5.1 Basic Concepts
Single core 시스템에서 어떤 시점에 실행될 수 있는 프로세스의 수는 최대 1개이다. 여기서 multiprogramming의 목표는 항상 어떤 프로세스가 CPU에서 실행되도록 함으로써, CPU utilization을 최대화하는 것이다. Multiprogramming이란 실행이 완료되지 않은 프로세스 2개 이상이 메모리에 올라와있는 것을 말한다. 하나의 프로세스는 I/O request와 같이 wait 해야 하는 상황이 되기 전까지 실행될텐데, wait 해야 하는 상황을 만나면 CPU가 idle 상태에 놓이게 된다. 이 때, OS가 해당 프로세스로부터 CPU 제어권을 가져와서 다른 프로세스에게 할당해주고, 이런 방식이 반복되며 여러 프로세스들이 번갈아 실행되는 것이다. OS의 이러한 기능을 scheduling이라고 하며, CPU 외에도 여러 컴퓨터 시스템 자원이 있으나, 여기서는 CPU time 이라는 자원에 초점을 맞추어 scheduling을 살펴보기로 한다.
5.1.1 CPU-I/O Burst Cycle
하나의 프로세스의 실행에서 CPU burst와 I/O burst cycle이 번갈아 나타나게 된다. 프로세스의 실행은 CPU burst로 시작하며, 종료될 때도 termination에 대한 system call을 하므로 CPU burst로 끝난다. 이에 대한 그림은 Figure 5.1에 나타나 있다.
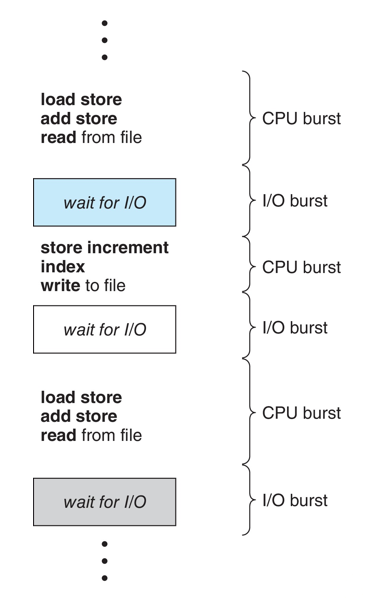
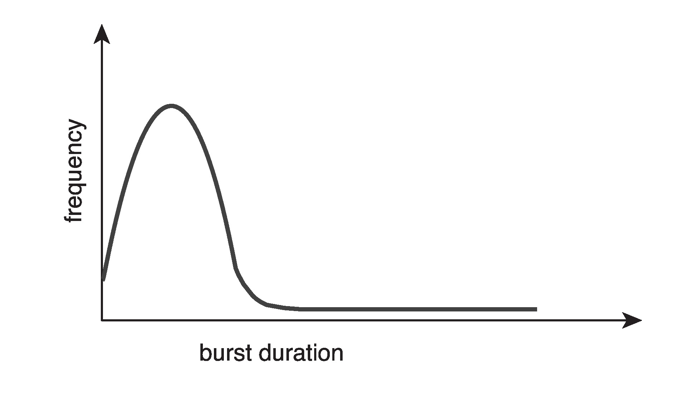
CPU burst의 duration에 대한 정보는 중요한데, 이것이 CPU scheduling 알고리즘을 구현하는 데에 있어서 중요하게 작용하기 때문이다. 이것은 물론 application과 컴퓨터 시스템에 따라 다르게 나타나지만, 대략적으로 Figure 5.2와 같은 curve를 그리는 것으로 알려져 있다. I/O bound 프로그램은 short CPU burst가 자주 나타나고, CPU bound 프로그램은 long CPU burst가 조금 나타날 것이다.
5.1.2 CPU Scheduler
CPU가 idle 상태에 놓이면, OS는 ready queue에 있는 프로세스 중 다음에 실행할 것을 하나 선택한다. OS 중 이러한 기능을 하는 것을 CPU scheduler라고 한다. 이 때 ready queue는 항상 FIFO(First In First Out) 구조는 아니며, 이것은 CPU scheduling 알고리즘에 따라 달라진다. Queue를 이루는 item들은 각 프로세스에 대한 PCB(Process Control Block)이다.
5.1.3 Preemptive and Nonpreemptive Scheduling
CPU scheduling이 실행되는 상황은 다음 4가지로 나눌 수 있다.
첫째, 어떤 프로세스가 running->waiting 상태로 전환되는 경우. 이것은 프로세스 내에서 I/O request, wait() 등의 system call을 하여 os에게 control을 넘겨줄 때 일어난다.
둘째, 어떤 프로세스가 running->ready 상태로 전환되는 경우. 이것은 프로세스가 외부의 HW 인터럽트에 의해 ready 상태로 전환되는 것이다.
