Matrix Multiplication
Matrix multiplication(이하 MM)은 3중 for loop으로 구현 가능하다. 사람이 일반적으로 이해하기에 가장 직관적인 연산 순서는 하나의 output element 씩 계산하고, output element를 row->column 순으로 반복하는 방식이다. 이를 pseudocode로 나타내면 아래와 같다.
void MM(int** A, int** B, int** C){
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
for (int k = 0; k < N; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
Consider all permutation of computing dimensions
이 때, i, j, k의 dimension의 연산 순서는 총 6가지의 경우의 수가 있다. 이들을 서로 각기 다른 locality를 갖기 때문에, 실행 속도가 다르게 나타날 것임을 예상해볼 수 있다. 먼저, 이들의 코드는 아래와 같다.
void matmult(int** A, int** B, int** C, int n, int mode) {
switch(mode) {
case 1:
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
int sum = 0;
for (int k = 0; k < n; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
break;
case 2:
for (int j = 0; j < n; j++) {
for (int i = 0; i < n; i++) {
int sum = 0;
for (int k = 0; k < n; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
break;
case 3:
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
int temp = B[k][j];
for (int i = 0; i < n; i++) {
C[i][j] += A[i][k] * temp;
}
}
}
break;
case 4:
for (int k = 0; k < n; k++) {
for (int j = 0; j < n; j++) {
int temp = B[k][j];
for (int i = 0; i < n; i++) {
C[i][j] += A[i][k] * temp;
}
}
}
break;
case 5:
for (int i = 0; i < n; i++) {
for (int k = 0; k < n; k++) {
int temp = A[i][k];
for (int j = 0; j < n; j++) {
C[i][j] += B[k][j] * temp;
}
}
}
break;
case 6:
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
int temp = A[i][k];
for (int j = 0; j < n; j++) {
C[i][j] += B[k][j] * temp;
}
}
}
break;
default:
break;
}
return;
}하나의 함수 내에서 mode 값에 따라 다른 방식으로 연산하도록 작성하였다.
단, 이 때 최대한 locality를 활용할 수 있도록 했는데, inner loop 내에서 반복적으로 참조하는 값은 loop 내에서 local 변수로 선언하였다. 예를 들어, 1, 2번 방식의 경우 output element C[i][j]를 반복적으로 접근하므로 이를 local 변수로 선언해서 연산을 한 뒤, inner loop을 빠져나온 뒤 한 번만 store 연산을 하도록 하는 것이다.
Inner Loop Analysis
이제 이 6개의 방식들이 각각 MM 연산에 대해 어떤 locality를 갖는지를 분석할텐데, inner loop에 초점을 맞추어 분석한다. 이들이 연산을 하는 순서를 그림으로 표현해보면 다음과 같다. 왼쪽 두 정사각형이 곱셈의 대상이 되는 A, B 행렬, 오른쪽 정사각형이 곱셈 결과 행렬 C이다.
