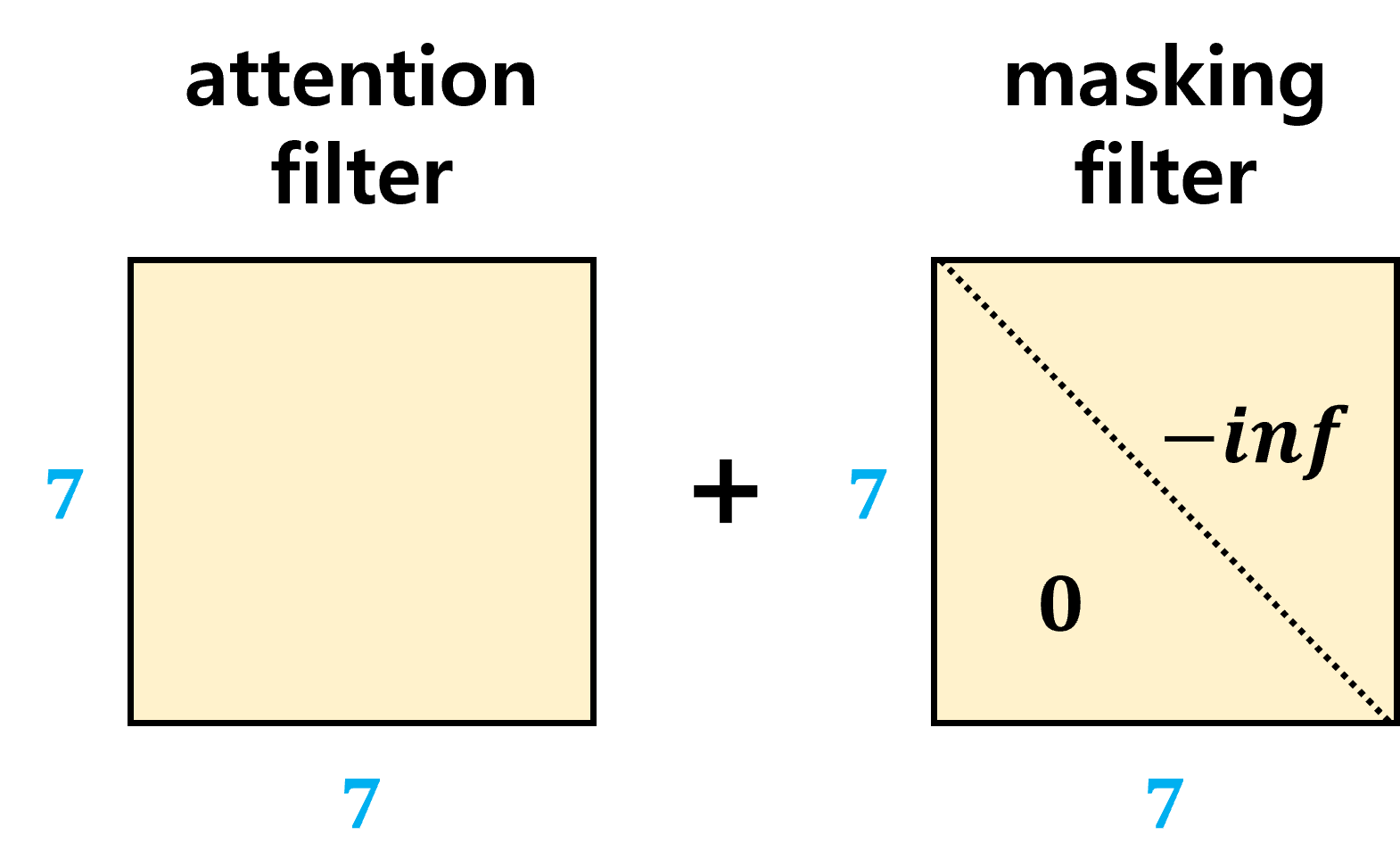
Masking operation을 살펴보면 attention filter에 0을 더하거나 -inf를 더하는 것이다. Attention filter는 두 단어 i, j 간의 관계 (유사도)를 의미하는데, 이 때 단어 i보다 이후에 등장한 단어 j를 가지고 예측을 하는 것을 방지하기 위해 이러한 element의 값은 모두 -inf 로 만들어주는 것이다. 간단히 요약하면 future word에 대해 -inf를 더해주어 masking 한다. 이렇게 함으로써 future word에 대해서는 zero attention을 줄 수 있다.
맨 첫 time step에는 decoder의 output이 아무 것도 없는데, <start>라는 special token을 사용한다. 그리고 output은 <end>라는 special token을 출력할 때까지 반복한다.