셋째, I/O request의 완료 등으로 프로세스가 waiting->ready로 전환되는 경우.
넷째, 프로세스가 종료되는 경우.
여기서 첫째와 넷째의 경우는 무조건 scheduling이 실행되어야 한다. 더 이상 running 상태에 있던 user process가 실행을 이어갈 수 없기 때문이다. 그러나 둘째와 셋째의 경우 scheduling 여부에 대한 선택지가 생긴다. 여기서 첫째와 넷째 경우만 scheduling이 일어나는 것을 nonpreemtive/cooperative라고 하며, 그렇지 않은 경우를 preemptive라고 한다. Nonpreemtive의 경우, 한 번 프로세스에게 CPU가 할당되면 프로세스가 종료되거나 system call을 하여 waiting 상태로 스스로 전환되기 전까지는 CPU를 계속 차지하여 실행된다. 따라서 nonpreemptive는 real-time computing에는 적절하지 않은데, 왜냐하면 주어진 time frame 안에 task를 완료하는 것이 요구되는 상황에서 os가 개입할 수 없기 때문이다. 현대의 os는 대부분 fully preemptive하게 schedule한다.
5.1.4 Dispatcher
CPU scheduling을 담당하는 또 하나의 모듈로 dispatcher가 있다. 이것은 CPU scheduler가 선택한 프로세스에게 실제로 CPU에 대한 control을 넘겨주는 역할을 한다. 이전에 실행 중이었던 프로세스의 context를 저장하고 새로 실행할 context를 메모리에서 불러와 레지스터에 저장하는 context switch를 하고, 다시 user mode로 mode bit을 바꿔주며, PC 값을 새로 실행할 프로세스의 다음 주소(이것 역시 스택에 저장되어 있을 것이다)로 바꿔서 실행을 이어나갈 수 있도록 한다.
Dispatcher가 돌아가는 데 걸리는 시간을 dispatch latency라고 한다.

5.2 Scheduling Criteria
CPU scheduling 알고리즘들은 서로 다른 특성을 갖는데, 이들을 비교하는 데에 쓰이는 몇 가지 기준은 다음과 같다.
1) CPU utilization: CPU를 계속 busy 상태에 놓이게 해야 한다. CPU utilization 퍼센트를 최대화하는 것이 좋다.
2) Throughput: 단위 시간 당 처리 완료한 프로세스의 수
3) Turnaround time: 특정 프로세스의 관점에서 실행하는 데에 걸리는 시간. 이것은 CPU에서 실제로 실행되는 것 뿐만 아니라 처음 프로세스가 만들어진 순간부터 ready queue에 있고, I/O를 하는 것까지 포함한다.
4) Waiting time: CPU scheduling 알고리즘은 CPU에서 실행되는 시간이나 I/O를 하는 시간과는 상관이 없다. Ready queue에서 대기하는 시간이 달라질텐데, 이것을 의미한다.
5) Response time: 요청이 처음 들어왔을 때부터 첫 번째 응답이 만들어질 때까지 걸리는 시간을 말한다. 이것은 응답 완료 시간이 아니라 응답을 시작한 순간을 기준으로 한다.
5.3 Scheduling Algorithms
CPU scheduling은 ready queue에 있는 프로세스 중 어느 것에 CPU core를 할당할지를 결정하는 문제이며, 현대의 컴퓨터 시스템은 대부분 multi-core이지만 여기서는 single-core (한 번에 최대 1개의 프로세스만 실행될 수 있는 상황) 시스템을 가정하고 논의한다.
5.3.1 First-Come, First-Served Scheduling
Ready queue에 들어온 순서대로 CPU core를 할당한다. 이것은 FIFO queue에 의해 간단히 구현될 수 있다. 코드의 작성과 이해가 쉽다는 특성이 있지만, average waiting time이 길다는 단점이 있다.

위와 같은 예시에서, 만약 P1->P2->P3 순서로 처리되었다면, 가장 burst time이 긴 P1이 먼저 처리되기 때문에 P2, P3은 오래 기다리게 된다. 그런데 만약 P2->P3->P1 순서로 처리되었다면 average waiting time이 매우 줄어들 것이다. 이처럼, FCFS policy는 average waiting time이 최소가 되지는 않으며, 각 프로세스 간 burst time 간 차이가 크다면 average waiting time의 변화 폭도 크게 된다.
위 예시에서처럼 burst time이 긴 프로세스(CPU-bound 프로세스)가 먼저 CPU를 점유하고 있다면 그보다 burst time이 짧은 여러 프로세스(I/O-bound 프로세스)들이 ready queue에 오래 대기하게 되는데, 이러한 상황을 convoy effect라고 한다. 또한 FCFS policy는 non-preemptive한 scheduling인데, 한 번 프로세스에 CPU가 할당되면 이 프로세스가 종료되거나 I/O 요청을 보내기 전까지는 실행을 계속하게 된다. 따라서, 일정한 간격으로 CPU를 나누어 사용해야 하는 interactive system에서는 사용하기 어렵다.