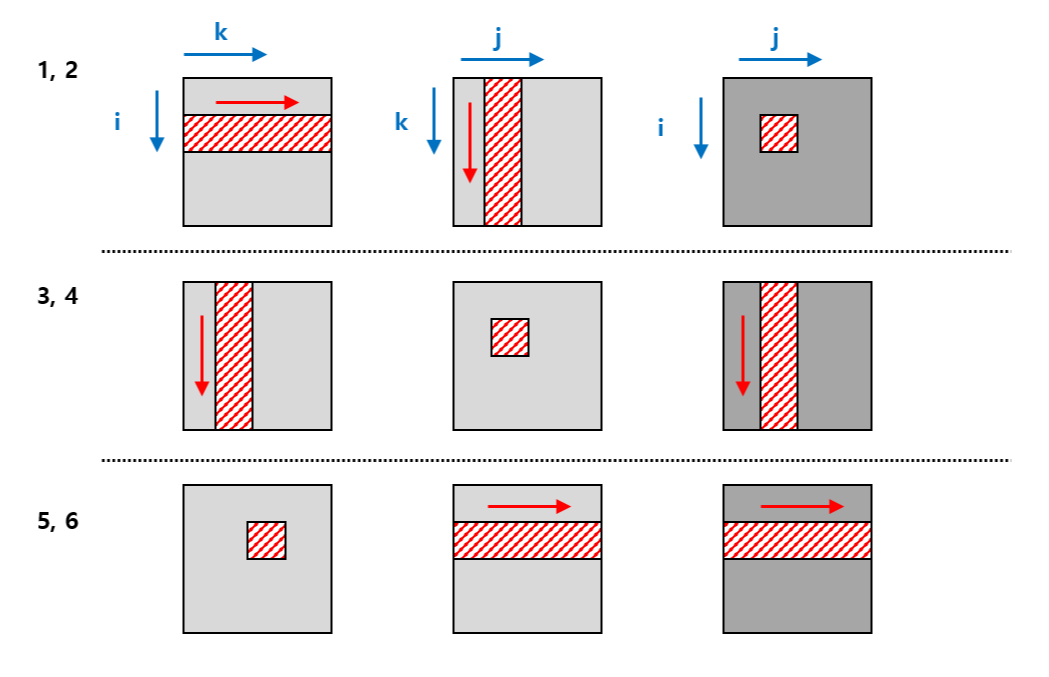
먼저 1, 2번 방식을 보면 매 inner loop iteration마다 2번의 load와 0번의 store 연산을 한다. 왜냐하면 output element에 대해서는 같은 곳을 참조하므로 local 변수를 통해 store 연산 없이 바로 연산을 할 수 있기 때문이다. 접근하는 locality 측면에서 보면 C는 local 변수로 선언해서 처리하므로 제외하고, A, B 중 A에 대해서만 locality를 이용한다. 왜냐하면 A는 row-wise 접근, B는 column-wise 접근이기 때문이다.
마찬가지 방식으로 3, 4번 방식도 분석해볼 수 있다. 2번의 load와 1번의 store 연산을 한다. C, A를 load하여 C에 store한다. locality 측면에서는 모두 column-wise이므로 활용하지 못한다.
5, 6번 방식은 2번의 load와 1번의 store 연산을 한다. 이 때 여기서 흥미로운 점 중 하나는 B, C에 대해 모두 row-wise 접근을 함으로써 locality를 활용할 수 있다는 점이다.
메모리 load/store 연산 횟수에서도 차이가 있고, memory hierarchy를 활용하는 locality 측면에서도 차이가 있다. 우선, 먼저 생각해볼 수 있는 것은 3, 4번 방식은 두 측면에서 모두 성능이 안 좋을 것이다. 왜냐하면 메모리 연산도 많고, locality 활용도 가장 낮기 때문이다. 반면, 1, 2번과 5, 6번은 trade-off가 있는데, 메모리 연산을 좀 더 많이 하지만 memory hierarchy 측면에서 miss로 인한 penalty가 줄어들어 연산 속도가 개선될 수 있기 때문이다.
Experiment & Result
이제, 이를 matrix size를 달리 하며 실행 속도를 측정해본다. 반복 횟수는 10번씩 하여 평균 값을 낸다. 코드는 아래와 같다.
#include <stdio.h>
#include <stdlib.h> // atoi()
#include <time.h> // clock()
int main(int argc, char* argv[]) {
int ARR_SIZE;
int it_cnt;
ARR_SIZE = atoi(argv[1]);
it_cnt = atoi(argv[2]);
clock_t c1, c2;
time_t t1, t2;
t1 = time(NULL);
double t[6];
for (int i = 0; i < 6; i++) {
t[i] = 0;
}
// dynamically allocate 2D array A, B, C using malloc()
int** A;
int** B;
int** C;
A = (int**)malloc(ARR_SIZE * sizeof(int*));
B = (int**)malloc(ARR_SIZE * sizeof(int*));
C = (int**)malloc(ARR_SIZE * sizeof(int*));
for (int i = 0; i < ARR_SIZE; i++) {
A[i] = (int*)malloc(ARR_SIZE * sizeof(int));
B[i] = (int*)malloc(ARR_SIZE * sizeof(int));
C[i] = (int*)malloc(ARR_SIZE * sizeof(int));
}
// Initialize matrix A, B, C
for (int i = 0; i < ARR_SIZE; i++) {
for (int j = 0; j < ARR_SIZE; j++) {
A[i][j] = 1;
B[i][j] = 1;
C[i][j] = 0;
}
}
for (int i = 0; i < it_cnt; i++) {
for (int j = 0; j < 6; j++) {
c1 = clock();
matmult(A, B, C, ARR_SIZE, j+1);
c2 = clock();
t[j] += c2 - c1;
}
}
t2 = time(NULL);
printf("-------------------------------\n");
printf("-- Experiment with matrix size %d\n", ARR_SIZE);
for (int i = 0; i < 6; i++) {
printf("Matmul %d: %.2f cycles\n", i+1, t[i]/it_cnt);
}
printf("-- Total time: %ld sec.\n", t2 - t1);
// memory deallocation
for (int i = 0; i < ARR_SIZE; i++) {
free(A[i]);
free(B[i]);
free(C[i]);
}
free(A);
free(B);
free(C);
}이 때, matrix size와 실험의 반복 횟수는 프로그램의 argument로 받아서 처리하도록 하였다.
gcc compile optimization level
여러 번 실험을 반복하면서 얻은 관찰 중 하나는 gcc 컴파일을 할 때 optimization level을 다르게 설정함에 따라 연산 속도의 차이가 더 커진다는 것이다.
먼저, optimization 0으로 하였을 때의 결과는 다음과 같다.
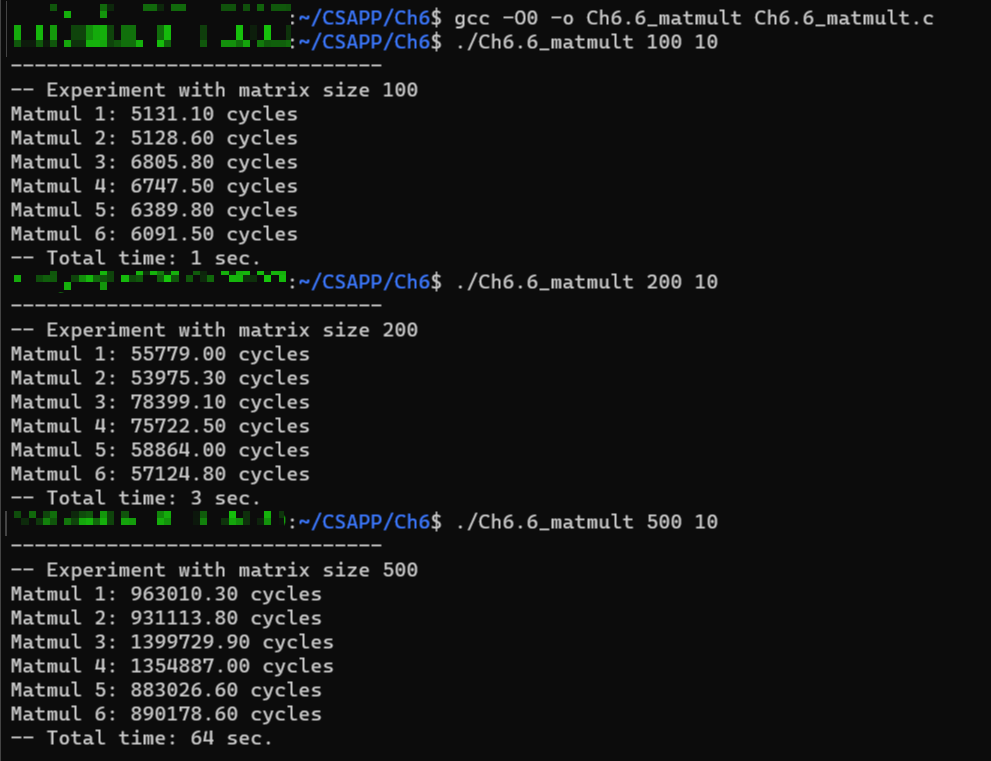
우선 3, 4번 방식이 성능 측면에서 가장 안 좋은 것은 공통적이었고, 연산 행렬 크기가 커짐에 따라 5, 6번 방식이 더 성능이 좋은 것을 확인하였다. 이는 행렬 크기가 작을 때는 상대적으로 memory hierarchy의 상위 계층에 연산 데이터의 대부분을 저장할 수 있어서 miss로 인한 penalty보다는 추가적인 메모리 연산으로 인한 overhead가 더 큰 영향을 미쳤을 것으로 분석할 수 있다. 그러나, 행렬 크기가 커지면 memory hierarchy의 낮은 계층에도 연산 데이터가 저장되게 되어서 miss로 인한 penalty가 더 큰 영향을 주게 되어서, locality를 가장 잘 활용하는 5, 6번 방식이 성능을 더 좋게 낸 것이다.