5.3.2 Shortest-Job-First Scheduling
SJF policy는 각 프로세스의 next CPU burst time의 길이를 비교하여 가장 짧은 프로세스부터 scheduling한다. 따라서 average waiting time을 가장 최소로 보장할 수 있는 방법인데, 근본적으로 CPU scheduling 시 next CPU burst time을 정확하게 알 수는 없다는 한계가 존재한다. 일반적으로는 이전 여러 개의 CPU burst time들의 exponential average를 통해 예측하게 된다.

SJF 알고리즘은 preemtive, non-preemptive 두 가지 모두 가능하다. 하나의 프로세스가 실행 중일 때 다른 프로세스가 ready queue에 새롭게 도착한 상황에서 선택을 하게 된다. 만약 새로 도착한 프로세스의 next CPU burst time이 현재 실행 중인 프로세스의 남은 CPU burst time보다 짧다면, preemtive 방식의 경우 실행 중인 프로세스를 대체하여 새로 도착한 프로세스를 scheduling 한다. 반면, non-preemptive 방식은 일단 돌던 프로세스는 계속 실행한 뒤 scheduling 한다.
5.3.3 Round-Robin Scheduling
RR은 FCFS 알고리즘과 유사하나, 시스템이 프로세스에 대한 preemption을 할 수 있다는 점에서 다르다. 여기서는 time slice라는 시간 단위가 설정되며, scheduler는 ready queue에 있는 프로세스에게 time slice 만큼 CPU 시간을 할당한다. 이 때 ready queue는 circular queue로 구현될 수 있다.
이 때 만약 프로세스의 CPU burst time이 time slice보다 작다면 자발적으로 CPU를 반납할 것이고, scheduler는 ready queue에 있던 다음 프로세스에게 CPU를 할당한다. 만약 그렇지 않고 time slice가 다 지났는데 계속 실행 중이라면 timer interrupt에 의해 OS로 control이 넘어가고 다음 scheduling을 하게 된다.
RR scheduling의 performance는 time slice 크기의 결정에 따라 다른데, 만약 극단적으로 time slice가 매우 크다고 생각해보자. 그러면 이것은 FCFS와 같게 된다. 반대로 매우 작다면 context switch가 매우 자주 일어나서 이로 인한 overhead가 커지게 될 것이다. 이처럼 time slice 크기에 따른 trade-off 관계가 존재한다.
5.3.6 Multilevel Feedback Queue Scheduling
이 scheduling policy는 각 프로세스들을 CPU burst time에 따라 여러 개의 큐 중 하나에 배정하는데, 상황에 따라 프로세스의 큐 간 이동을 허락한다. 만약 CPU burst time이 길다면 낮은 우선순위의 큐에, 짧은 것은 높은 우선순위의 큐에 담게 된다. 우선순위가 높을수록 할당되는 time slice가 작고, 우선순위가 낮을수록 더 긴 시간을 할당받는다.
Scheduler는 먼저 우선순위가 가장 높은 queue 0에 들어있는 프로세스부터 실행시키고, queue 0이 비어있을 때 비로소 queue 1에 있는 프로세스가 실행된다. 만약 queue 1의 프로세스가 실행 중이더라도, 만약 queue 0에 새로운 프로세스가 들어온다면 이 프로세스에 의해 preemption 당하게 된다.
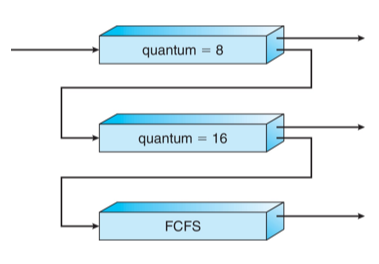
이렇듯 각 프로세스는 우선순위에 따라 할당된 time slice만큼 실행되는데, 만약 주어진 time slice 안에 CPU burst time이 끝나지 않으면 이후에 더 낮은 우선순위, 더 긴 time slice의 큐로 이동하게 된다. 이런 식으로 feedback이 일어나면서 각 프로세스가 가장 적절한 큐로 이동하게 된다.
Reference
A. Silberschatz, Operating System Concepts 10th ed, WILEY (2019) Ch 5
'Operating System' 카테고리의 다른 글
| [Ch 6] Synchronization: Critical Section Problem, Mutex Lock, Semaphore (0) | 2023.06.26 |
|---|---|
| [Ch 4] Thread: Benefits of Multithreading, <pthread> library (0) | 2023.06.08 |
| [Ch 3-2] Process creation, termination (0) | 2023.05.29 |
| [Ch 3-1] Process: Concepts, Process Control Block, Context Switch (0) | 2023.05.25 |
| [Ch 1] Introduction to Operating System (0) | 2023.05.22 |