이제 optimization level을 바꾸어 실험을 반복해보았다.
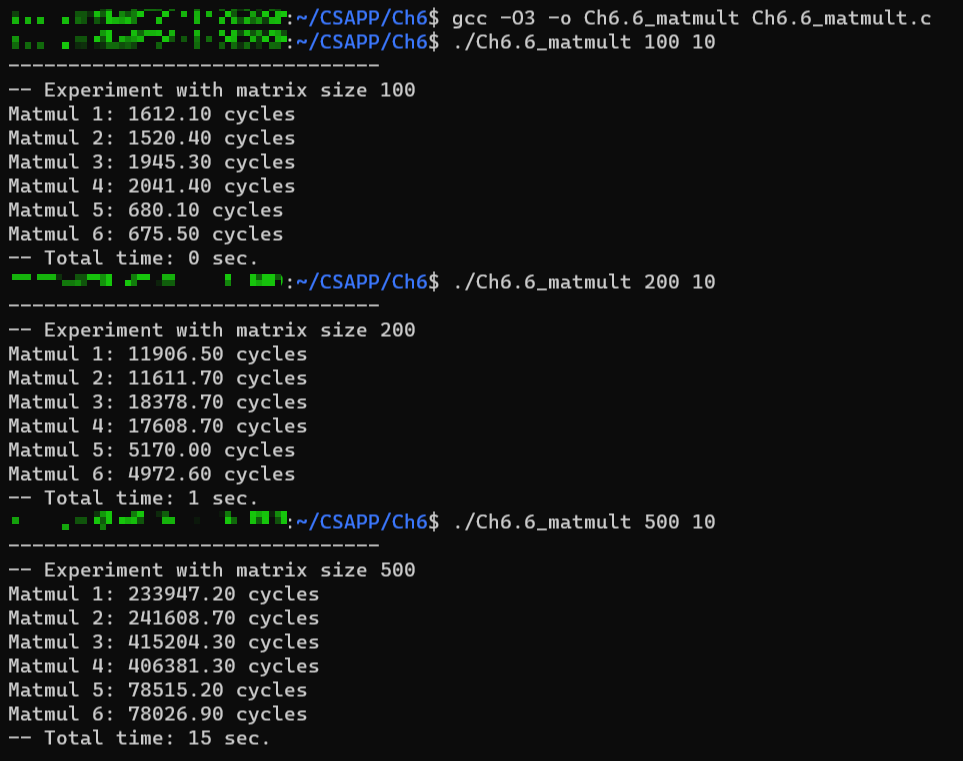
기본적으로 모든 방법에 대해서 실행 속도가 더 빨라졌는데, 이는 5, 6번 방식에 대해서는 성능 향상이 더 높은 비율로 나타났다. 다른 방법들에서는 3~5배 성능 향상이 일어난 것에 비해, 5, 6번 방식에서는 약 10배 정도의 성능 향상이 일어났다. 아직 컴파일러에 대해서 공부해본 적이 없어서 이에 대한 분석을 하지는 못했으나, locality를 잘 활용하면 컴파일 단계에서의 optimization 여지가 많아진다는 추측 정도를 할 수 있다. 우선 여기서는 locality 활용 정도에 따른 MM 연산 속도 차이를 비교하는 것이 목표였으므로, 이를 확인할 수 있었다.



